Архитектура
В процессе развития SQL Server 2000 Data Transformation Services в SQL Server 2005 Integration Services архитектура была существенно перестроена для создания более мощной и готовой к задачам извлечения, преобразования и загрузки среды. На Рисунке 28 изображена архитектура SSIS.
Рисунок 28
Архитектура совместного использования
Каждая задача в SSIS имеет набор стандартных свойств. Среда SSIS может быть расширена для управления любой пользовательской задачей, созданной другим производителем или Вами, если эта задача обладает некоторыми стандартными свойствами. Вот некоторые из существенных разделяемых свойств, которыми должна обладать каждая задача:
Disable - Если этому свойству установлено значение True, то задача запрещена и не будет выполняться. DelayValidation - Если этому свойству установлено значение True, то SSIS не будет проверять состояние свойств задачи до момента ее запуска. Это полезно в случае, когда работа идет в автономном режиме и необходимо ввести значение, которое невозможно проверить до момента развертывания пакета. По-умолчанию это свойство имеет значение False. Description - Описание производимых данным экземпляром задачи действий. По-умолчанию имеет значение . Не требует уникальных значений и должно бы давать точно описание действия задачи для тех, кто возможно в вашей операционной группе будут отслеживать действия пакета. ExecValueVariable - Содержит имя пользовательской переменной, в которую будет занесен результат выполнения задачи. По-умолчанию имеет значение <none>, что означает, что результат выполнение не будет присвоен. Fail Package on Failure - Если этому свойству установлено значение True, то выполнение всего пакета будет завершено ошибкой при ошибке выполнения данной задачи. По-умолчанию имеет значение False. Fail Parent on Failure - Если этому свойству установлено значение True, то выполнение задачи-родителя будет завершено ошибкой при ошибке выполнения данной задачи. Задачей-родителем может выступать как пакет, так и контейнер. О контейнерах мы поговорим более подробно позже. ID - Уникальный идентификатор данного экземпляра задачи. ID представляется в виде GUID и выглядит приблизительно так {R438HJI-7DN3-I8EF-NFUF-JF83AFFJ83A}. IsolationLevel - Определяет уровень изоляции транзакции, если транзакции разрешены в свойстве TransactionMode. Возможные значения: Chaos, ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Unspecified. Значение по умолчанию - Serializable. LoggingMode - Определяет тип протоколирования, применяемый для данной задачи. Возможные значения: UseParentSetting, Enabled, and Disabled. Значение по-умолчанию - UseParentSetting, что задает использование того же метода ведения протокола, что установлен для пакета или контейнера. Name - Имя задачи. По-умолчанию имеет значение <task name>. Как и редактор SSIS вы, возможно, тоже пожелаете изменить имя на более удобочитаемое. Имя задачи должно быть уникально в рамках пакета. TransactionOption - Определяет транзакционное свойство задачи. Возможные значения: NotSupported, Supported, and Required. Значение по-умолчанию - Supported, что означает поддержку транзакций в этой задаче.
Теперь, после ознакомления с основными свойствами, видимыми при выборе задачи, можно перейти к рассмотрению тех задач, что можно использовать в SSIS. Не мешало бы заметить, что задача Maintenance Plan также имеется на панели инструментов, но по-умолчанию она скрыта.
Задача Bulk Insert
Задача Bulk Insert (см. Рисунок 31) почти идентична соответствующей задаче из SQL Server 2000 DTS task. Эта задача предоставляет самый быстрый способ загрузки данных в SQL Server из плоского файла в случае, когда не нужно преобразовывать данные. Отличие этой задачи от своей предшественницы из SQL Server 2000 состоит в том, что задача SSIS использует общее соединение-источник. В SSIS в данной задаче нельзя создать файл формата, как это было возможно в DTS задаче. Теперь нужно делать это из консольной утилиты BCP.
Рисунок 31
Задача Data Flow
Те, кто хорошо знаком с SQL Server 2000 DTS не узнают задачу Data Flow из SSIS. Это очень специализированная задача и она работает отлично от других задач. Мы подробно рассмотрим ее в этой статье. Наибольшим достижением архитектуры SSIS является отказ от создания промежуточных таблиц для осуществления таких рядовых задач, как, например, агрегирование данных.
Задача Data Mining Query
Задача Data Mining Query является развитием своей предшественницы из SQL Server 2000. Как и задача из SQL Server 2000 DTS задача Data Mining Query позволяет запускать предикативные запросы к модели добычи данных в Analysis Services. Но в отличии от DTS в SSIS можно сохранить полученный результат в параметр SSIS и также у этой задачи есть входной параметр, который можно задать в виде входной переменной. Например, возможно использовать эту задачу для сохранения результатов запроса в таблицу, которую позже будет использована в потоке управления.
Задача Execute Package
Задача Execute Package (см. Рисунок 32) позволяет запустить пакет внутри родительского пакета. Версия этой задачи из SSIS обладает несколькими замечательными нововведениями. Одно из них состоит в наличии нового свойства ExecuteOutofProcess, которое при установке в True определяет запуск пакета в виде отдельного процесса с отдельной областью памяти. По-умолчанию это свойство как раз и имеет значение True. Это, конечно, требует большего количества памяти, но зато задачи выполняются лучше. Другим ключевым отличием данной версии задачи является отказ от передачи параметров в дочерний пакет. Вместо этого дочерний пакет получает доступ к родительскому пакету и может вытащить конфигурационные значения.
Рисунок 32
Задача Execute Process
Как и свой аналог из SQL Server 2000 задача Execute Process запускает пакетный файл или исполняемый модуль (см. Рисунок 33). Эта задача значительно изменилась в сторону большей гибкости настройки. Например, теперь можно задавать входные переменные, которые будут переданы в процесс, или выходные переменные, в которые будут записаны результаты выполнения. Имеется также выходная переменная для ошибок, которая будут содержать все ошибки, произошедшие во время выполнения процесса. Это позволит более гибко обрабатывать ошибки, чем это было возможно в предыдущей редакции SQL Server.
Рисунок 33
Задача Execute SQL
Задача Execute SQL(см. Рисунок 34) позволяет выполнить реляционные запросы, команды DDL или DML в соединении (и не обязательно в соединении с SQL Server). В SSIS можно хранить текст запроса в виде плоского файла или переменной в дополнение к непосредственно заданному тексту запроса. Это может быть полезно в случае, когда нужно создать процесс установки на основе внешних DDL файлов, или когда нужно создать общую функциональную библиотеку из числа внешних для SSIS SQL файлов. Как и в прошлой версии SQL Server можно легко передавать переменные в запрос и получать их оттуда. Весь результат запроса также можно целиком сохранить в переменную.
Рисунок 34
Задача File System
Эта новая задача SSIS(см. Рисунок 35) позволяет управлять файловой системой, для чего в DTS приходилось писать множество скриптов. В большинстве ETL процессов все множество извлеченных из разных мест файлов необходимо обработать, а затем заархивировать в другой каталог. Перед повторным запуском этого процесса необходимо очистить директорию, содержащую извлеченные файлы.
Задача File System поможет Вам во всех типах операций с файлами, которые были приведены в предыдущем примере ETL процесса. Эта задача может управлять директориями через операции создания, переименования или удаления. Она также может производить такие файловые операции как перемещение, копирование или удаление файлов. Все это в SQL Server 2000 требовало создания детально разработанного скрипта.
Рисунок 35
Задача File Transfer Protocol
Задача File Transfer Protocol позволяет производить файловые операции через протокол FTP. Эта задача является потомком задачи из SQL Server 2000, но обладает многими новыми свойствами. Основной жалобой на задачу File Transfer Protocol из предыдущей версии SQL Server была возможность только получения файлом с помощью FTP. В версии этой задачи в SQL Server 2005 можно по протоколу FTP отправлять, получать файлы, а также создавать директории как локально, так и удаленно. Задача также позволяет регистрировать соединения FTP с помощью FTP Connection Manager Editor так же, как любое другое соединение в SSIS (см. Рисунок 36). Ключевым новшеством является возможность выполнять FTP действия в пассивном режиме. Из-за отсутствия такой возможности в SQL Server 2000 для достижения такого же результата приходилось использовать в качестве замены запуск с помощью задачи Execute Process утилиты FTP.exe.
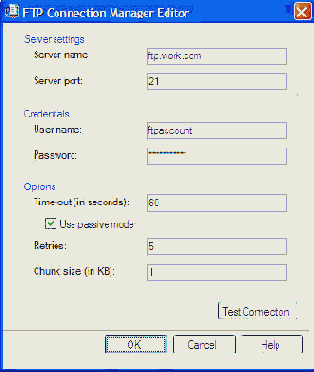
Рисунок 36
Для задачи можно установить имена удаленной и локальной директорий прямо из переменных внутри SSIS (см. Рисунок 37).
Рисунок 37
Задача Message Queue
Задача Message Queue была значительно усовершенствована по сравнению со своим аналогом из SQL Server 2000. Как и своя предшественница, эта задача может отсылать файлы данных или строковые сообщения в Microsoft Message Queue. В дополнение теперь можно отсылать в очередь и переменные SSIS. Также можно шифровать отсылаемые в очередь данные и использовать сертификаты для аутентификации.
Вся мощь задачи Message Queue (см. Рисунок 38) проявляется в случае, когда используется передача сообщений из пакета в пакет для параллельного выполнения операций. Например, каждый из SSIS может управлять своим сегментом работы, а затем, после окончания подмножества работ, один раз сообщить об этом ведущему пакету. Другая область применения очередей сообщений - это распределенная среда, в которой каждый региональный офис обрабатывает свои данные и отсылает их для обработки на корпоративный сервер через очередь сообщений. Корпоративный SSIS пакет в этом случае слушает все региональные офисы для получения от них подтверждения того, что можно начать агрегирование данных.
Рисунок 38
Задача Script
Для многих разработчиков ETL систем одной из главных причин для миграции из SQL Server 2000 в SSIS может оказаться задача Script (в SQL Server 2000 DTS известная как ActiveX Script). Новая задача Script имеет богатый дизайнерский интерфейс (см. Рисунок 39) в Visual Studio, включая IntelliSense и раскраску ключевых слов в скрипте.
Рисунок 39
Задача Send Mail
Задача Send Mail (см. Рисунок 40) позволяет отсылать сообщения электронной почты пользователям или спискам рассылки. В отличие от аналогичной задачи SQL Server 2000, она теперь использует SMTP, а не MAPI. Это означает, что теперь нет необходимости в установке Microsoft Outlook® на SQL Server для работы этой задачи. Электронное почтовое сообщение можно непосредственно напечатать, используя интерфейс чем-то похожий на Notepad. Также в качестве тела сообщения можно использовать входной файл или переменную DTS.
Рисунок 40
Задача SQL Server Analysis Services Execute DDL
Новая задача SQL Server Analysis Services Execute DDL позволяет выполнить команду DDL для создания, изменения, удаления или обработки объекта Analysis Server. Можно выполнить DDL скрипт хранящийся либо непосредственно в задаче, либо в переменной, либо во внешнем для пакета файле.
Задача SQL Server Analysis Services Processing
Задача SQL Server Analysis Services Processing является потомком задачи Analysis Services Processing из SQL Server 2000, но обладает большими возможностями. Эта задача обрабатывает кубы и измерения Analysis Services, но вдобавок к этому теперь были добавлены уровни параллелизма, позволяющие одновременно обрабатывать множество объектов. Также можно задать каким образом должна происходить обработка ошибок в ваших ключевых полях. Необходимо также отметить, что эта задача не имеет обратной совместимости с кубами и измерениями SQL Server 2000.
Задача Web Service
Новая задача Web Service служит для вызова метода Web службы. После выполнения метода можно сохранять полученные от Web службы результаты в файл или переменную. Это может быть полезно для обмена информацией с программами других производителей. Например, можно использовать Web службу для получения обновленного списка продукции с Amazon. После этого этот список можно сохранить в базу для дальнейшего использования.
Задача Web Service соединяется с Web службой с помощью HTTP Connection Manager. Он позволяет соединяться с Web сайтом через прокси или даже аутентифицироваться на сайте. В задаче Web Service можно указать использовать как внутренний, так и внешний Web сайт. Также можно задать использовать локальный файл Web Service Description Language (WSDL), содержащий список подлежащих выполнению методов. Если указано использование внешнего Web сайта, то необходимо скопировать WDSL файл на локальный диск.
Web служба, с которой происходит соединение, может требовать или не требовать входные параметры. Эти параметры можно передать в задачу с помощью переменных. Например, можно передать Web службе Amazon-а информацию о категории книг и Amazon может вернуть список новых наименований, уже готовый к отображению. Все это задается в закладке Input задачи. Получение данных конфигурируется в закладке Output, в которой задается, будут ли полученные данные сохранены в переменную или в файл. Если нужно сохранить данные в файл, то придется использовать File Connection Manager.
Задача WMI Data Reader
Windows Management Instrumentation (WMI) является одним из самых тщательно скрываемых секретов Windows. WMI позволяет управлять Microsoft Windows® серверами и рабочими станциями через интерфейс сценариев. Задача WMI Data Reader (см. Рисунок 41) позволяет взаимодействовать с этой средой посредством запросов на языке WMI Query Language (WQL). Например, можно использовать WMI для просмотра журналов Application Event Log. Возвращаемый запросом результат можно сохранить в файл или переменную для дальнейшего использования.
Рисунок 41
Задача WMI Event Watcher
Задача WMI Event Watcher (см. Рисунок 42) помогает SSIS перехватывать и реагировать на соответствующие WMI события, которые происходят в операционной системе. Например, можно указать задаче реагировать на факт записи каким-либо приложением ошибки в системный журнал событий. Либо можно заставить SSIS предпринять какие-то действия после серии событий записи файлов в какую-то директорию. Это очень распространенно в системах ETL. Как и в задаче WMI Data Reader Вы можете опрашивать WMI, используя язык запросов WQL. Текст запроса WQL может быть прочитан из файла или переменной, или может быть непосредственно задан в задаче.
Рисунок 42
Задача XML
Новая задача XML предназначена для осуществления множества различных действий с XML файлами. Она позволяет SSIS динамически изменять, объединять или создавать XML файлы по ходу выполнения. Вот некоторые варианты ее применения:
Чтение нескольких XML файлов с их последующим объединением в один. Подготовка XML файла к отчету с применением XSLT преобразования. Выборка частей XML файла с использованием XPATH. Сравнение двух XML файлов с записью разницы в XML DiffGram. Проверка XML файлов на соответствие декларации типов документа (DTD).
Это очень большое диалоговое окно меняется в зависимости от выбранного OperationType. На Рисунке 43 показан вид диалога XML Task Editor в случае, когда нужно использовать задачу для проверки XML файла. Результаты проверки можно сохранить в переменной.
Рисунок 43
Существуют также другие задачи, которые SQL Server использует в своих Maintenance Plans. Они становятся доступными при раскрытии панели задач Maintenance Plan.
Бизнес-аналитические преобразования
Преобразование Data Mining Query
Преобразование Data Mining Query выполняет прогнозирующий запрос для заданной модели анализа данных. Данное преобразование содержит построитель запросов для создания Data Mining Extensions (DMX) запросов на основе модели, преобразователь входных данных, функции прогнозирования и пользовательские выражения.
Если модели основаны на одной и той же структуре, то в одном преобразовании можно выполнить множество прогнозирующих запросов.
Преобразование Data Mining Query требует наличия соединения с базой данных Analysis Services, которая содержит структуры и модели.
Преобразование Slowly Changing Dimension
Преобразование Slowly Changing Dimension (или коротко SCD) является наиболее замысловатым из всех преобразований SSIS. Оно автоматизирует и стандартизирует обычную, но сложную задачу как отследить измененные значения в измерениях хранилища данных. К счастью данное преобразование снабжено мастером, который поможет разработчику на каждом шаге конфигурирования этого преобразования.
На первом шаге мастера SCD задаются приемники для данных измерения и бизнес ключей. Столбцы автоматически сопоставляются на основе их имен и типов, но эти сопоставления можно изменить вручную. Однако типы данных должны быть совместимы. На Рисунке 61 показан один из первых диалогов мастера, в котором производится сопоставление входных столбцов.
Рисунок 61
Следующей шаг приводит к скучной задаче по выбору того, какие столбцы измерения являются Fixed, Type I, или Type II. В этом разделе мастера выбирается то, как система ETL будет себя вести при обнаружении расхождений между источником и приемником. Например, если имеется измерение Работники, состоящее из трех столбцов Birth Date, Home Phone Number и Department, то в конкретной сфере деятельности можно по разному отслеживать изменения в каждой из этих столбцов:
Можно не ждать изменений в Birth Date (и при их появлении генерировать ошибку). Можно ожидать изменений в Home Phone Number, но не заботится о хранении истории этих изменений. Можно ожидать изменений в the Department и нуждаться в сохранении истории этих изменений.
Преобразование SCD поддерживает и такой сценарий, и другие, позволяя проектировщику выбрать подходящие бизнес правила для каждого атрибута, как это показано на Рисунке 62.
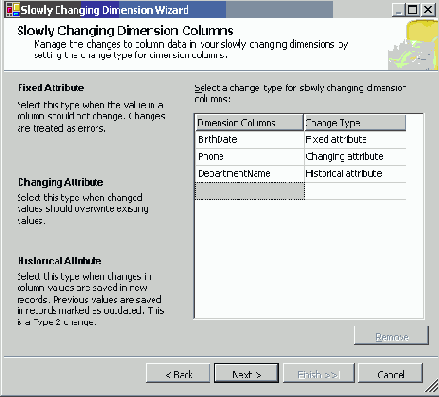
Рисунок 62
Следующие несколько шагов мастера позволяют определить, что должно происходить в случаях, когда изменяются фиксированные атрибуты, что должно происходить с оставшимися входными данными при обнаружении изменения атрибута, и как отслеживается исторические изменения атрибута (на основе флага текущий/просроченный или на основе временных меток с/по).
На последнем шаге конфигурируются производные члены (Inferred Members). Производные члены добавляются в таблицу измерений в случае, когда в соответствующей таблице фактов появляется их записи, но никакая другая информация об этом члене измерения неизвестна. Простым примером такой ситуации может быть реальный пример, когда в хранилище данных попадает транзакция о продаже товара, которого не существует базовом измерении товаров. В этом случае преобразование SCD в любом случае загружает данные в измерении (с ключевым значением из таблицы фактов). Если и когда соответствующие данные измерения будут доставлены, то произойдет обновление существующего производного члена. На Рисунке 63 показано соответствующее диалоговое окно мастера SCD.

Рисунок 63
На последнем шаге мастера можно увидеть выходные устройства (возможно не более 6), которые будут созданы. Мастер SCD создаст для каждого выходного устройства новый OLE DB источник, а также несколько других преобразований для поддержки SCD. Результат выглядит приблизительно так, как показано на Рисунке 64. Каждый из выходных устройств будет автоматически снабжено комментарием.
Рисунок 64
Заметим, что при перезапуске мастера SCD, любые изменения на экране перепишут расположение задач в рабочей поверхности.
Business Intelligence Development Studio
В Business Intelligence Development Studio SSIS пакеты создаются в рамках Integration Services проекта в виде Решения (Solution). Решение представляет собой контейнер, который позволяет одновременно работать с несколькими проектами Visual Studio, используя один набор средств для создания корпоративных, тесно интегрированных BI решений, включая SSIS решения.
Динамическое изменение свойств
Наверное, Вы уже заметили отсутствие задачи Dynamic Properties из SQL Server 2000. Этой задачи больше не существует, потому что свойства всех задач или контейнеров можно динамически изменить через переменные. Это очень полезно, если нужно запускать задачу, которая соединяется с источником данных, имя которого неизвестно до момента выполнения. На Рисунке 49 показан пример такого типа функции, в которой соединение для задачи XML задается через переменную XPathResult.
Рисунок 49
Можно использовать переменные в ограничениях приоритета для управления ходом выполнения пакета на основе проверки выполнения определенных условий. Для этого нужно дважды нажать кнопку мыши на ограничении приоритета и изменить свойство это ограничения так, как показано на Рисунке 50. Сначала нужно выбрать Evaluation Operation (свойство EvalOp) для того, чтобы происходило вычисление выражения. Можно выбрать между только вычислением выражения и одновременными успешным завершением предыдущей задачи и вычислением выражения в качестве условий продолжения выполнения. И в заключении задайте собственно выражение, которое нужно вычислять. Для указания переменной используйте символ @.

Рисунок 50
В приведенном примере проверяется, что значение переменной @NumberWidgets меньше числа 10. Если это условие выполняется, то значит полученный от поставщика XML содержит ошибки и его необходимо об этом уведомить. Если же имеется более 10 продуктов, то данные считаются правильными и их можно преобразовать в другой файл с помощью XSLT. Т.е. при выполнении пакета можно увидеть, что при правильном XML файле будет выполнена только задача XSLT to Text File. Задача же Send Mail будет проигнорирована при данном выполнении пакета.
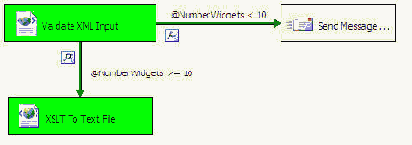
Рисунок 51
Необходимо также отметить такую возможность как установка переменных в режим только для чтения. Задание для переменной такого режима, по сути, превращает переменную в константу. Это позволяет разработчику менять значение переменной в процессе разработки пакета, но не в процессе его выполнения.
Другие окна
По ходу проектирования можно увидеть и некоторые другие окна BI Development Studio, которые также можно прикрепить, открепить, сделать видимыми, скрытыми или автоматически-скрываемыми. Это следующие окна:
Окно Task List отображает список задач-комментариев, которые разработчик может создавать наглядных целей или как напоминания для последующих разработок. Окно Error List отображает список ошибок и предупреждений, обнаруженных в пакете. При двойном нажатии мышкой на любом элементе в этом окне открывается редактор объекта, вызвавшего эту ошибку. Окно Output отображает результаты большинства событий построения или запуска пакета в BI Development Studio. Например, окно Output будет отображать все ошибки, которые произойдут при построении или развертывании пакета, или при его выполнении. Два окна Search (для отображения справки) и одно окно Results позволяют осуществлять поиск по SQL Server Books Online и отображать его результаты.
В процессе тестирования пакетов, возможно, понадобится выполнять их внутри BI Development Studio. При этом текущий режим изменится на режим выполнения. В этом режиме невозможно ничего изменять до тех пор, пока пакет не закончит выполняться. Во время выполнения появляются следующие окна:
Окно Call Stack отображает стек вызванных функций или задач. Окно Breakpoints отображает все точки остановок, заданные в текущем проекте. Окно Command служит для выполнения команд или псевдонимов непосредственно в BI Development Studio. Окно Immediate служит для отладки и вычисления выражений, выполнения команд и вывода значений переменных. Окно Locals отображает список всех локальных переменных в данной области видимости. Окно Watch позволяет отслеживать значения заданных переменных по ходу выполнения пакета. В этом окне Вы также можете непосредственно изменить значения read/write переменных.
Источник данных
Источник данных содержит в себе информацию, которая необходима SSIS для соединения с OLE DB совместимыми системами, например, с SQL Server, Oracle, DB2, или Microsoft Access. Можно также создать соединения с менее распространенными источниками данных, такими как Analysis Services, источниками, основанными на XML, или Microsoft Directory Services. Источники данных можно использовать как во множестве пакетов в рамках проекта Business Intelligence Development Studio, так и в одном единственном пакете. Соединение очень просто создается с помощью диалога Connection Manager, как это показано на Рисунке 29. В этом диалоговом окне Вы можете создать соединение почти для любого типа источника данных. На рисунке показано создание источника данных SQL Server OLE DB. Другие типы соединений могут различаться по внешнему виду и свойствам.
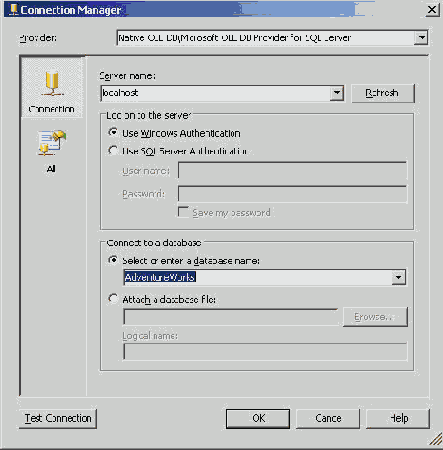
Рисунок 29
Создание соединения в проекте Business Intelligence Development Studio не означает то, что действительно происходит соединение с источником данных. Соединение всегда неактивно до тех пор, пока действительно не начнется его использовать в пакете. Это дает прекрасную возможность разработать большую часть SSIS пакета, находясь далеко от вашей базы данных, например, в аэропорту, а затем развернуть пакет и все его соединения на SQL Server.
Источник DataReader
Источник DataReader является соединением ADO.NET в том виде, как его можно видеть в .NET Framework при использовании интерфейса DataReader в приложении для соединения с базой данных. Источник DataReader позволяет создать соединение с управляемым источником данных и передавать в него SQL запросы. Результаты этого запроса могут быть использованы позже в потоке данных. Только всегда помните, что при работе с этим источником, нужно будет вводить текст SQL запроса вручную и не будет инструментов для построения запросов как в других источниках.
Источник Flat File
Источник Flat File представляет соединение с нереляционным источником данных. Источником Flat File обычно являются файлы с разделителем (запятой или табуляцией), но это могут быть и файлы со столбцами фиксированного размера. Конфигурируется источник Flat File точно так же, как и источник OLE DB. После добавления источника на панель потока данных, он указывается Connection Manager-у в качестве соединения к плоскому файлу. После этого можно перейти к закладке Columns для определения списка тех столбцов, которые нужно представить в потоке данных. Все установки плоского файла такие, как тип разделителя, устанавливаются в Flat File Connection Manager.
Источник OLE DB
Источник OLE DB, скорее всего, будет самым часто используемым элементом из Панели Инструментов. Как и в SQL Server 2000 DTS соединение OLE DB подходит для любого реляционного источника данных, как SQL Server, Access, Oracle, или DB2 и др. В SQL Server 2005 при создании источника OLE DB нужно будет указать, какое соединение следует использовать. При этом можно указать на представление источников данных (DSV) так, как если бы он был в обычной базе данных. На Рисунке 52 можно видеть, что курсор мыши указывает на Transactions DSV вместо главного соединения Adventure Works, которое содержит все неизмененные объекты.
Рисунок 52
После выбора источника данных (см. Рисунок 53) можно перейти к закладке Columns и выбрать то подмножество столбцов, которое необходимо будет передать следующему элементу данных. Делается это путем отметки тех столбцов, что нужно сделать доступными в потоке данных. При желании также можете переименовать столбцы, которые будут представлены в потоке данных, через изменение свойства Output Column.
Рисунок 53
Источник Raw File
Источник Raw File есть специальный тип плоского файла, который оптимизирован для быстрого использования его в SSIS. Источник Raw File требует предварительного создания приемника Raw File. В источник Raw File невозможно добавить столбцы, но, как и в любом другом источнике, ненужные столбцы можно удалить. Т.к. источник Raw File требует минимальных затрат при трансформации, то он может загружать данные гораздо быстрее источника Flat File. Но достигается это за счет малой гибкости.
Источник XML
Источник XML позволяет Вам сделать XML файл или элемент данных источником внутри процесса обработки данных. После добавления этого элемента данных можно или жестко задать XML файл через свойство XML location (см. Рисунок 54), или указать, что положение файла будет браться из переменной. Также можно указать, что XML данные могут и сами находиться в переменной. Данный источник полезен в связке с задачей Web Service или с задачей XML. После задания элемента данных для файла XML нужно создать XML Schema (XSD) файла либо выбирая кнопку Generate XSD, либо указывая на существующий XSD файл. В остальном данный источник похож на другие источники, где можно отфильтровать те столбцы, которые не хочется видеть в дальнейшей обработке.
Рисунок 54
Источники
Источник задает расположение ваших исходных данных в процессе обработки. Источники обычно создаются в Connection Manager. Применяя для создания источника Connection Manager, можно повторно использовать их во всем пакете и случае необходимости поменять их параметры только в одном месте. В SQL Server 2000 источник и приемник данных были в действительности именно соединениями.
Элементы потока данных
Также как поток управления контролирует ход выполнения пакета, так и поток данных контролирует преобразования данных. Почти все, что хоть как-то работает с данными, попадает в категорию потока данных. Для создания потока данных нужно в своем потоке управления добавить задачу Data Flow.
Самым большим достижением потока данных является то, что все операции с данными происходят в памяти. Например, можно взять плоский файл, содержащий информацию заказов, вычислить по нему суммы, упорядочить и записать в другой плоский файл без необходимости, как нужно было прежде, записывать промежуточные результаты в SQL Server.
Элементы потока управления
Поток управления есть компонент SSIS, который координирует выполнение и условные переходы в SSIS пакете. Поток управления содержит задачи, которые осуществляют какую-то часть общей работы, например, отсылают файл по FTP, и ограничения, которые соединяют различные задачи в логическом порядке.
Компоненты источника данных
Основная область применения SSIS заключается в выборке данных из источника данных, их преобразования и загрузки в другое место. Источники данные представляют собой соединения, которые можно использовать как в виде источников, так и приемников.
Компоненты управления ошибками
Управление ошибками в SSIS значительно более мощное, чем в DTS 2000. Пакет может управлять ошибками многими различными способами, используя несколько новых методов. Можно легко отреагировать на ошибку или проигнорировать ее, проверяя тип ошибки, или время и место возникновения ошибки. SSIS позволяет разработчику качественно обрабатывать как процедурные ошибки, так и ошибки данных.
Процедурные ошибки
В SSIS, как и в DTS 2000, существует ограничение приоритета OnFailure, которое позволяет при ошибке выполнения задачи графически направить поток выполнения к задаче, предназначенной для обработки ошибки. Также можно проигнорировать ошибку, если изменить проверку результата ограничения на OnCompletion. В DTS 2000 это означало, что пакет все равно сообщит о своем неудачном завершении в вызвавшее его приложение (например, SQL Agent), не смотря на то, что возникшая ошибка могла быть второстепенной и восстановимой.
SSIS же предлагает разработчику более гибкий подход в лице нового свойства по имени ForceExecutionResult. Для этого свойства можно задать значение None, Success, Failure, или Completion. При выборе значения Success или Completion пакет будет всегда рапортовать об успешном завершении задачи, невзирая на то, что случилось на самом деле.
SSIS также может перехватывать события OnError и OnTaskFailed для любого элемента потока управления, включая задачу потока данных. Используя обработчики ошибок, можно упростить процесс создания пакета и получить преимущества переменных на уровне события. В зависимости от конкретных потребностей можно создать один обработчик ошибок для событий OnError и OrTaskFailed пакета.
Ошибки данных
В SSIS возможно обрабатывать ошибки или несоответствия данных непосредственно в редакторе потока данных. Ошибки данных могут возникать по многим причинам, включая противоречия в источнике данных и программные ошибки. Однако SSIS может пропустить, отказать или перенаправить проблемные данные без генерации ошибки пакета. SSIS может на ходу починить и обработать данные заново, или записать их на диск и обработать позднее. И проделать все это можно в редакторе Data Flow.
Например, если добавляется запись, которая нарушает ограничение первичного или ссылочного ключа, то эта запись может быть помещена в таблицу ошибок для более поздней обработки. Как это показано на Рисунке 65.

Рисунок 65
Для задач преобразования данных обработка ошибок может заключаться в создании дополнительного приемника данных (типа OLE DB, Flat File, или Raw File), в который будут передаваться ошибочные записи. При нажатии кнопки мыши на приемнике трансформации появится красная стрелка, которая соответствует ограничению приоритете OnFailure. При перетаскивании этой стрелки к новому приемнику появится диалоговое окно Error Dispositions, как показано на Рисунке 66.
Рисунок 66
В этом диалоге можно задать автоматическую обработку ошибок данных двух разных типов - критические ошибки (например, нарушение Первичного Ключа) и ошибки усечения. Эти ошибки можно пропустить, отказать или перенаправить в альтернативный приемник. В данном выше примере любые критические ошибки, возникшие в столбцах Col1, Col2, или Col3, будут переданы в источник данных по имени Error, но разрешена передача далее усеченных данных. В приведенной ниже таблицы описаны возможные действия.
| Fail Component | Вся задача потока данных завершается при возникновении любой серьезной ошибки. |
| Ignore Failure | Задача потока данных завершается успешно, невзирая на то имели ли место ошибки или нет. |
| Redirect Row | Вызвавшая ошибку запись перенаправляется в соответствующий приемник данных. |
Рисунок 67
И напоследок нужно запретить свойство Fast Load для преобразования приемника данных. Если это свойство разрешено, то SSIS будет применять пакетное добавление записей, при котором ошибки уровня записи будут недоступны. Такое решение приведет к некоторой потере производительности, но это необходимая "цена" за возможность перенаправить все ошибки.
Компоненты управления событиями
Внутри SSIS архитектуры существует расширенная концепция событий и обработчиков событий. В предыдущих версиях доступ к событиям уровня пакета достигался с помощью программного запуска пакета из среды Visual Basic или Microsoft Visual C++®. В SSIS же события пакета доступны в пользовательском интерфейсе и для каждого из них можно спроектировать его собственный обработчик с целью создания сложных потоков обработки. Фактически для каждой выполняемой контейнерной задачи в среде работы пакета существуют ее события. Ниже приведен список обработчиков событий, которые существует при выполнении пакета:
| OnError | Событие возникает при появлении ошибки. |
| OnExecStatusChanged | Это событие возникает, когда статус выполнения объекта меняет свое значение с True на False или наоборот. |
| OnInformation | Это событие возникает, когда объект готов рапортовать о чем-либо. |
| OnPostExecute | Это событие возникает сразу после того, как объект завершает выполнение. |
| OnPostValidate | Это событие возникает сразу после того, как объект был протестирован в режиме редактирования. |
| OnPreExecute | Это событие возникает непосредственно перед запуском объекта. |
| OnPreValidate | Это событие возникает, когда начинается процесс проверки объекта. |
| OnProgress | Это событие возникает, когда изменяется измеряемое состояние хода выполнения. |
| OnQueryCancel | Это событие возникает непосредственно перед тем, как процесс готов к завершению. |
| OnTaskFailed | Это событие возникает в том случае, если выполнение задачи завершилось неудачей. |
| OnVariableValueChanged | Это событие возникает в том случае, когда меняется значение переменной, для которой задано свойство RaiseChangeEvent. |
| OnWarning | Это событие возникает в том случае, когда генерируется предупреждение. |
При таком обилии обработчиков событий архитектура событий предлагает простые и стандартизированные решения задачи управления. Например, общую систему обработки ошибок и отчётности на уровне пакета или контейнера. ( Обработчики событий детально писаны в Server 2005 Books Online). В дополнение широта модели событий в общей архитектуре такова, что позволяет и более продвинутые решения с обработкой событий на самых низких уровнях. Такие низкоуровневые решения можно встраивать в задачи и потока управления и потока данных для поддержки самых малых частей систем ETL.
Компоненты ведения протокола и аудита
Ведение протокола в SSIS было значительно изменено для большей поддержки более низких уровней доступных для протоколирования. К существовавшим ранее возможностям ведения протоколирования на уровне пакета и задачи добавилась возможность задать различные параметры ведения протокола для отдельных задач и пакета. Новая система ведения протоколов также позволяет создание элементов протоколирования для каждого события задачи или пакета.
Это означает, что можно выбрать ведение протокола для тех случаев, когда задача генерирует ошибку, или предупреждения, или когда изменяется значение переменной.
Можно разрешить ведение протокола для пакета при нажатии правой кнопки мыши в редакторе потока данных и выборе Logging или выбрав пункт Logging в меню DTS. По-умолчанию, ведение протокола не включено, поэтому для его конфигурации нужно добавить хотя бы одного провайдера на уровне пакета. На Рисунке 68 можно увидеть три доступных пакету провайдера:
Рисунок 68
После того, как ведение протокола включено, можно указать вести протокол для любой задачи и определить параметры протоколирования. Обратите внимание на кнопку Advanced в закладке Details. При нажатии на неё можно увидеть полный список всех событий и атрибутов, которым можно задать ведение протокола (см. Рисунок 69).
Рисунок 69
События, для которых возможно ведение протокола, на уровне задачи являются теми же событиями, которым можно задать обработку событий. Однако есть и несколько дополнительных событий:
OnPipelinePostEndOfRowset OnPipelinePostPrimeOutput OnPipelinePreEndOfRowset OnPipelinePrePrimeOutput OnPipelineRowsSent Diagnostic
Событие OnPipeline разрешено только для событий, генерируемых в задачах потока данных. Событие Diagnostic предназначено для протоколирования текущего окружения и диагностической информации.
Для каждого из этих событий DTS поддерживает пять методов ведения протоколов, или другими словами провайдеров: Text File, SQL Profiler, SQL Server, Windows Event Log, и XML File.
После того, как выбрано, для каких задач и событий вести протоколы, нужно выбрать какие данные будут записываться в протокол. Можно использовать следующие данные:
Computer Operator SourceName SourceID ExecutionID MessageText DataBytes
Другими словами существуют без преувеличения тысячи разных комбинаций для конфигурации пакета. Если параметры ведения протокола сконфигурировали по Вашему усмотрению, то можно сохранить их во внешний файл, а потом загрузить обратно. Это позволяет иметь различные конфигурации ведения лога для процессов разработки, тестирования и эксплуатации, если эти процессы нуждаются в разных уровнях ведения логов.
И напоследок отметим, что SSIS поддерживает создание пользовательских провайдеров ведения протокола, в которых можно реализовать тот функционал, который лучше всего подходит под Ваши потребности. За более подробной информацией обратитесь к SQL Server Books Online.
Контейнеры
Контейнеры являются базовыми компонентами архитектуры потока управления и объектной модели SSIS. Они помогают логически группировать задачи в отдельные рабочие блоки или создавать сложные условия. Существует четыре типа контейнеров: TaskHost, Sequence, ForLoop, ForEachLoop. Они позволяют:
Сгруппировать ограничения приоритета так, чтобы группа задач обязательно была успешно (или неуспешно) выполнена перед запуском другой задачи. Циклически выполнять последовательность задач до достижения определенного условия. Циклически выполнять последовательность задач для каждого элемента какой-либо коллекции.
Контейнер Task Host
Контейнер TaskHost является основным контейнером для единичной задачи. Если не указано для задачи другого контейнера, то она будет помещена в контейнер TaskHost. Архитектура SSIS предоставляет задаче переменные и обработчики событий именно через контейнер TaskHost.
Контейнер Sequence
Ограничения последовательности управляют потоком подмножества пакета и помогают логически поделить пакет на более мелкие управляемые части. Вот примеры того, где можно использовать Sequence контейнер:
Запретить функциональную область пакета. Ограничить область видимости переменных рамками контейнера, а не пакета. Повысить управляемость путем задания свойств сразу всему контейнеру вместо задания их для каждой задачи по отдельности.
Контейнер Sequence выглядит точно также как и другие задачи в Controller Flow. После перетаскивания контейнера Sequence из Панели Инструментов, можно поместить в него задачи. На Рисунке 44 показан пример из двух контейнеров. Левый контейнер является контейнером Sequence, который содержит две задачи и должен завершиться успешно для того, чтобы смог запуститься контейнер For Each Loop. Последний контейнер мы сейчас и рассмотрим более подробно.
Рисунок 44
Контейнер For Loop
Контейнер For Loop организует цикл по всем задачам до достижения заданного условия. Например, как показано на Рисунке 45, задача Send Mail выполняется четыре раза. Хотя этот пример может показаться неактуальным, он показывает мощь контейнера For Loop. Данный контейнер может содержать также и другие контейнеры для создания вложенных циклов.

Рисунок 45
Три основных элемента задачи изображены на Рисунке 46. Первый из них это параметр IntExpression, с помощью которого задается начальное значение параметра. Параметр EvalExpression определяет условие, которое служит сигналом механизму выполнения SSIS для выхода из контейнера For Loop. И, наконец, необязательное свойство AssignExpression задает шаг приращения того параметра, что был ранее задан в свойстве InitExpression.
Рисунок 46
Наиболее практичным способом использования данного контейнера является циклическое выполнение задачи WMI Event Watcher или задачи Message Queue для поиска событий. Например, в задаче Message Queue можно ожидать пока группа пакетов другого сервера не зарегистрирует факт завершения работы, чтобы пакет смог продолжить выполнение следующего набора задач. Для этого, можно организовать цикл по задаче Message Queue с помощью контейнера For Loop и ждать пока задача Message Queue не запишет в переменную SSIS значение, которое будет означать успешное завершение других пакетов. Затем с помощью ограничения приоритета On Success можно направить выполнение пакета по следующей ветке.
Контейнер Foreach Loop
Наиболее необычным из новых контейнеров является Foreach Loop. Этот контейнер может сберечь разработчикам традиционных DTS больше всего времени. Контейнер Foreach Loop позволяет разработчикам SSIS организовать цикл по коллекции файлов, записям набора Microsoft ActiveX® Data Objects (ADO), переменным и выполнить последовательность задач.
Очень часто примеры того, как можно использовать контейнер Foreach Loop, можно почерпнуть в процессах ETL. Там, где создавался пакет для цикла по всем файлам директории и запуска для каждого извлеченного файла дочернего пакета. В SQL Server 2000 DTS все это требовало изрядного количества кода в задаче ActiveX Script. В SSIS же все, что нужно, это создать контейнер и задать ему свойство Enumerator в For Each File Enumerator, как это показано на Рисунке 47. Затем в разделе Enumerator Configuration указывается каталог, по которому будет проходить цикл и тип файла. Если нумератор обнаружит файл, то он может присвоить его имя в соединение или переменную SSIS, что можно использовать для динамического запуска пакета внутри цикла.
Рисунок 47
Отображаемая на закладке Collection информация меняется в зависимости от значения свойства Enumerator. Вот некоторые из возможных значений нумератора:
For Each File Enumerator организует цикл по коллекции файлов для которых нужно выполнить какие-либо действия. For Each ADO Enumerator организует цикл по коллекции записей набора ADO. Этот набор должен храниться в переменной пакета. For Each From Variable Enumerator организует цикл по переменным пакета. For Each NodeList Enumerator организует цикл по XML файлу и требует XPATH информацию. For Each SMO Enumerator организует цикл по объектам SQL Server любого уровня.
В процессе выполнения цикла по коллекции контейнер будет присваивать значение из коллекции задаче или соединению внутри контейнера, как это показано на Рисунке 48. Также можно поместить это значение в переменную.

Рисунок 48
Логическая группировка задач
Еще одной полезной особенностью Редактора Control Flow является группировка задач. Если необходимо графически свернуть несколько задач в одну, то можно выбрать эти задачи и в появившемся при нажатии на правую кнопку мыши меню выбрать операцию Group. Это приведет к созданию логического контейнера содержащего выбранные задачи. Единожды созданную группу можно сворачивать в одну задачу, что очень полезно в сложных пакетах. В отличие от контейнерных объектов группировка никак не влияет на выполнение, протоколирование, область видимости переменных или на что-нибудь еще. Она служит только для целей графического отображения.
На Рисунке 20 показан SSIS пакет, который перед загрузкой данных должен очистить таблицу и файл в системной директории. Однако мы пожелали логически сгруппировать эти две задачи в один контейнер по имени Cleanup.
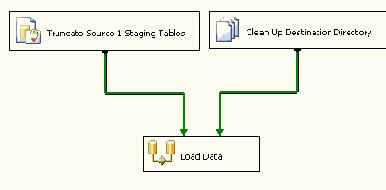
Рисунок 20
Сначала нужно выбрать задачу по имени Truncate Source 1 Staging Tables, затем другую задачу. Это можно сделать, либо удерживая нажатой клавишу Crtl и поочередно нажимая кнопку мыши на каждой задаче, либо выделив мышкой всю область, включающую обе задачи. Теперь можно нажать правую кнопку мыши для доступа к контекстному меню и выбрать в нем пункт Group, как показано на Рисунке 21.
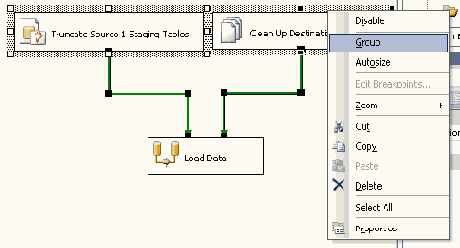
Рисунок 21
SSIS создаст из этих двух задач одну логическую группу по имени Groupbox. Можно нажать кнопку мыши на имени группы и поменять его на Clean Up, как это показано на Рисунке 22. Также можно изменить ее размер, чтобы он наилучшим образом подходил для пакета.

Рисунок 22
Мастера SSIS
Мастер Импорта/Экспорта (Import/Export Wizard) из SQL Server 2000, который использовался администраторами и разработчиками для автоматизации задач по периодическому перемещению или копированию данных, претерпел изменения.
Мастер Импорта/Экспорта
Самым простым и востребованным из мастеров в DTS 2000 без сомнения был мастер Импорта/Экспорта. Он позволял администраторам, разработчикам и простым неопытным пользователям очень быстро, без написания программ и больших проблем переместить данные источника одного типа в приемник другого типа. Мастер также представлял собой некую стартовую точку для изучения вопроса о создании и проектировании DTS пакетов. Мастер Импорта/Экспорта из SQL Server 2005 в дополнение к тем же свойствам приобрел следующие усовершенствования:
Улучшенные возможности управления плоским файлом, как для источника, так и для приемника данных. Возможность просмотра данных в реальном времени. Оптимизация обработки при использовании большого количества таблиц и представлений. Возможность создания новой базы непосредственно из Мастера.
На Рисунке 1 показан первый диалог мастера, а следующие далее рисунки отображают диалоги следующих шагов мастера.
Рисунок 1
Наряду с новыми возможностями пользовательский интерфейс был также изменен, с целью экономии времени тех, кто часто использует этот мастер.
Одним из наиболее приятных усовершенствований является возможность создания базы-приемника непосредственно в мастере. Если в DTS 2000 пользователь должен был прервать процесс импорта/экспорта, вернуться в Enterprise Manager и создать базу, то теперь администратор может создать и сконфигурировать новую базу прямо в диалоге. Как показано на Рисунке 2.
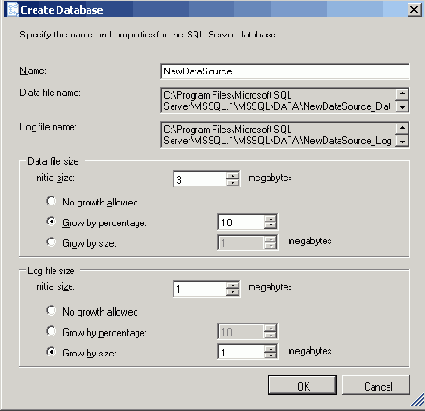
Рисунок 2
Отображаемый после создания, сохранения или выполнения пакета диалог состояния претерпел существенные изменения по сравнению с DTS 2000. На Рисунке 3 показан диалог с информацией о ходе выполнения.
Рисунок 3
После того, как пакет был сохранен в SQL Server или в файл, его можно открыть. На Рисунке 4 изображена часть потока управления пакета.

Рисунок 4
В отличии от пакета, созданного Мастером Импорта/Экспорта из DTS 2000, все команды по созданию таблиц (CREATE TABLE DDL) помещаются в первую задачу ExecuteSQL, которая получает имя Preparation SQL. Передача же данных в действительности происходит в задаче Pipeline после создания таблиц.
После открытия задачи Data Flow становятся видимыми компоненты потока данных. На Рисунке 5 мы видим, что при выборе экспорта трех таблиц мы получили соответственно три источника и три приемника данных (по паре для каждой таблицы).
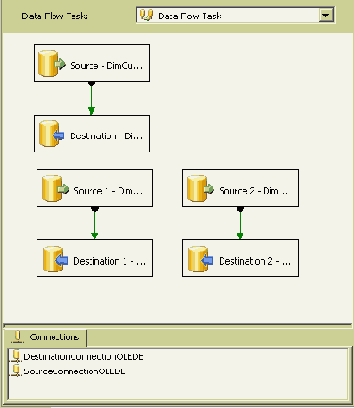
Рисунок 5
Как и в SQL Server 2000 Мастер Импорта/Экспорта является хорошими пособием для начального изучения всего того нового, что на самом делается внутри SSIS.
Менеджеры соединений
Закладка в нижней части Редактора Control Flow содержит все соединения данных, которые могут использовать как поток управления, так и поток данных. На эти соединения можно ссылаться как на источники, так как и на приемники в любых операциях потока данных. Они могут быть соединениями, как с реляционной базой данных, так и с базой Analysis Services, или плоским файлом, или любым другим источником данных.
При создании нового пакета он не имеет соединений. Можно создать соединения, если нажать правую кнопку мыши в области Connections и выбрать подходящий тип соединения, как это показано на Рисунке 24. Существует несколько типов соединений, которые мы рассмотрим далее в данной статье. После того, как соединение создано, его можно переименовать для соблюдения принятых правил именования или с целью лучшего описания характера этого соединения.

Рисунок 24
Настройка пользовательского интерфейса
Одним из лучших качеств BI Development Studio является то, что ее пользовательский интерфейс может быть полностью настроен под желания индивидуального пользователя. Все перечисленные выше окна можно открепить и переместить куда угодно. Их также можно прикрепить во многих местах экрана и сгруппировать с другими окнами для отображения в виде закладок. Для окон можно выбрать режим автоматического сокрытия. В этом случае если Вы прекращаете использовать такие окна, то они исчезают из вида до тех пор, пока они Вам снова не понадобятся.
Новые возможности SQL Server 2005 Integration Services
Mark Chaffin, Brian Knight, Microsoft
Апрель 2005
Резюме:
Данная статья представляет собой практическое руководство для изучения новых особенностей платформы SQL Server Integration Services (SSIS).
Авторские права
Этот документ является предварительным и может быть существенным образом переработан до финального коммерческого релиза программного продукта
Информация, содержащаяся в этом документе, представляет текущую точку зрения корпорации Microsoft на обсуждаемые вопросы на момент публикации. Поскольку Microsoft должна реагировать на изменяющиеся условия на рынке, документ не следует рассматривать как обязательство со стороны Microsoft; корпорация Microsoft не может гарантировать, что вся представленная информация сохранит точность после даты публикации.
Настоящий документ предназначен только для информационных целей. MICROSOFT НЕ ДАЕТ В ЭТОМ ДОКУМЕНТЕ НИКАКИХ ЯВНЫХ ИЛИ ПОДРАЗУМЕВАЕМЫХ ГАРАНТИЙ.
Если не оговорено противное, используемые в этом документе названия компаний и продуктов, имена людей, действующие лица и/или данные являются вымышленными, и их ни в коей мере не следует связывать с какими-либо реальными людьми, компаниями, продуктами или событиями. copy 2005 Microsoft Corporation. Все права защищены.
Microsoft, IntelliSense, Visual Basic, Visual Studio и Windows Server являются товарными знаками или охраняемыми товарными знаками корпорации Майкрософт в США и/или в других странах.
Другие упоминаемые здесь названия продуктов или компаний могут представлять собой торговые марки соответствующих владельцев.
Об авторах
Brian Knight обладает званиями SQL Server MVP и MCDBA. Он является одним из основателей ресурса SQLServerCentral.com и работает в Allstate в качестве менеджера по развитию. Brian является автором нескольких книг, включая Professional SQL Server 2000 DTS и SQL Server 2000 for the Experienced DBA. Ему можно писать на адрес bknight@sqlservercentral.com.
Mark Chaffin работает действующим директором североамериканского филиала в области бизнес-аналитики компании Avanade.
Эта компания является сертифицированным партнером Microsoft со статусом Gold Certified в области бизнес-аналитических систем на платформе Microsoft® . Он был ведущим разработчиком многих клиентских корпоративных решений во многих областях, включая розничную торговлю, торговля потребительскими товарами, здравоохранение, финансы, маркетинг, банковское дело, технологии, спорт и развлечение. Он имеет опыт в областях добычи данных, архитектуры транзакционных приложений, архитектуры Интернет приложений, администрирования и проектирования баз данных. Он также является соавтором книги SQL Server 2000 Data Transformation Services издательства Wrox Press и автором многих статей по бизнес-интеллекту, SQL Server, DTS и Analysis Services. Также он часто выступает как докладчик на конференциях PASS и TechEd Microsoft и SQL Server.
И Brian и Mark являются ведущими авторами готовящейся к изданию книги SQL Server 2005 Integration Services (издательство Wiley Press).
| Назад | Содержание |
Ограничения приоритета
Ограничения приоритета управляют ходом выполнения Вашего SSIS пакета на основе заданных условий. В SQL Server 2005 Integration Services ограничения приоритета были существенно расширены за счет возможности организации циклов.
Окно Properties
По-умолчанию окно Properties отображается в нижнем правом углу BI Development Studio. Это окно появляется в том случае, если Visual Studio используется для создания пакета в BI Development Studio и выбирается рабочая поверхность, задача или объект. Окно Properties является контекстно-зависимым, т.е. его содержимое изменяется в зависимости от выбранного элемента. Для проверки этого можно выбрать нажатием мышки главное рабочее окно. Окно Properties отобразит такую же страницу свойств пакета, как показано на Рисунке 11.
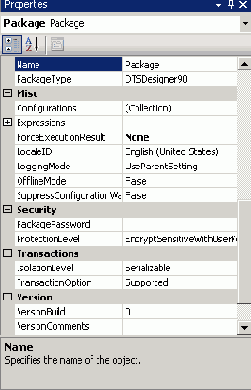
Рисунок 11
Окно Solution Explorer
Чтобы начать работу в BI Development Studio, нужно сначала открыть или создать новый проект или решение. Если начинать работу с создания проекта Integration Services, то автоматически будет создано решение, содержащее новый SSIS проект. Также можно создать и пустое решение, в которое позднее можно будет добавить различные проекты, такие как SSIS проект вместе с проектом Analysis Services, или проектом Reporting Services, или даже с Visual Basic. NET проектом. Связка решение/проект позволяет разработчику группировать разные рабочие элементы для совместной их разработки и тестирования.
На Рисунке 8 показаны существующие в BI Development Studio организационные возможности. В данном случае сгруппированы три ETL проекта и один Analysis Services проект. Т.к. среда разработки интегрирована в Visual Studio, то одновременно множество разработчиков могут работать над всеми частями решения.
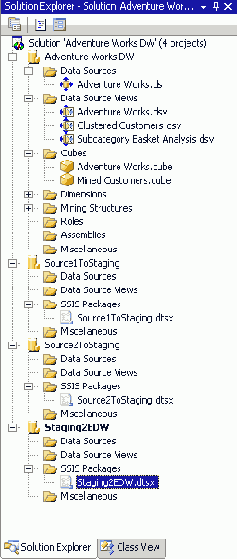
Рисунок 8
Однако можно увидеть пример отображенный на Рисунке 9, если нажать правую кнопку мыши на каталоге SSIS Packages и выбрать пункт меню New SSIS Package.

Рисунок 9
Файл с расширением .dtsx является ядром пакета, в котором хранится вся информация. Решения и проекты, которые содержат файлы .dtsx, используют его только для организационных преимуществ и группировок. Можно открыть .dtsx файл, если создать новый SSIS проект и добавить в него существующий .dtsx файл.
Отладка
После создания SSIS пакета и разрешения ошибок его построения Вы сталкиваетесь с проблемой отслеживания ошибок в логике или данных. Эту проблему можно решать непосредственно в BI Development Studio, используя инструменты отладки самой Visual Studio. Эти инструменты позволяют задавать точки остановок для задач или событий, проверять и изменять переменные, анализировать стек вызова, производить сквозную отладку множества пакетов и языков (включая хранимые процедуры SQL) и изучить пакет вдоль и поперёк.
Средства отладки поддерживают пошаговое выполнение, точки остановки и отладку скриптов. Можно просматривать и/или изменять данные (до или после преобразования) непосредственно по ходу преобразования. Также можно просматривать тестовые данные источников и добавлять туда значения.
Точки остановок
Среда разработки поддерживает точки остановок для каждого события задачи. Для создания новой точки , нужно выбрать нужную задачу, нажать на ней правую кнопку мыши и выбрать из всплывающего меню пункт Edit Breakpoints. Можно сконфигурировать точку, как на первое срабатывание события, так и на любое указанное по счету. На Рисунке 70 показано, что прерывание произойдет только тогда, когда количество событий OnPreExecute станет равным двум.
Рисунок 70
Панель инструментов
Внимательно взглянув на BI Development Studio, можно также увидите окно по имени Toolbox, расположенное, скорее всего с левой стороны. Панель инструментов поделена на множество закладок, количество которых зависит от типа проекта, с которым в данный момент идет работа. Она также содержит много закладок, которые не относятся к SSIS проектам. Только две закладки применимы к SSIS проектам - Control Flow Items и the Data Flow Items. Все задачи и объекты, доступные в Панели инструментов мы рассмотрим ниже. В зависимости от текущего экранного разрешения можно также увидеть рядом с именами закладок две стрелки прокрутки. Если на экране не хватает места для отображения всех задач, то с помощью этих стрелок прокрутки можно передвигаться по списку вверх и вниз (см. Рисунок 10).

Рисунок 10
Возможно, в процессе использования Панели инструментов захочется настроить её, удалив некоторые задачи или закладки. При нажатии правой кнопки мыши на отдельной задаче можно увидеть меню быстрого вызова, которое позволит настроить отображение через добавление/удаление закладок и добавление/удаление/переименование элементов. Также можно поменять порядок следования элементов или закладок, перетягивая их мышкой с одного места на другое.
Переменные
Одно из вспомогательных в режиме редактирования окон отображает список переменных. Переменные используются в пакете для передачи значений между задачами и для динамического управления ходом выполнения пакета. Окно Variables (см. Рисунок 25) отображает имя, область видимости, тип данных и значение переменной.
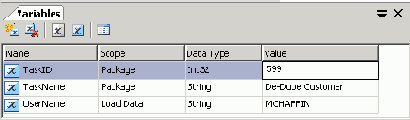
Рисунок 25
Главное отличие глобальных переменных в DTS 2000 и переменных в SSIS заключается в том, что в SSIS переменные имеют область видимости. Область видимости позволяет привязывать переменные к пакетам и объектам, более определенным и управляемым способом.
Каждый пакет, задача, обработчик событий и контейнеры For Loop, For Each Loop, и Sequence могут иметь свои переменные, которые доступны только в соответствующей им области видимости. Это означает, что и в задаче Execute SQL и в контейнере For Loop можно одновременно объявить переменные с одинаковыми именами, ссылаться на которые, однако сможет только соответствующий объект.
Более подробно об использовании переменных рассказано в последующих разделах.
Представление источника данных
Представление источника данных (data source view - DSV) это его логическое отображение одного или нескольких источников данных. Проще говоря, это коллекция объектов базы данных (таблиц, представлений и хранимых процедур), которые логически сгруппированы и могут быть использованы во всем проекте. Представления источника данных можно повторно использовать в Analysis Services и в Report Builder.
Представления источника данных очень похожи на реляционные представления SQL Server и являют собой логическое представление модели данных. Это особенно полезно в сложных схемах, например, в системах планирование и управление ресурсами предприятия (ERP) вроде SAP, Seibel, или Peoplesoft. В порядке вещей у производителей подобного программного обеспечения считается правильным разрабатывать это программное обеспечение так, чтобы оно работало в рамках любой компании. Поэтому их огромные модели данных содержат, возможно, тысячи объектов. Столбцы в таких ERP системах имеют очень путаные имена, например, A54210. В такой среде разработке нужно стать поистине экспертом модели данных и тратить много ценного времени на перевод имен столбцов и бизнес-имена. Разумеется, за счет времени отведенного для основной работы.
Как и в случае с системой ERP представления источников данных (DSV) предлагают способ для разделения тысяч объектов на логические группы, например, Бухгалтерия (Accounting), Кадры (Human Resources), и Оборудование (Inventory). И что важнее всего, что это дает возможность назначить каждому столбцу понятное имя, т.е. сразу же отказаться от сбивающих с толку имен наподобие A54210 и сделать их доступными в будущем для всех других инструментов корпоративной среды. Все это уменьшит время выхода на рынок и снизит потребности специалистов по источникам данных в переводе имен столбцов
Необходимо помнить несколько ключевых моментов при работе с представлениями источников данных. Как и источники данных DSV позволяют один раз задать логику соединения и далее использовать ее во всех SSIS пакетах. Однако в отличие от соединений DSV не связаны с соединением-источником и не обновляются при изменениях структуры источника. Например, если в соединение имя таблицы с Employee поменяется на Resources, то DSV не подхватит эти изменения.
Область, в которой такой тип кэширования наиболее полезен - это разработка. DSV позволяют использовать кэшированные метаданных в процессе разработки, даже если Вы находитесь в аэропорту и Ваш компьютер не подключен к сети. Это ускоряет разработку пакетов. А так как DSV в большей степени являются подмножеством действительных данных источника, то и диалоговые окна соединений SSIS открываются гораздо быстрее. Пример того, как выглядит DSV, можно увидеть на Рисунке 30, на котором показано подмножество из базы AdventureWorks. На рисунке можно видеть, что в таблицу Employee к столбцу VacationHour было добавлено понятное имя с пробелом между словами. Это поможет с используемостью данных позднее, когда пользователи начнут использовать пакет или понадобится предоставить данные для Analysis Services.
Рисунок 30
При разработке SSIS пакета, использующего DSV, первый будет продолжать нормально работать, даже если в промышленной среде DSV уже не будет существовать. Это возможно потому, что SQL отображение для DSV привязано к задаче преобразования данных.
Преобразование Character Map
Преобразование Character Map можно применять для строковых преобразований столбцов, как в новые столбцы, так и на замену существующих. Преобразование Character Map включает:
Lowercase - преобразует символы к нижнему регистру. Uppercase - преобразует символы к верхнему регистру. Byte reversal - меняет порядок байтов на обратный. Hiragana - преобразует Katakana символы в Hiragana. Katakana - преобразует Hiragana символы в Katakana. Half width - преобразует двухбайтовые символы к однобайтовым. Full width -преобразует однобайтовые символы к двухбайтовым. Linguistic casing - для преобразования регистра применяются лингвистические методы а не системные. Simplified Chinese - преобразует символы в Simplified Chinese. Traditional Chinese - преобразует символы в Traditional Chinese.
Преобразование Copy Map
Преобразование Copy Map позволяет создавать копии столбцов для передачи их в приемник. Обычно преобразование Copy Map используют в тех случаях, когда нужно сохранить оригинальные данные, а преобразования произвести над их копией.
Преобразование Data Conversion
В преобразовании Data Conversion данные одного типа в столбце источника можно конвертировать в данные другого типа в приемнике.
Преобразование Derived Column
Преобразование Derived Column позволяет поточные преобразования с использованием SSIS выражений. Например, можно применить к числовому столбцу функцию CEILING и передать результат в новый столбец. Также можно создать условные переходы внутри выражения.
Преобразование Fuzzy Grouping
Преобразование Fuzzy Grouping позволяет произвести очистку данных путем нахождения совпадений между данными в разных записях. Результатом преобразования являются три дополнительных столбца - один для уникальной идентификации записи, второй для идентификации группы и третий для указания степени совпадения с образцом (значение от 0 до 1). На основе заданных в задаче порогов вероятности, можно достичь высокого уровня соответствия данных образцам. Например, при установленном пороге вероятности в 80% все, что выше этого порога считается совпадающими данными, а все что ниже возможно требует ручного подтверждения соответствия образцу. Типичным случаем использования данного типа преобразования может служить группировка по названию компании производимая по источнику на основе свободно форматированного текста (в котором, например Microsoft = Micro soft = MicroSoft).
Заметим, что данное преобразование требует наличия соединения с базой SQL Server 2005 для создания временной таблицы с промежуточными результатами, которые используются алгоритмы группировки.
Преобразование Fuzzy Lookup
Преобразование Fuzzy Lookup разрешает очистку данных на основе стандартизации данных, исправления данных и предоставления отсутствующих значений. Входные данные сравниваются с существующим набором эталонных данных с использованием алгоритмов, которые могут найти совпадения между нестрогими данными.
Обычно данный тип преобразования может следовать за стандартным Lookup преобразованием для тех записей, которым не были найдены совпадения. Это преобразование отличается от преобразования Lookup только тем, что в отличии от него использует нечеткое сравнение вместо сравнения на основе эквивалентности.
Преобразование Lookup
Преобразование Lookup использует эквивалентное совпадения для поиска в ссылочном наборе данных. Преобразование Lookup было существенно улучшено по сравнению с DTS 2000 и может быть тонко настроено через задание ограничений для кэширования и использования памяти. Также поиск можно добавить в поток данных в виде нового столбца для сохранения оригинальных естественных ключевых значений.
Обычно этот вид преобразования может быть использован для получения значений суррогатного ключа в процессах загрузки измерений в хранилищах данных.
Преобразование Pivot
Преобразование Pivot получает нормализованный набор данных и преобразует его в ненормализованный, размещая данные строк в столбцах. Данная функция похожа на функции из Microsoft Excel, но может быть применена к данным в конвейере.
Преобразование Sort
Преобразование Sort упорядочивает входные данные перед передачей их приемнику. Упорядочивание может производиться по нескольким столбцам по возрастанию и по убыванию, а также с учетом других критериев сортировки, например, с учетом регистра, одно- или двухбайтовых данных и пунктуации.
Преобразование Unpivot
Преобразование Unpivot производит действия противоположные преобразованию Pivot.
Преобразование данных
SSIS включает в себя как несколько новых объектов для разнообразных преобразований данных, в том числе очистку, конвертирование, распределение и объединение данных, так и преобразования, которые ускоряют разработку общих бизнес-интеллектуальных задач.
Приемник DataReader
Приемник DataReader (не имеет отношение к источнику DataReader) является мощными видом приемника, который дает возможность получать обработанные выходные данные ADO.NET приложениям, таким, как Reporting Services или пользовательским приложениям, которые можно разработать с использованием интерфейса DataReader. Чтобы помочь самому себе правильно использовать приемник, нужно убедиться, что наименование приемника в дальнейшем позволит однозначно узнать его в программе. На Рисунке 58 можно увидеть приемник по имени OutputAfterAggregation.
Рисунок 58
Если планируется использовать эти данные в Reporting Services, то нужно удостовериться, что в пакете имеется соединение соответствующего типа. А в Reporting Services необходимо проверить наличие расширения SSIS в разделе <DATA> файла RSReportDesigner.config. При инсталляции версии SQL Server 2005 Beta 3 это будет сделано автоматически. В Report Designer можно будет увидеть новый тип соединения по имени SSIS. При выборе этого источника данных просто введите полное имя пакета, например:
-f C:\SamplePackages\RSSFeedFromPartner.dtsx
В диалоге Query соединения укажите тот приемник DataReader, из которого нужно извлекать данные. Каждый раз, когда отчет будет запрашивать данные, будет выполняться DTS пакет, и можно будет увидеть приемник DataReader в процессе передачи им данных в конвейер. Для этого пакет должен содержать задачу Data Flow.
Такой подход особенно полезен для отображения данных не SQL Server после преобразования в Reporting Services или в другом приложении. Например, можно отображать выборку RSS преобразованную к табличному виду в Reporting Services. Пользователи могут подписываться на RSS выборку в Reporting Services и через эту подписку получать свои данные.
Приемник OLE DB
Приемник OLE DB является настоящим "пожирателем" данных. Этот приемник можно использовать для отсылки данных большинству видов реляционных источников данных. В большинстве своих настроек данный вид приемника похож на другие приемники. Но имеет хорошее дополнение в виде возможности при ошибках либо перенаправить сохранение записей, которые не удается добавить, в другую таблицу, либо прервать выполнение вообще, как это показано на Рисунке 57. Для перенаправления ошибочных записей выбирается другой приемник, который соединен с данным приемником, и поэтому может получать эти проблемные записи.
Рисунок 57
Приемник Raw File
Приемник Raw File (который также называют приемником Append) записывает неформатированные данные в файл. Из-за того, что используется начальный формат данных, такой вид экспорта данных является самым быстрым. Данный приемник можно использовать для записи данных в промежуточный файл, который позже можно загрузить и преобразовать в источнике Raw File другого пакета.
Приемник Recordset
Приемник Recordset является очень универсальным приемником, который позволяет направить данные в находящийся в памяти пакета набор записей. Во время работы пакета переменная будет заполнена направленными в нее данными. Позднее по ней можно организовать цикл с помощью задачи Foreach Loop.
Приемник SQL Server
Приемник SQL Server является типом приемника оптимизированным для SQL Server. Свои скоростные качества он получает за счет использования встроенных в SQL Server команд массовой загрузки. На закладке Advanced приемника можно указать те же установки, что доступны и при использовании команды массовой загрузки, например, срабатывание триггеров или блокирование таблицы. На Рисунке 56 можно увидеть установки заданные по-умолчанию. Очень важно отметить, что данные вид приемника можно использовать, только если выполнение пакета происходит на той же самой машине, на которой установлен SQL Server. Это ограничение происходит из-за использования интерфейсов, которые хранят все данные в памяти.
Рисунок 56
Приемники
Внутри потока данных приемники предназначены для приема данных от источников. За счет гибкой архитектуры, возможно, передавать данные практически в любой OLE DB-совместимый источник данных или в плоский файл. Есть также несколько второстепенных приемников, которые не будут рассмотрены в данной статье. Почти каждый приемник обладает похожими свойствами, которые отображаются в двух основных диалогах. Обычно, в закладке Connection Manager приемника можно задать использование соединения, которое было предварительно создано в Connection Manager. А в закладке Mappings определяются те данные, которые будут при обработке в потоке данных переданы приемнику, как это показано на Рисунке 55.
Рисунок 55
Если даже после логического группирования
Если даже после логического группирования пакет все еще выглядит сложно для интуитивного понимания, или есть желание документировать какие-то его особенности, то можно добавить текстовые примечания непосредственно в тело пакета. В любом месте, куда хочется поместить текстовое окно, нужно нажать правую кнопку мыши и в меню выбрать Add Annotation. Редактор создаст текстовое окно, в котором можно непосредственно печатать и размер которого может менять по своему усмотрению. Также можно изменить шрифт, его размер и цвет, если, выбрав окно примечания, нажать правую кнопку мыши и выбрать в меню пункт Set Text Annotation Font. Также можно добавлять примечания и в Редакторе Data Flow, который мы рассмотрим ниже. На Рисунке 23 показан пример текстового примечания.
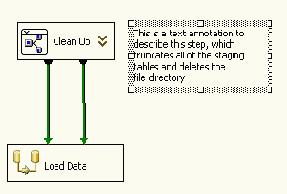
Рисунок 23
Прочие преобразования
Преобразование File Extractor
Преобразование File Extractor может взять данные типа TEXT, NTEXT, или IMAGE непосредственно из потока и записать их в файл. Каждая запись исходных данных может быть помещена в отдельный файл. Файлы приемники могут быть созданы на лету или можно добавить или заместить данные в уже существующих файлах.
Преобразование File Inserter
Преобразование File Inserter похоже на преобразование File Extractor за исключением того, что File Inserter может для каждой записи набора данных открыть файл и прочитать оттуда данные. Тип данных приемника информации из файла должен быть TEXT, NTEXT, или IMAGE.
Преобразование OLE DB Command
Преобразование OLE DB Command может для каждой записи набора данных выполнить SQL команды. Эти SQL команды может содержать параметры. Обычно данное преобразование используется для получения функциональности курсоров Transact-SQL для выполнения единообразной Transact-SQL операции для всего набора данных.
Преобразование Row Count
Преобразование Row Count подсчитывает число переданных через нее строк и сохраняет результат в переменную, которую можно использовать для проверки данных и процесса. Эту переменную также можно использовать для программного изменения в преобразованиях Conditional Split или Loop контейнерах.
Компонент Script
Компонент Script позволяет манипулировать данными в потоке данных с помощью скрипта. По своим характеристикам данные элемент похож на задачу Script из потока управления. Одним из типичных примеров использования этого элемента в потоке данных быть применение множественных преобразований каждой записи с использованием скриптов вместо множественных преобразований на основе задач. Другим типичным примером использования может быть использование частей уже существующих скриптов бизнес преобразований. Альтернативой такому решению может быть создание пользовательского преобразования.
Преобразование Term Extraction
Преобразование Term Extraction может извлекать похожие элементы из текстовых столбцов и записывать результат в отдельный приемник. Например, данное преобразование может осуществлять поиск ключевых слов или существительных в тексте, игнорируя предлоги и глаголы. Конечный результат может содержать список уникальных слов, который можно использовать для определения содержимого.
Преобразование Term Lookup
Преобразование Term Lookup проверяет совпадения элементов входного набора данных с эталонным набором данных и подсчитывает число вхождений во входном наборе. Данное преобразование можно использовать нормализации слов во множественном числе или прошедшем времени. Например, преобразование может сравнивать входное поле с комментариями со списком ключевых слов, и таким образом комментарии, содержащие ключевые слова можно направлять в надлежащее место.
Распределение, объединение или извлечение пробных данных
Все следующие преобразования распределяют, объединяют или извлекают данные.
Преобразование Conditional Split
Преобразование Conditional Split может перенаправить данные в различные приемники в зависимости от выполнения запрограммированных условий. Если ни одно из условий не выполнено, то данные автоматически направляются в приемник, который был задан как приемник по-умолчанию. BI Development Studio будет помечать каждый из вариантов вывода, включая вариант по-умолчанию, своим порядковым номером. Каждому условию должен быть определен уникальный приемник.
Преобразование Multicast
Преобразование Multicast может распределять копии одного потока данных нескольким приемникам. Эти копии являются логическими и обычно используются для обработки в агрегатных преобразованиях, в то время как детальные данные обрабатываются в нормальных преобразованиях. Заметим, что преобразование Multicast не поддерживает вывод ошибок, поскольку никакого реального преобразования данных не происходит.
Преобразование Merge
Преобразование Merge соединяет два упорядоченных набора данных в один на основе значений в их ключевых столбцах. Данное преобразование требует наличия сортировки у обоих входных наборов, а также совпадения типов данных в столбцах, по которым будет происходить соединение. Типы данных разной длины допустимы, если соответствующее поле второго входного набора не превосходит по длине соответствующее поле первого. Обычно преобразование Merge используют для обратного соединения данных, прошедших через преобразования Lookup и Fuzzy Lookup, опять в единый поток данных.
Преобразование Merge Join
Преобразование Merge Join очень похоже на преобразование Merge, но позволяет создавать результат, который получается при FULL, LEFT или INNER соединении двух упорядоченных наборов данных. Требования, которые предъявляет преобразования Merge Join, совпадают с требованиями для преобразования Merge, т.е. оба преобразования требуют упорядоченных данных и совпадения метаданных.
Преобразование Union All
Преобразование Union All объединяет множество входных данных в один выходной набор. В отличии от преобразований Merge и Merge Join данное преобразование не требует того, чтобы входные данные были упорядочены. Первый из входных наборов становится эталонным, а все другие входные наборы должны совпадать с ним по следующим условиям:
Тип данных Кодовая страница Точность Масштаб Размер Установки сравнения
Столбцы вторичных входных наборов, которые невозможно сопоставить со столбцами ссылочного набора в выходном наборе, будут установлены в NULL.
Расширение или изменение данных
Все перечисленные ниже преобразования расширяют данные либо за счет добавления или очистки, либо за счет непосредственного изменения данных в процессе осуществления преобразования.
Преобразование Aggregate
Преобразование Aggregate производит над полученным набором данных операции суммирования, вычисления среднего значения, подсчет общего количества, подсчет уникальных значений, вычисление максимальных или минимальных значений. Данное преобразование может производить группировку по одному или нескольким столбцам. Преобразование можно использовать для получения итоговых сумм для большого набора данных без необходимости либо сначала помещать его в реляционную базу, либо возлагать эти дополнительные действия на принимающую данные систему. На Рисунке 59 показаны несколько агрегатных функций (Sum, Average, Max, Min) для таблицы Employee Dimension из базы AdventureWorks Data Warehouse с группировкой по столбцу Department:
Рисунок 59
На следующем рисунке показан результат преобразования Aggregate, который будет передан в приемник:
Рисунок 60
Преобразование Audit
Данный тип преобразования разрешает доступ в потоке данных к параметрам среды и пакета. При конфигурировании можно к приемнику добавить те столбцы, которые нужны для ведения аудита. Вы можете добавить для потока данных следующие атрибуты аудита:
ExecutionInstanceGUID PackageID PackageName VersionID ExecutionStartTime MachineName UserName TaskName TaskID
Действительно полезными результатами аудита можно считать определение того, кто и когда выполнил пакет. Например, для достижения согласованности, возможно, понадобится добавить в таблицу биллинга столбец с информацией о том, каким образом данная запись была добавлена в таблицу.
Редактор Control Flow
Редактор Control Flow похож на DTS 2000 в том, что он содержит задачи и зависимости их запуска, но отличается наличием некоторых новых объектов-контейнеров, о которых следует знать. Эти контейнеры - For Loop, Foreach Loop, Sequence, а также задача Data Flow - содержат другие компоненты, которые производят определенного вида действия. Последовательность процессов в пакете задается с помощью редактора Control Flow. Редактор представляет собой рабочую область, в которой графически определяется, как задачи взаимодействуют между собой и порядок, в котором они будут выполняться.
После добавления новой задачи редактор Control Flow автоматически добавляет к ней стрелку или, иначе говоря, ограничение приоритета, с помощью которого данная задача может быть соединена с другими. Это показано на Рисунке 14.

Рисунок 14
Если Вы нажмете кнопкой мыши в любую часть стрелки или линии, то Редактор пакетов изменит ее на пунктирную линию. Теперь можно перетянуть стрелку на другую задачу и выбрать ее в качестве задачи-приемника нажатием кнопки мыши. Редактор соединит две задачи таким образом, что та задача, в которую направлена стрелка, будет запущена только в том случае, когда предшествующая задача будет успешно завершена (см. Рисунок 15).

Рисунок 15
Если нужно, чтобы задача-преемник была выполнена только в том случае, когда задача-предшественник закончиться неудачно, то необходимо дважды нажать кнопку мыши на линии, соединяющей эти две задачи для вывода диалога Precedence Constraint. В этом диалоге можно поменять результат выполнения на любой доступный, но если выбрать OnFailure и затем нажать OK, то цвет линии изменится на красный. На Рисунке 16 показано диалоговое окно Precedence Constraint Editor со своими опциями конфигурации.

Рисунок 16
Если необходимо, чтобы задача-преемник была запущена при любом результате завершения задачи-предшественника, то нужно изменить ограничение приоритета на OnCompletion и тогда цвет линии поменяется на синий.
Наличие в пакете только двух задач подразумевает только одно ограничение приоритета между ними. Если же пакет требует нескольких задач, то также можно добавить несколько ограничений приоритета между всеми задачами для создания столь сложных зависимостей, сколь необходимо пакету. На Рисунке 17 изображен немного более сложный пример процесса обработки и то, как SSIS позволяет осуществлять больший контроль над ходом выполнения.
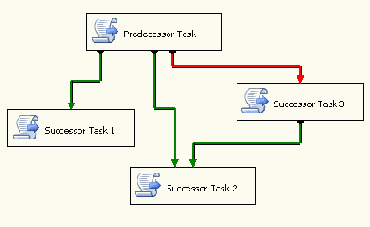
Рисунок 17
Новшеством в SQL Server 2005 является наличие логических условий AND и OR в случае, если у задачи есть множество ограничений приоритета. В DTS 2000 подобная задача могла быть запущена только в случае, когда все ограничения приоритета выполнялись. Это, безусловно, было проблемой в том случае, когда у какой-либо задачи было два или более ограничения приоритета для случая неудачного завершения задач-предшественников. Потому, что все эти задачи-предшественники обязательно должны были закончиться неудачно, чтобы сработала задача-преемник. В SQL Server 2005 при двойном нажатии кнопкой мыши на ограничении приоритета в появившемся диалоге кроме условия срабатывания Success, Failure, или Completion можно выбрать как взаимодействуют между собой множественные условия срабатывания - по AND или по OR. Логическое AND означает, что все ограничения приоритета должны быть выполнены для запуска задачи-преемника. Логическое OR означает, что для запуска задачи-преемника достаточно выполнения одного из ограничений приоритета. В первом случае линия, соединяющая задачи будет сплошной, а во втором - пунктирной. На Рисунке 18 показан диалог для задания ограничения приоритета подзадачи только при неудачном завершении, но разрешающий запуск подмножества задач.
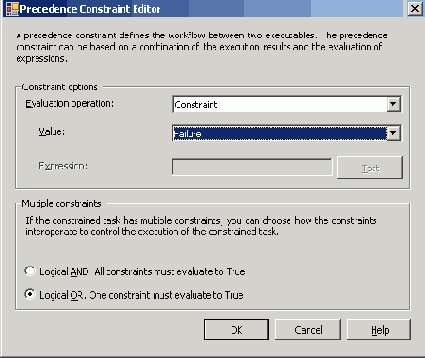
Рисунок 18
Такая возможность позволяет создать в SSIS логический поток такого вида, что изображен на Рисунке 19. На этом примере видно, что любая задача пакета, окончившаяся неудачно, приведет к запуску задачи Error Handler. Это позволяет создавать для группы задач единую задачу "обработки ошибок".
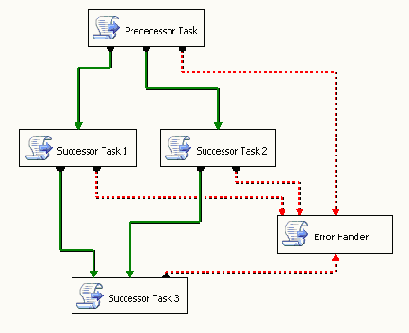
Рисунок 19
Редактор Data Flow
Редактор Data Flow управляет всеми перемещениями и преобразованиями данных между источником и приемником. Для добавления потока данных в пакет надлежит вручную добавить задачу Data Flow в Редакторе Control Flow. Или позволить это сделать самому SSIS при открытии окна Редактора Data Flow. Внутри себя задача Data Flow содержит все перемещения и преобразования данных. Хотя Data Flow и является лишь логическим контейнером для шагов по перемещению и преобразованию данных, но если один их этих шагов заканчивается ошибкой, то и вся задача Data Flow заканчивается ошибкой (если, конечно, для потоков данных задана установка Fail Component). На Рисунке 26 показан пример параллельного потока данных.
Рисунок 26
Пакет может содержать несколько задач Data Flow. Внутри каждой такой задачи фактически может быть несколько "потоков" между источниками и приемниками. Каждый из таких потоков источник-приемник внутри одной задачи Data Flow называется графом. У графа может быть несколько стадий преобразования. Обычно в графе имеются как адаптер-источник, который поставляет данные, так и адаптер-приемник, который потребляет данные. Между этими адаптерами и должны создаваться преобразователи данных. Если при передаче от источника к приемнику данные должны быть изменены, то сделать это можно внутри преобразования. Если данные нужно просто переместить из источника в приемник, то процесс использует путь, который аналогичен ограничениям приоритета в Редакторе Control Flow.
Можно увидеть свойства столбцов пути, если дважды нажать мышкой на стрелку между адаптерами, а затем выбрать на левой панели объект Metadata, как это показано на Рисунке 27.
Рисунок 27
Эти контейнеры потоков управления и данных более подробно рассматриваются в дальнейших главах
Редактор SSIS пакетов
Редактор SSIS пакетов встроен в BI Development Studio и предназначен в основном для разработки пакетов. Редактор содержит набор графических инструментов, которые позволяет осуществлять перемещение, последовательное и сложное преобразование данных без создания (или с минимальным количеством) программного кода. Редактор состоит из нескольких окон для потока управления, для потока данных, для создания соединений и для создания переменных.
В отличие от DTS 2000 в котором потоки данных и управления были совмещены, редакторы Control flow и Data flow в SSIS полностью разделены. Разделение потоков управления и данных предоставляет большие удобства и контроль при разработке сложных SSIS пакетов. Такое разделение обеспечивает интуитивный пользовательский интерфейс, лучший контроль над ходом выполнение пакета, увеличивает видимость процесса преобразования данных и увеличивает расширяемость SSIS за счет упрощения процессов разработки и выполнения пользовательских задач и преобразований. Вдобавок к упрощению сложных SSIS пакетов, можно создавать и простые потоки импорта и экспорта данных, не беспокоясь о потоке управления.
Разделение этих двух редакторов также означает то, что для каждого из них есть свой различный набор задач. Единственный способ, когда оба редактора потоков работают вместе - это контейнер задачи Data Flow. Все перемещения и преобразования данных происходят внутри одного или нескольких таких Data Flow задач.
Новые возможности SQL Server 2005 Integration Services
Введение
Мастера SSIS
Business Intelligence Development Studio
Visual Studio 2005
Окно Solution Explorer
Панель инструментов
Окно Properties
Другие окна
Управление панорамой и прокруткой
Настройка пользовательского интерфейса
Редактор SSIS пакетов
Редактор Control Flow
Логическая группировка задач
Примечания
Менеджеры соединений
Переменные
Редактор Data Flow
Выполнение пакета
Архитектура
Компоненты источника данных
Источник данных
Представление источника данных
Соединения
Элементы потока управления
Задачи
Архитектура совмествного использования
Ограничения приоритета
Тип ограничения
Условные ограничения
Контейнеры
Переменные
Динамическое изменение свойств
Выражения свойств
Элементы потока управления
Источники
Источник OLE DB
Источник Flat File
Источник Raw File
Источник XML
Источник DataReader
Приемники
Приемник SQL Server
Приемник Raw File
Приемник OLE DB
Приемник Recordset
Приемник DataReader
Преобразования данных
Расширение или изменение данных
Преобразование Character Map
Распределение, объединение и извлечение пробных данных
Аналитические преобразования
Прочие преобразования
Компоненты управления событиями
Компоненты управления ошибками
Компоненты ведения протокола и аудита
Разработка и тестирование
Отладка
Учебное пособие: Создание первого SSIS пакета
Об авторах
Соединения
Соединения в SQL Server Integration Services сильно изменилось со времен DTS. Но вместо того, чтобы привязать соединение к одному DTS пакету, теперь можно сделать соединение, которое доступно всему множеству пакетов проекта. В реальном мире это дает преимущество за счет того, что можно развернуть набор пакетов, которые нужны приложениям из промышленной среды и для указания в соединениях использовать промышленные данные должны изменить только одну установку. В SQL Server 2000 необходимо было открыть каждый пакет и произвести то же действие, но с риском забыть про какое-то из соединений и получить из-за этого проблемы на этапе внедрения.
Даже то, что можно создать внешнее по отношению к пакету соединение, не означает это обязательно нужно делать. По прежнему можно создать соединение внутри SSIS пакета, если предполагается использовать соединение один раз и не желательно вносить беспорядок в проект.
Тип ограничения
Как и в SQL Server 2000 DTS ограничения приоритета разделяются на три типа:
Complete. Ограничение завершения означает то, что следующая задача не запускается до тех пор, пока предыдущая задача не завершится с любым исходом - удачным или неудачным. Success. Ограничение удачного завершения означает то, что следующая задача не запускается до тех пор, пока предыдущая задача не завершится с удачным исходом. Если предыдущая задача завершается неудачно, то все последующие задачи данной ветви не будут выполнены. Failure. Ограничение неудачного завершения означает то, что следующая задача не запускается до тех пор, пока предыдущая задача не завершится с неудачным исходом. Данное ограничение обычно используют для оповещения о сбое по электронной почте.
Учебное пособие: Создание первого пакета SSIS
Теперь, имея хорошую теоретическую подготовку, Вы готовы к созданию своего первого пакета. В данном учебном пособии мы будем производить преобразование данных из плоского файла, содержащего около 9000 записей, агрегацию данных, их группировку, упорядочивание перед записью в новый текстовый файл. В SQL Server 2000 DTS все это требовало сложного кодирования или добавления данных в промежуточную таблицу, с которой и производились действия. В SQL Server 2005 Вам не нужны ни промежуточная таблица, ни какие то знания по программированию. Все это сильно уменьшит время создания Вашей ETL системы.
Для начала откройте Business Intelligence Development Studio. В меню File выберите пункт New, а затем Project.
Как предложено в данной демонстрации дайте пакету имя FirstPackage, как это видно на следующем рисунке.
Рисунок 71
После нажатия на OK основной проект будет создан и Вы увидите экран, как это показано на Рисунке 72.
Рисунок 72
В данном месте файл Package.dtsx должен быть открытым как часть процесса создания проекта. Если этого не случилось, то в Solution Explorer дважды нажмите кнопку мыши на этом пакете.
Начнем мы с создания соединений, которые будем использовать позднее.
Для добавления первого соединения для плоского файла нажмем правую кнопку мыши в закладке Connections (она расположена внизу экрана) и выберем New Flat File Connection. Откроется диалог Flat File Connection Manager Editor (см. Рисунок 73).
В закладке General этого диалога Вы можете задать большинство установок для плоского файла. Для свойства Connection Manager Name выберите значение Input File. Имя файла должно содержать и местоположение, и имя файла SampleFile.txt.
Далее убедитесь, что Вы указали двойные кавычки (") как признак текстовых столбцов и выбрали параметр Column names in first data row. Признак текстового столбца укажет механизму SSIS, что данные заключены внутри двойных кавычек. Такая инкапсуляция позволяет использовать в качестве разделителя такие символы как, например, запятая.
ф
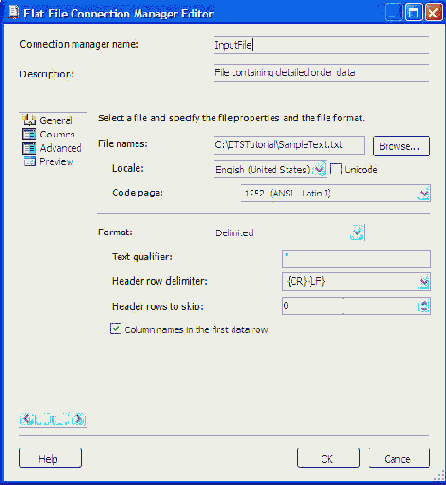
Рисунок 73
Перейдем к закладке Columns в левой панели того же диалога и удостоверимся, что мы видим столбцы и несколько первых записей наших данных. Далее перейдем в закладку Advanced(см. Рисунок 74). Здесь, перебирая столбцы, Вы можете увидеть, какие типы данных SSIS будет использовать для каждого из них. Выберите столбец по имени TransactionDate и для типа данных выберите "date [DT_DATE]". Для столбца Quantity также определите тип данных four-byte signed integer [DT_I4]".
Очень полезной особенностью здесь является наличие кнопка Suggest Type, которая заставляет DTS извлечь тестовые данные и предсказать какой тип они имеют. При автоматическом определении типов данных это будет сделано для всех столбцов, а не только для текущего выбранного. Всегда проверяйте сделанные выборы перед нажатием OK.
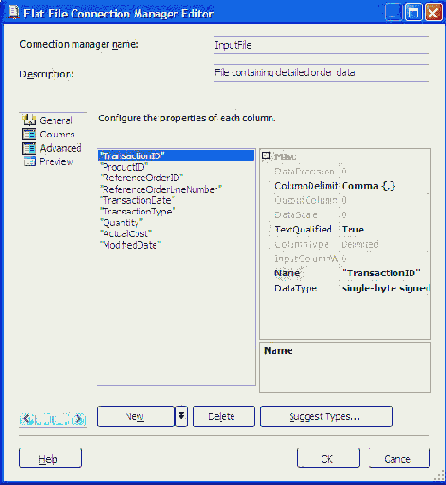
Рисунок 74
После нажатия OK Вы увидите соединение, расположенное в закладке Connections. Создайте еще одно соединение для файла SummarybyProductID.txt. В этом соединении выберите все установки по-умолчанию, кроме признака текстовых столбцов, которому нужно задать значение double-quotes. Назовите это соединение Output File.
Слева Вы должны видеть закладку Toolbox. Перетащите с нее элемент задачи DataFlow на закладку Control Flow.
Внимание: Вы можете зафиксировать положение Toolbox в своей среде разработки путем нажатия соответствующей иконки.
Нажните на вновь созданной задаче правую кнопку мыши и выберите Rename. Впишите "Transform Flat File" в качестве нового имени задачи. (Вы также можете нажать кнопку мыши на задаче и изменить свойство Name в панели Properties).
Нажмите правую кнопку мыши на переименованной задаче Data Flow и выберите Edit. Откроется закладка Data Flow.
В закладке Data Flow перетащите из Toolbox в область редактирования элемент потока данных по имени Flat File Source. Вы можете переименовать полученный элемент потока данных, нажимая на нем правую кнопку мыши и выбирая Rename. Переименуйте его в "Sample File".
Нажмите правую кнопку мыши на потоке данных Sample File и выберите Edit. Убедитесь что для параметра Connection из левой панели в Sample File задано в качестве соединения. Затем перейдите в раздел Columns и уберите отметку у большинства столбцов, оставив только ProductID, TransactionDate, Quantity, и ActualCost. Эти столбцы и будут нашим доступным потоком для всего SSIS пакета (см. Рисунок 75).
Рисунок 75
Теперь нам нужно создать новый столбец, который будет доступен в потоке. Он будет содержать количество единиц товара (столбец Quantity) умноженное на его стоимость (столбец ActualCost). Для этого перетащите задачу Derived Column на область редактирование чуть ниже соединения Sample File. Нажмите правую кнопку мыши на этой задаче и выберите Rename. Задайте новое имя "Total Cost". Выберите соединение Sample File и Вы увидите зеленую и красную стрелки направленные вниз. Зеленая стрелка определяет, что произойдет в случае, если этот шаг завершиться успешно. Красная стрелка определяет, что произойдет в случае, если этот шаг завершиться неуспешно. Выберите зеленую стрелку и перетащите ее на задачу Total Cost.
После соединения этих двух элементов нажмите правую кнопку мыши на элементе Total Cost и выберите Edit. Откроется диалог Derived Column Editor.
Раскройте расположенное справа дерево Columns и перетащите столбцы Quantity и ActualCost в столбец Expression, как показано на Рисунке 76. Укажите в столбце Expression выражение Quantity*ActualCost. Если Вы получите сообщение об ошибке типов данных, то Вам следует перечитать первую часть данного пособия, в которой говорилось о задании типов данных каждому столбцу данного соединения.
Измените имя вычисляемого столбца на TotalCost, а его тип на Currency, как показано на Рисунке 76. После этого нажмите OK. Все это приведет к созданию дополнительного столбца, который можно увидеть в преобразованиях в следующих задач и который будет содержать произведение двух столбцов.
Рисунок 76
После создания нового вычисляемого столбца мы готовы перейти к агрегированию данных по продуктам. Перетащите задачу Aggregate из Toolbox на панель редактирования. Соедините задачу Total Cost и новую задачу с помощью зеленой стрелки. И переименуйте задачу в "Group by Product."
Откройте диалог Aggregate Editor путем нажатия правой кнопки мыши на задаче Group by Product с последующим выбором Edit. В Aggregate Editor задайте желаемый способ агрегации для соединения. Важно отметить, что до сих пор мы не занесли еще ни одной записи, ни в одном из источников. Все происходит только в памяти.
В диалоге Aggregate Editor (см. Рисунок 77) выберите столбцы ProductID, TransactionDate, Quantity, и TotalCost. Это частично заполнит область по имени Input Column.
Затем задайте тип операции, которая будет выполнена для каждого из столбцов. Мы желает осуществить группировку по ProductID, поэтому выберем для него тип Group By. Для столбцов Quantity и TotalCost выберем операцию Sum. И, наконец, для столбца TransactionDate - Maximum. Также измените значение свойства Output Aliases для двух новых столбцов, чтобы дать им уникальные имена. Таким образом, мы получили группировку по столбцу ProductID с максимальными значениями по столбцу TransactionDate и суммами по столбцам количества и цены.
Для сохранения изменений нажмите OK. Вы можете заметить, что столбец TotalCost теперь стал доступен в данной задаче. Как и было сказано, добавленные вычисляемые столбцы становятся видимыми в последующих задачах.
Рисунок 77
Теперь, когда данные агрегируются по ProductID, мы готовы к сортировке данных для их более понятного восприятия в отчете. Перетащите задачу Sort (см. Рисунок 78) из Toolbox и переименуйте ее в "Order by ProductID". Убедитесь, что эта задача соединена с задачей Group by Product зеленой стрелкой. Откройте задачу для изменения, как и все предыдущие. Выберите столбец ProductID и установите для него упорядочивание по возрастанию. Нажмите OK для завершения.
Рисунок 78
В завершении нам нужно вывести результаты работы в другой плоский файл. Перетащите задачу Flat File Destination из Toolbox. Соедините ее с задачей Order by ProductID путем перетягивания между ними зеленой стрелки.
Выберите Edit для изменения свойств приемника Flat File
Выберите New для создания нового соединения с плоским файлом.
Переименуйте соединение в Output File (подробности см. на Рисунке 79).
Убедитесь, что в разделе Preview видны все выходные столбцы предыдущих элементов.
В разделе Mappings убедитесь, что преобразование выглядит правильно. Нажмите OK.
Вы закончили создание пакета. Для его запуска нажмите F5 или в меню Start выберите пункт Debug. Вы увидите, как начнет увеличиваться счетчик записей. На Рисунке 79 показан конечный результат всех действий.
Рисунок 79
Выбрав закладку Progress (см.Рисунок 80) Вы сможете увидеть подробное описание процесса выполнения SSIS.
Рисунок 80
Управление панорамой и прокруткой
Если созданный пакет превышает размеры области редактирования и требует прокрутки, то в правом нижнем углу области редактирования можно увидеть маленькое перекрестие (см. Рисунок 12).

Рисунок 12
Если нажать на это перекрестие мышкой, то появится всплывающее окно, в котором будет видно уменьшенное отображение всего пакета, а пунктирная линия обозначит текущую видимую часть (см. Рисунок 13).
Рисунок 13
Условные ограничения
Существенным новшеством в работе ограничений приоритета стала возможность задания условных выражений при соединении задач в цепочку или даже их зацикливание до выполнения заданного условия. Ниже в данной главе дано множество примеров использования этой возможности.
Вычислительные операторы
Вычислительные операторы дают разработчику возможность создать настоящий цикл обработки внутри пакета на основе условного управления потоком задач. После создания условия ограничения можно задать его свойству EvalOp одно из следующих значений, определяющих критерий вычисления ограничений приоритета:
Constraint. Это значение по-умолчанию при котором вычисляется только само ограничение. Expression. В этом случае вычисляется только выражение. ExpressionAndConstraint. Перед переходом к следующей задаче вычисляются как выражение, так и ограничение. ExpressionOrConstraint. Для перехода к следующей задаче либо выражение, либо ограничение должны быть выполнены.
Логическое вычисление
Последнее свойство, про которое стоит упомянуть для ограничений приоритета - это свойство LogicalAnd. Это свойство управляет запуском следующей задачи при ее зависимости от результатов запуска множества задач. По-умолчанию это свойство имеет значение True, что обеспечивает вычисление всех множественных ограничений вместе как единое выражение AND, если использовать понятия SQL.
BI Development Studio была создана по основе Visual Studio 2005, чтобы помочь Вам при проектировании, создании, тестировании, развертывании и расширении SSIS пакетов в интегрированной среде разработки. BI Development Studio также поддерживает использование .NET Framework с другими средствами разработки фирмы Microsoft (Microsoft Visual Basic ®. NET, C#, C++, J#). Интеграции с Visual Studio 2005 позволяет поставлять BI Development Studio с таким интегрированными средствами разработки как мощный отладчик, интегрированный контроль версий для многопользовательской среды разработки и интегрированная встроенная помощь. BI Development Studio предназначена для разработчиков, чтобы они могли использовать единые средства разработки, модель программирования и навыки, как для создания пакетов, так и специальных задач, которые они уже разработали ранее при создании приложений.
Одним из преимуществ такого проектно-ориентированного режима работы является то, что он не требует соединения с работающим SQL Server для собственно процесса разработки. Вторым преимуществом является наличие автоматического и интегрированного доступа к средству контроля версий для всех файлов, включенных в Решение или Проект.
При первом запуске BI Development Studio и создании нового проекта Integration Services можно увидеть лишь упрощенный вид данной среды. Не видно никаких задач, объектов или пакетов, потому что только что было создано пустое решение. Можно заметить лишь несколько открытых окон - Toolbox, Solution Explorer, Properties, и возможно такие окна как Output и Search Results. Все эти окна можно открепить от их текущего местоположение, прикрепить к другому местоположению, переместить, закрыть или установить им режим автоматического сокрытия для увеличения незанятой части экрана и повышения производительности. Даже если какое-либо окно было закрыто, то можно выбрать пункт основного меню View и далее какой-либо из пунктов подменю, чтобы снова открыть нужное окно. Окна Solution Explorer, Properties, Toolbox и некоторые другие можно открыть непосредственно из панели инструментов. Нужно всего лишь нажать мышкой на одной из иконок этой группы (см. Рисунок 6)

Рисунок 6
На Рисунке 7 изображено то, что можно увидеть при первом запуске BI Development Studio.
Рисунок 7
Заметьте, что по умолчанию в Development Studio все вспомогательные окна расположены вокруг центральной главной рабочей области. Большинство из этих окон можно перенастроить. Как это сделать, рассматривается в дальнейших главах.
и переделанный Data Transformation Services
Microsoft® SQL Server™ Integration Services (SSIS) представляет собой полностью перепроектированный и переделанный Data Transformation Services (DTS) из SQL Server 2000. В результате такой "перестройки" многие парадигмы архитектуры и администрирования были пересмотрены. Сейчас SSIS не является уже отдельным средством проектирования. Принимая Microsoft Visual Studio® в качестве средства разработки, SSIS в тоже время продолжает использовать возможности стандартных средств управления SQL Server 2005. Новая среда разработки получила название Business Intelligence (BI) Development Studio, а новая среда администрирования - SQL Server Management Studio. Такое разделение позволяет разработчикам и администраторам баз данных (DBA) сосредоточиться на решении специфических задач из своей области.
Оба типа средств имеют возможность выполнять пакеты, но если в BI Development Studio это можно делать только в консоли разработчика, то в Management Studio можно выполнять импортированные на сервер пакеты. Решения на основе BI Development Studio могут состоять из одного или нескольких проектов, проекты в свою очередь могут состоять из нескольких источников данных, представлений источников данных, SSIS пакетов и прочих файлов. Например, новый проект может включать и разрабатываемый SSIS пакет и вызовы других пакетов. А также другие файлы поддержки, например файлы с командами создания объектов (data definition language - DDL) или командами манипуляции данными (data manipulation language - DML) для той СУБД, с которой Вы работаете. Когда придет время сдачи проекта в эксплуатацию, все необходимые для этого файлы будут собраны вместе.
BI Development Studio не нуждается в непосредственном соединении с СУБД SQL Server ни при разработке пакетов, ни при сохранении внесенных в проект изменений. BI Development Studio сохраняет проекты в каталогах, как это делает и Visual Studio. В BI Development Studio также имеется интеграция с Visual SourceSafe (и другими программами контроля версий). И все сделанные в проектах изменения можно сразу отобразить в VSS.
Management Studio в отличии от BI Development Studio предназначена в первую очередь для администраторов баз данных (DBA) и позволяет управлять SQL, Analysis Services и Reporting Services серверами. В ней имеется поддержка для запуска SSIS пакетов как непосредственно, так и по расписанию, но не предусмотрена возможность создания или редактирования пакетов. Однако у пользователя все равно есть возможность использовать SSIS для задач импорта/экспорта данных и обслуживания.
Выполнение пакета
До сих пор мы рассматривали только процесс редактирования пакета. Если необходимо выполнить пакет, то можно нажать мышкой на соответствующую иконку на панели инструментов, или нажать клавишу F5, или нажать в меню пункт Start и затем Debug. При этом произойдет переход среды из режима редактирования в режим выполнения. Это выражается в открытии нескольких новых окон, в доступности некоторых новых пунктов меню и элементов панели инструментов и собственно в процессе выполнения пакета. После окончания выполнения пакета BI Development Studio не возвращается сразу же в режим редактирования, но остается в режиме выполнения для того, чтобы разработчики имели возможность проверить значения переменных или просмотреть любой из результатов процесса выполнения. Это также означает, что нельзя изменять сами объекты пакета, но можно изменять переменные и свойства пакета.
Для возврата в режим редактирования можно нажать мышкой иконку Stop в панели инструментов отладчика, или нажать Shift+F5, или выбрать меню Debug, а затем Stop Debugging.
Выражения свойств
Выражения свойств позволяют динамически изменять переменные в ходе выполнения. Эти встроенные в язык выражения позволяют легко изменить свойства задач, соединений, лог провайдеров и нумераторов ForEach. Ранее для подобных целей нужно было использовать задачу Dynamic Properties, но выражения свойств гораздо лучше справляются с этим. Их можно использовать для изменения свойств таких событий как:
Задачи
Before Saving After Loading Before initialization Before Validation Before Execution
Менеджеры соединений
Before Saving After Loading Before initialization Before returning from AcquireConnection calls
Лог провайдеры
Before Saving After Loading Before Initialization
Нумератооы ForEach
Before Saving After Loading Before Initialization Before returning from GetEnumerator calls
Например, если ежедневно от мэйнфрэйма приходит файл и необходимо перемещать его в директорию Processed, снабдив при этом временной меткой, то можно использовать выражения свойств совместно с задачей File System для динамического задания имени конечного файла.
в SQL Server 2000 задачи
Как и в SQL Server 2000 задачи являются краеугольным камнем SSIS пакета. Задача SSIS есть объект из Панели Инструментов, который отвечает за выполнения части общей работы. Например, существуют задачи для управления копирования файла и задачи для управления потоком данных.
