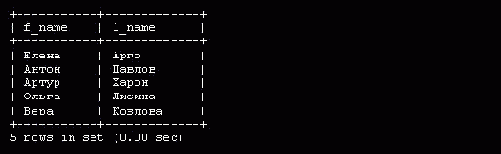Иерархические базы данных поддерживают древовидную организацию информации. Связи между записями выражаются в виде отношений предок/потомок, а у каждой записи есть ровно одна родительская запись. Это помогает поддерживать ссылочную целостность. Когда запись удаляется из дерева, все ее потомки также должны быть удалены.
На рис. 1.2 изображена простая иерархическая база данных, в которой фиксируется деятельность независимого подрядчика. Корень дерева представляет собой запись о клиенте. Ее потомками являются две записи о счет-фактурах и три записи об оплатах счетов. Структура счета номер 17 уточняется в трех дочерних записях, у счета номер 23 одна такая запись.
Рис. 1.2. Иерархическая база данных
Иерархические базы данных имеют централизованную структуру, т.е. безопасность данных легко контролировать. К сожалению, определенные знания о физическом порядке хранения записей все же необходимы, так как отношения предок/потомок реализуются в виде физических указателей из одной записи на другую.
Это означает, что поиск записи осуществляется методом прямого обхода дерева. Записи, расположенные в одной половине дерева, ищутся быстрее, чем в другой. Отсюда следует необходимость правильно упорядочивать записи, чтобы время их поиска было минимальным. Это трудно, так как не все отношения, существующие в реальном мире, можно выразить в иерархической базе данных. Отношения "один ко многим" являются естественными, но практически невозможно описать отношения "многие ко многим" или ситуации, когда запись имеет несколько предков. До тех пор пока в приложениях будут кодироваться сведения о физической структуре данных, любые изменения этой структуры будут грозить перекомпиляцией.
Компьютерные системы хранения
В наши дни люди часто говорят о базах данных. Компьютеры составляют неотъемлемую часть современного общества, поэтому нередко можно услышать фразы вроде "Я поищу твою запись в базе данных". И речь идет не о больших ящиках, где хранятся груды папок, а о компьютерных системах, предназначенных для ускоренного поиска информации.
Компьютеры так прочно вошли в нашу жизнь, потому что их можно запрограммировать на выполнение утомительных, повторяющихся операций и решение задач, которые нам самим было бы не под силу решить без их вычислительной скорости и емкости информационных носителей. Помещение информации на бумагу и разработка схемы хранения бумаг в папках и картотеках — достаточно четко отработанный процесс, но многие вздохнули с облегчением, когда задача свелась к перемещению электронных документов в папки на жестком диске.
Одной из функций баз данных является упорядочение и индексация информации. Как и в библиотечной картотеке, не нужно просматривать половину архива, чтобы найти нужную запись. Все выполняется гораздо быстрее.
Не все базы данных создаются на основе одних и тех же принципов, но традиционно в них применяется идея организации данных в виде записей. Каждая запись имеет фиксированный набор полей. Записи помещаются в таблицы, а совокупность таблиц формирует базу данных.
Для работы с базой данных необходима СУБД (система управления базами данных), т.е. программа, которая берет на себя все заботы, связанные с доступом к данным. Она содержит команды, позволяющие создавать таблицы, вставлять в них записи, искать и даже удалять записи.
MySQL - это быстрая, надежная, открыто распространяемая СУБД. MySQL, как и многие другие СУБД, функционирует по модели "клиент/сервер". Под этим подразумевается сетевая архитектура, в которой компьютеры играют роли клиентов либо серверов. На рис. 1.1 изображена схема передачи информации между компьютером клиента и жестким диском сервера.
Рис. 1.1. Схема передачи данных в архитектуре "клиент/сервер"
СУБД управляет одной или несколькими базами данных. База данных представляет собой совокупность информации, организованной в виде множеств. Каждое множество содержит записи унифицированного вида. Сами записи состоят из полей. Обычно множества называют таблицами, а записи — строками таблиц.
Такова логическая модель данных. На жестком диске вся база данных может находиться в одном файле. В MySQL для каждой базы данных создается отдельный каталог, а каждой таблице соответствуют три файла. В других СУБД могут использоваться иные принципы физического хранения данных.
Строки таблиц могут быть связаны друг с другом одним из трех способов. Простейшее отношение — "один к одному". В этом случае строка первой таблицы соответствует одной единственной строке второй таблицы. На диаграммах такое отношение выражается записью 1:1.
Отношение "один ко многим" означает ситуацию, когда строка одной таблицы соответствует нескольким строкам другой таблицы. Это наиболее распространенный тип отношений. На диаграммах он выражается записью 1:N.
Наконец, при отношении "многие ко многим" строки первой таблицы могут быть связаны с произвольным числом строк во второй таблице. Такое отношение записывается как N:M.
Объектно-ориентированные базы данных
Объектно-ориентированная база данных (ООБД) позволяет программистам, которые работают с языками третьего поколения, интерпретировать все свои информационные сущности как объекты, хранящиеся в оперативной памяти. Дополнительный интерфейсный уровень абстракции обеспечивает перехват запросов, обращающихся к тем частям базы данных, которые находятся в постоянном хранилище на диске. Изменения, вносимые в объекты, оптимальным образом переносятся из памяти на диск.
Преимуществом ООБД является упрощенный код. Приложения получают возможность интерпретировать данные в контексте того языка программирования, на котором они написаны. Реляционная база данных возвращает значения всех полей в текстовом виде, а затем они приводятся к локальным типам данных. В ООБД этот этап ликвидирован. Методы манипулирования данными всегда остаются одинаковыми независимо от того, находятся данные на диске или в памяти.
Данные в ООБД способны принять вид любой структуры, которую можно выразить на используемом языке программирования. Отношения между сущностями также могут быть произвольно сложными. ООБД управляет кэш-буфером объектов, перемещая объекты между буфером и дисковым хранилищем по мере необходимости.
С помощью ООБД решаются две проблемы. Во-первых, сложные информационные структуры выражаются в них лучше, чем в реляционных базах данных, а во-вторых, устраняется необходимость транслировать данные из того формата, который поддерживается в СУБД. Например, в реляционной СУБД размерность целых чисел может составлять 11 цифр, а в используемом языке программирования — 16. Программисту придется учитывать эту ситуацию.
Объектно-ориентированные СУБД выполняют много дополнительных функций. Это окупается сполна, если отношения между данными очень сложны. В таком случае производительность ООБД оказывается выше, чем у реляционных СУБД. Если же данные менее сложны, дополнительные функции оказываются избыточными. В объектной модели данных поддерживаются нерегламентированные запросы, но языком их составления не обязательно является SQL. Логическое представление данных может не соответствовать реляционной модели, поэтому применение языка SQL станет бессмысленным. Зачастую удобнее обрабатывать объекты в памяти, выполняя соответствующие виды поиска.
Большим недостатком объектно-ориентированных баз данных является их тесная связь с применяемым языком программирования. К данным, хранящимся в реляционной СУБД, могут обращаться любые приложения, тогда как, к примеру, Java-объект, помещенный в ООБД, будет представлять интерес лишь для приложений, написанных на Java.
Объектно-реляционные базы данных
Объектно-реляционные СУБД объединяют в себе черты реляционной и объектной моделей. Их возникновение объясняется тем, что реляционные базы данных хорошо работают со встроенными типами данных и гораздо хуже — с пользовательскими, нестандартными. Когда появляется новый важный тип данных, приходится либо включать его поддержку в СУБД, либо заставлять программиста самостоятельно управлять данными в приложении.
Не всякую информацию имеет смысл интерпретировать в виде цепочек символов или цифр. Представим себе музыкальную базу данных. Песню, закодированную в виде аудиофайла, можно поместить в текстовое поле большого размера, но как в таком случае будет осуществляться текстовый поиск?
Перестройка СУБД с целью включения в нее поддержки нового типа данных — не лучший выход из положения. Вместо этого объектно-реляционная СУБД позволяет загружать код, предназначенный для обработки "нетипичных" данных. Таким образом, база данных сохраняет свою табличную структуру, но способ обработки некоторых полей таблиц определяется извне, т.е. программистом.
Основные характеристики MySQL
Клиентская программа MySQL представляет собой утилиту командной строки. Эта программа подключается к серверу по сети. Команды, выполняемые сервером, обычно связаны с чтением и записью данных на жестком диске.
Клиентские программы могут работать не только в режиме командной строки. Есть и графические клиенты, например MySQL GUI, PhpMyAdmin и др. Но они – тема отдельного курса.
MySQL взаимодействует с базой данных на языке, называемом SQL (Structured Query Language — язык структурированных запросов).
SQL предназначен для манипуляции данными, которые хранятся в Системах управления реляционными базами данных (RDBMS). SQL имеет команды, с помощью которых данные можно извлекать, сортировать, обновлять, удалять и добавлять. Стандарты языка SQL определяет ANSI (American National Standards Institute). В настоящее время действует стандарт, принятый в 2003 году (SQL-3).
SQL можно использовать с такими RDBMS как MySQL, mSQL, PostgresSQL, Oracle, Microsoft SQL Server, Access, Sybase, Ingres. Эти системы RDBMS поддерживают все важные и общепринятые операторы SQL, однако каждая из них имеет множество своих собственных патентованных операторов и расширений.
SQL является общим языком запросов для нескольких баз данных различных типов. Данный курс рассматривает систему MySQL, которая является RDBMS c открытым исходным кодом, доступной для загрузки на сайте MySQL.com.
Вот как характеризуют MySQL её разработчики.
MySQL - это система управления базами данных.
База данных представляет собой структурированную совокупность данных. Эти данные могут быть любыми - от простого списка предстоящих покупок до перечня экспонатов картинной галереи или огромного количества информации в корпоративной сети. Для записи, выборки и обработки данных, хранящихся в компьютерной базе данных, необходима система управления базой данных, каковой и является ПО MySQL. Поскольку компьютеры замечательно справляются с обработкой больших объемов данных, управление базами данных играет центральную роль в вычислениях. Реализовано такое управление может быть по-разному - как в виде отдельных утилит, так и в виде кода, входящего в состав других приложений.
MySQL - это система управления реляционными базами данных.
В реляционной базе данные хранятся в отдельных таблицах, благодаря чему достигается выигрыш в скорости и гибкости. Таблицы связываются между собой при помощи отношений, благодаря чему обеспечивается возможность объединять при выполнении запроса данные из нескольких таблиц. SQL как часть системы MySQL можно охарактеризовать как язык структурированных запросов плюс наиболее распространенный стандартный язык, используемый для доступа к базам данных.
Программное обеспечение MySQL - это ПО с открытым кодом.
ПО с открытым кодом означает, что применять и модифицировать его может любой желающий. Такое ПО можно получать по Internet и использовать бесплатно. При этом каждый пользователь может изучить исходный код и изменить его в соответствии со своими потребностями.
Технические возможности СУБД MySQL
ПО MySQL является системой клиент-сервер, которая содержит многопоточный SQL-сервер, обеспечивающий поддержку различных вычислительных машин баз данных, а также несколько различных клиентских программ и библиотек, средства администрирования и широкий спектр программных интерфейсов (API).
Безопасность
Система безопасности основана на привилегиях и паролях с возможностью верификации с удаленного компьютера, за счет чего обеспечивается гибкость и безопасность. Пароли при передаче по сети при соединении с сервером шифруются. Клиенты могут соединяться с MySQL, используя сокеты TCP/IP, сокеты Unix или именованные каналы (named pipes, под NT)
Вместимость данных
Начиная с MySQL версии 3.23, где используется новый тип таблиц, максимальный размер таблицы доведен до 8 миллионов терабайт (263 bytes). Однако следует заметить, что операционные системы имеют свои собственные ограничения по размерам файлов. Ниже приведено несколько примеров:
- 32-разрядная Linux-Intel – размер таблицы 4 Гб.
- Solaris 2.7 Intel - 4 Гб
- Solaris 2.7 UltraSPARC - 512 Гб
- WindowsXP - 4 Гб
Как можно видеть, размер таблицы в базе данных MySQL обычно лимитируется операционной системой. По умолчанию MySQL-таблицы имеют максимальный размер около 4 Гб. Для любой таблицы можно проверить/определить ее максимальный размер с помощью команд SHOW TABLE STATUS или myisamchk -dv table_name. Если большая таблица предназначена только для чтения, можно воспользоваться myisampack, чтобы слить несколько таблиц в одну и сжать ее. Обычно myisampack ужимает таблицу по крайней мере на 50%, поэтому в результате можно получить очень большие таблицы.
Реляционные базы данных
В сравнении с рассмотренными выше моделями реляционная модель требует от СУБД гораздо более высокого уровня сложности. В ней делается попытка избавить программиста от выполнения рутинных операций по управлению данными, столь характерных для иерархической и сетевой моделей.
В реляционной модели база данных представляет собой централизованное хранилище таблиц, обеспечивающее безопасный одновременный доступ к информации со стороны многих пользователей. В строках таблиц часть полей содержит данные, относящиеся непосредственно к записи, а часть — ссылки на записи других таблиц. Таким образом, связи между записями являются неотъемлемым свойством реляционной модели.
Каждая запись таблицы имеет одинаковую структуру. Например, в таблице, содержащей описания автомобилей, у всех записей будет один и тот же набор полей: производитель, модель, год выпуска, пробег и т.д. Такие таблицы легко изображать в графическом виде.
В реляционной модели достигается информационная и структурная независимость. Записи не связаны между собой настолько, чтобы изменение одной из них затронуло остальные, а изменение структуры базы данных не обязательно приводит к перекомпиляции работающих с ней приложений.
В реляционных СУБД применяется язык SQL, позволяющий формулировать произвольные, нерегламентированные запросы. Это язык четвертого поколения, поэтому любой пользователь может быстро научиться составлять запросы. К тому же, существует множество приложений, позволяющих строить логические схемы запросов в графическом виде. Все это происходит за счет ужесточения требований к производительности компьютеров. К счастью, современные вычислительные мощности более чем адекватны.
Реляционные базы данных страдают от различий в реализации языка SQL, хотя это и не проблема реляционной модели. Каждая реляционная СУБД реализует какое-то подмножество стандарта SQL плюс набор уникальных команд, что усложняет задачу программистам, пытающимся перейти от одной СУБД к другой. Приходится делать нелегкий выбор между максимальной переносимостью и максимальной производительностью. В первом случае нужно придерживаться минимального общего набора команд, поддерживаемых в каждой СУБД. Во втором случае программист просто сосредоточивается на работе в данной конкретной СУБД, используя преимущества ее уникальных команд и функций.
MySQL — это реляционная СУБД, и настоящий учебный курс посвящен изучению именно реляционной модели. Но теория баз данных не стоит на месте. Появляются новые технологии, которые расширяют реляционную модель.
Сетевые базы данных
Сетевая модель расширяет иерархическую модель, позволяя группировать связи между записями в множества. С логической точки зрения связь — это не сама запись. Связи лишь выражают отношения между записями. Как и в иерархической модели, связи ведут от родительской записи к дочерней, но на этот раз поддерживается множественное наследование.
Следуя спецификации CODASYL, сетевая модель поддерживает DDL (Data Definition Language — язык определения данных) и DML (Data Manipulation Language — язык обработки данных). Это специальные языки, предназначенные для определения структуры базы данных и составления запросов. Несмотря на их наличие, программист по-прежнему должен знать структуру базы данных.
В сетевой модели допускаются отношения "многие ко многим", а записи не зависят друг от друга. При удалении записи удаляются и все ее связи, но не сами связанные записи.
В сетевой модели требуется, чтобы связи устанавливались между существующими записями во избежание дублирования и искажения целостности. Данные можно изолировать в соответствующих таблицах и связать с записями в других таблицах.
Программисту не нужно заботиться о том, как организуется физическое хранение данных на диске. Это ослабляет зависимость приложений и данных. Но в сетевой модели требуется, чтобы программист помнил структуру данных при формировании запросов.
Оптимальную структуру базы данных сложно сформировать, а готовую структуру трудно менять. Если вид таблицы претерпевает изменения, все отношения с другими таблицами должны быть установлены заново, чтобы не нарушилась целостность данных. Сложность подобной задачи приводит к тому, что программисты зачастую отменяют некоторые ограничения целостности ради упрощения приложений.
Системы управления файлами
Простейшая база данных организована в виде набора обычных файлов. Эта модель напоминает картотечную организацию документов, при которой папки хранятся в ящиках, а в каждой папке подшито некоторое число страниц.
Системы управления файлами нельзя классифицировать как СУБД, так как обычно они являются частью операционной систем и ничего не знают о внутреннем содержимом файлов. Это знание заложено в прикладных программах, работающих с файлами. В качестве примера можно привести таблицу пользователей UNIX, хранящуюся в файле /etc/passwd. Программы, обращающиеся к этому файлу, знают, что в его первом поле находится имя пользователя, оканчивающееся двоеточием. Если приложению нужно отредактировать эту информацию, оно должно непосредственно открыть файл и позаботиться о правильном форматировании полей.
Такая модель базы данных очень неудобна, поскольку она требует использовать язык третьего поколения (3GL). В результате время программирования запросов увеличивается, а программист должен обладать более высокой квалификацией, так как ему нужно продумать не только логическую, но и физическую структуру хранения данных. Это приводит к тому, что между приложением и файлом образуется тесная связь. Вся информация о полях таблиц закодирована в приложении. Другое приложение, обращающееся к тому же файлу, вынуждено дублировать существующий код.
По мере увеличения числа приложений растет сложность управления базой данных. Изменения схемы данных приводят к необходимости изменения каждого программного компонента, для которого это актуально. Формирование новых запросов занимает столько времени, что зачастую теряет всякий смысл.
Системы управления файлами не могут помешать дублированию информации. Хуже того, не существует механизмов, предотвращающих несогласованность данных. Представьте себе файл, содержащий сведения обо всех служащих компании. В каждой строке есть поле, где записано имя начальника. Под руководством одного начальника работает много служащих, поэтому его имя будет неизбежно повторяться. Если где-то это имя будет записано неправильно, формально получится, что у служащего другой начальник. При замене начальника его имя придется "вылавливать" по всей базе данных.
Безопасность обычных файлов контролируется операционной системой. Отдельный файл может быть заблокирован для просмотра или модификации со стороны того или иного пользователя, но это выполняется только на уровне операционной системы. В конкретный момент времени лишь одно приложение может осуществлять запись в файл, что снижает общую производительность.
СУБД
Программист, работающий с базой данных, не заботится о том, как эти данные хранятся, и приложения, взаимодействующие с СУБД, не знают о способе записи данных на диск. "Снаружи" виден лишь логический образ данных, и это позволяет менять код СУБД, не затрагивая код самих приложений.
Подобная обработка данных осуществляется посредством языка четвертого поколения (4GL), который поддерживает запросы, записываемые и исполняемые немедленно. Данные быстро утрачивают свою актуальность, поэтому скорость доступа к ним важна. Кроме того, программист должен иметь возможность формулировать новые запросы. Они называются нерегламентированными (ad hoc), поскольку не хранятся в самой базе данных и служат узкоспециализированным целям.
Язык четвертого поколения позволяет создавать схемы — точные определения данных и отношений между ними. Схема хранится как часть базы данных и может быть изменена без ущерба для данных.
Схема предназначена для контроля целостности данных. Если, к примеру, объявлено, что поле содержит целочисленные значения, то СУБД откажется записывать в него числа с плавающей запятой или строки. Отношения между записями тоже четко контролируются, и несогласованные данные не допускаются. Операции можно группировать в транзакции, выполняемые по принципу "все или ничего".
СУБД обеспечивает безопасность данных. Пользователям предоставляются определенные права доступа к информации. Некоторым пользователям разрешено лишь просматривать данные, тогда как другие пользователи могут менять содержимое таблиц.
СУБД поддерживает параллельный доступ к базе данных. Приложения могут обращаться к базе данных одновременно, что повышает общую производительность системы. Кроме того, отдельные операции могут "распараллеливаться" для еще большего улучшения производительности.
Наконец, СУБД помогает восстанавливать информацию в случае непредвиденного сбоя, незаметно для пользователей создавая резервные копии данных. Все изменения, вносимые в базу данных, регистрируются, поэтому многие операции можно отменять и выполнять повторно.
Инсталляция с помощью менеджера пакетов RedHat Linux
Если программа MySQL инсталлируется в Linux, то лучше всего воспользоваться модулем RPM (RedHat Packet Manager— менеджер пакетов RedHat). MySQL работает в Linux версий 2.0 и выше. Тестирование программы выполнялось в RedHat 6.2. В программе используется библиотека glibc, подключаемая статически. Если в системе установлена более старая версия библиотеки, программу придется скомпилировать заново.
В таблице 2.1 приведено описание доступных модулей RPM (для последней версии пакета MySql 4.01.10, на момент создания этого материала)
Таблица 2.1.
MySQL-4.01.10-1.1386.rpm
Содержит все файлы, необходимые для запуска сервера MySQL, включая клиентские программы.
MySQL-4.01.10-l.src.rpm
Содержит все исходные коды MySQL
MySQL-bench-4.01.10-1.1386.rpm
Содержит программы, предназначенные для тестирования производительности MySQL. Для запуска тестов необходим основной дистрибутив, а также интерпретатор Perl.
MySQL-client-4.01.10-1.1386.rpm
Содержит лишь клиентские программы
MySQL-devel-4.01.10-1.1386.rpm
Содержит библиотеки и файлы заголовков, необходимые для компиляции клиентских программ
MySQL-shared-4.01.10-1.1386.rpm
Содержит совместно используемые библиотеки для клиентских программ
Опытные пользователи Linux знают, что флаг -i служит программе rpm указанием инсталлировать пакет. Таким образом, основной модуль MySQL инсталлируется следующей командой:
rpm -i MySQL-4.01.10-1.1386.rpm
В результате инсталляции в каталог /etc/rc.d добавляется файл сценария, содержащий команду запуска сервера MySQL после перезагрузки компьютера. Однако сам серверный демон запускается немедленно.
По окончании инсталляции потребуется изменить стандартные привилегии доступа к базам данных, о чем пойдет речь в конце лекции.
Можно также инсталлировать модуль RPM с исходными кодами программы. В этом случае воспользуйтесь опцией --rebuild, чтобы подготовить бинарный модуль.
Обычно пользователи инсталлируют лишь модули MySQL-4.01.10-1.i386.rpm и MySQL-client-4.01.10-l.i386.rpm. Для тех, кто собираются писать собственные клиентские программы, потребуется также модуль MySQL-devel-4.01.10-1.i386.rpm.
Инсталляция в Windows
Программа MySQL распространяется и в виде ZIP-архива, содержащего набор инсталляционных файлов. Перед извлечением файлов из архива создайте отдельный каталог, например с:\windows\mysql, так как в архиве нет информации о путевых именах файлов.
Чтобы приступить к инсталляции, выполните двойной щелчок на файле setup.ехе, после чего начнут появляться различные диалоговые окна. Первый вопрос, на который предстоит ответить, касается папки, куда должна быть помещена программа. По умолчанию предлагается папка с:\mysql. Можно выбрать любую другую папку, но в таком случае придется отредактировать конфигурационный файл.
Следующий вопрос касается инсталлируемых компонентов. Если выбрать "типичную" инсталляцию, будут инсталлированы серверный модуль, справочные файлы, а также набор файлов, содержащих описание стандартных привилегий доступа. В случае инсталляции "на выбор" можно будет дополнительно установить утилиты тестирования и библиотеки функций разработки.
Далее начнется собственно установка программы. Если инсталляционный каталог называется не с:\mysql, то по окончании инсталляции нужно будет дополнительно установить файл my.ini. Для этого перейдите в каталог программы и найдите файл my-example.cnf. Скопируйте его в системный каталог (с:\windows) и переименуйте в my.ini. Можно поступить и по-другому: скопировать файл в корневой раздел диска С: и назвать его my.cnf.
Теперь нужно отредактировать этот файл, чтобы переменная basedir указывала на инсталляционный каталог. Если соответствующая строка присутствует в виде комментария, удалите символы комментария. В противном случае добавьте эту строку самостоятельно, например:
basedir = d:\mysql
Если программа MySQL инсталлируется в Windows 2000 (XP), то, возможно, ее нужно запустить в виде сервиса. Для этого требуется перейти в режим командной строки и ввести следующую команду:
c:\mysql\bin\mysqld-nt --install
Название сервиса появится в окне сервисов панели управления, где можно будет настроить программу на автоматический запуск. Утилита winmysqladmin, входящая в Windows-дистрибутив, позволяет автоматизировать множество задач, включая конфигурацию.
Если Вы хотите запустить MySql вручную, то Вам потребуется выполнить следующую последовательность действий:
запустите сеанс MS-DOS и перейдите в каталог c:\mysql\binвведите в строке приглашения:
mysqld-shareware --standalone
или (в зависимости от версии)
mysqld
тем самым будет запущен сервер MySQL.
введите "mysql" (без кавычек) в приглашении DOS.приглашение изменится на приглашение "mysql".чтобы протестировать сервер MySQL, введите в строке приглашения "show databases;"на экране должно появиться окно, изображенное на рис 2.1
Рис. 2.1. Запуск MySql
Если появится подобный результат, то можно считать, что установка системы MySQL успешно завершена.
введите "quit" в приглашении mysql.снова появится приглашение MS-DOS.так как в данный момент работа закончена, необходимо остановить сервер MySQL. выполните в приглашении следующую команду.
mysqladmin -u root shutdown
Инсталляция вручную
Если программа MySQL инсталлируется не в Linux или Windows либо если услуги менеджера пакетов не нужны, можно инсталлировать двоичные файлы вручную. Соответствующий дистрибутив распространяется в виде tar-архива, сжатого с помощью программы gzip.
Первый этап заключается в добавлении нового пользователя, от имени которого будет работать демон MySQL. Естественно, это не должен быть пользователь root.
Программе MySQL нельзя предоставлять права суперпользователя, и никакие компромиссы здесь недопустимы. Можно, например, создать группу mysql и одноименного пользователя с помощью команд addgroup и adduser либо groupadd и useradd, в зависимости от версии UNIX. Ниже показан пример для RedHat Linux:
groupadd mysql useradd -g mysql mysql
Обычно начальным каталогом MySQL выбирают /usr/local/mysql. После распаковки архива будет создан каталог, имя которого совпадает с именем дистрибутива, поэтому удобнее всего просто создать символическую ссылку mysql. Вот как это делается:
cd /usr/local tar xvfz mysql-4.01.10-pc-linux-gnu-i686.tar.gz ln -s mysql-4.01.10-pc-linux-gnu-i686 mysql cd mysql
Далее необходимо запустить сценарий mysql_install_db, находящийся в каталоге scripts. Он создаст базу данных с описанием существующих привилегий и тестовую базу данных.
Как правило, программа MySQL инсталлируется от имени пользователя root, поэтому следующий шаг заключается в изменении владельца всех файлов программы:
chown -R mysql /usr/local/mysql chgrp -R mysql /usr/local/mysql
Теперь можно запустить демон MySQL с помощью сценария safe_mysqld. Следующая команда запускает демон от имени пользователя mysql:
/usr/local/mysql/bin/safe_mysqld --user=mysql &
Если нужно, чтобы сервер MySQL запускался всякий раз после перезагрузки компьютера, добавьте соответствующую строку в файл /etc/rc.d/rc.local или же скопируйте сценарий mysql.server в каталог /etc/init.d и создайте правильные символические ссылки на него. В комментариях к файлу support-files/mysql.server рекомендуются такие ссылки:
/etc/rc3.d/S99mysql
и
/etc/rcO.d/SOlmysql.
Чтобы запустить программу клиента mysql вручную, введем в строке приглашения команду:
mysql -u root -p
Система попросит ввести пароль. Введите пароль для root (mysqldata).
Если приглашение ввести пароль не появилось, то это может означать, что сервер MySQL не работает. Чтобы запустить сервер, перейдите в каталог /etc/rc.d/init.d/ и выполните команду ./mysql start (или mysql start, в зависимости от значения переменной PATH). Затем вызовите программу клиента mysql.
Если клиент MySQL работает, то появится приглашение mysql>. Введите в строке приглашения следующее:
show databases;
На экране должен появиться вывод, как на рис. 2.1.
Теперь можно считать, что система MySQL успешно установлена в Linux.
Компиляция программы
Если в вашем распоряжении имеются исходные коды программы, создайте из них двоичные файлы и следуйте приведенным выше инструкциям. Поскольку исходные тексты были подготовлены с помощью утилиты autoconf, для компиляции программы нужно будет ввести последовательность команд configure, make и make install.
По возможности следует избегать перекомпиляции программы. Разработчики MySQL досконально знают все тонкости процесса компиляции, поэтому они умеют создавать максимально оптимизированные исполняемые файлы.
При компиляции исходных кодов появляется возможность подключить компоненты, не встроенные в стандартные инсталляционные пакеты. Для некоторых из них требуются библиотеки функций разработки. Инсталлируйте их до начала компиляции программы.
Предоставление привилегий
Сценарий mysql_install_db предоставляет любому пользователю локального компьютера привилегии, позволяющие регистрироваться на сервере баз данных. Сетевые соединения не допускаются. По умолчанию любой пользователь имеет доступ к базе test, а пользователь root имеет полный доступ ко всем базам данных. Если в какой-то из баз хранится важная информация, нужно назначить суперпользователю пароль.
Программа MySQL не работает со списком пользователей, который есть у операционной системы. У нее своя таблица пользователей. Тем не менее, если при работе с имеющимися клиентскими программами не ввести имя пользователя в процессе регистрации на сервере, будет подставлено системное имя пользователя.
Чтобы поменять пароль пользователя root, нужно запустить интерпретатор команд MySQL от имени суперпользователя. Данный интерпретатор представляет собой программу mysql, путь к которой должен быть указан в переменной среды PATH.
Пользователям Windows придется вводить путевое имя целиком, например c:\mysql\bin\mysql. С помощью опции --user задается имя для регистрации. В нашем случае интерпретатор запускается с помощью такой команды:
mysql --user=root mysql
Вызвав интерпретатор, необходимо обновить две строки в таблице user, касающиеся пользователя root. Это делает следующая инструкция:
UPDATE user SET Password = PASSWORD('secret') WHERE User = 'root';
В ответ на эту инструкцию интерпретатор отобразит две модифицируемые записи. Естественно, вместо строки 'secret' следует выбрать более надежный пароль. Этот пароль должен применяться лишь в административных целях.
Далее нужно сообщить серверу об изменении привилегий. Для этого предназначена такая инструкция:
FLUSH PRIVILEGES;
Любой пользователь может захотеть создать персональную базу данных для собственных экспериментов, но делать это разрешено только пользователю root. Он же может создавать учетные записи новых пользователей и предоставлять им необходимые привилегии. Рассмотрим пример:
CREATE DATABASE mybase; GRANT ALL ON freak.* TO freak @'%' IDENTIFIED BY PASSWORD('secret');
Первая инструкция создает базу данных mybase. Вторая инструкция создает учетную запись пользователя freak и предоставляет ему доступ к одноименной базе данных. Пароль для доступа — 'secret'. Пользователь freak может подключаться к базе данных с любого компьютера, даже если он расположен в сети Internet.
В следующей лекции мы перейдем к рассмотрению основ собственно системы MySQL.
Проверка исходных требований
Если инсталлируются двоичные файлы, следует убедиться в том, что система соответствует исходным требованиям программы. Важным моментом является поддержка потоков. При инсталляции в старых версиях некоторых операционных систем MySQL требует наличия отдельной библиотеки потоковых функций POSIX. POSIX — это международный стандарт, определяющий работу системных сервисов, а потоки — это механизм, позволяющий программам выполнять несколько задач одновременно. Современные операционные системы поддерживают стандарт POSIX. Если вы все же не уверены, проверьте в интерактивной документации, будет ли программа MySQL работать в данной версии операционной системы.
Выбор версии
Команда разработчиков MySQL публикует тестовые и стабильные версии дистрибутивов отдельно. Информацию о статусе той или иной версии программы можно найти на Web-узле. Эти же сведения закодированы в названии дистрибутива.
В целом лучше выбирать самую новую версию. Исключение составляют лишь альфа-версии, в которых впервые вводятся новые функциональные возможности. Программа MySQL отвечает самым высоким критериям качества и надежности, поэтому ее бета-версии зачастую вполне сопоставимы с финальными версиями других программ.
Загрузка MySQL
MySQL можно инсталлировать двумя способами: скомпилировав исходные коды программы или воспользовавшись предварительно скомпилированными двоичными файлами. Первый вариант допускает больше возможностей в плане конфигурации, но более продолжителен. Второй вариант удобнее, так как есть готовые дистрибутивы для многих операционных систем. На текущий момент существуют версии MySQL для FreeBSD, HP-UX, IBM AIX, Linux, MacOS X, SCO, SGI Irix, Solaris и многих вариантов Microsoft Windows.
Информацию обо всех дистрибутивах можно получить на Web-узле http://www.mysql.com. Там же публикуются последние новости о программе.
Использование базы данных
База данных employees уже создана. Для работы с ней, необходимо её "активировать" или "выбрать". В приглашении mysql выполните команду:
SELECT DATABASE();
На экране увидим ответ системы, как показано на рис. 3.5
Рис. 3.5. Выбор базы данных
Это говорит о том, что ни одна база данных не была выбрана. На самом деле всякий раз при работе с клиентом mysql необходимо определять, какая база данных будет использоваться.
Определить текущую базу данных можно несколькими способами:
определение имени базы данных при запуске
Введите в приглашении системы следующее:
mysql employees (в Windows) mysql employees -u manish -p (в Linux) определение базы данных с помощью оператора USE в приглашении mysql
mysql>USE employees; Определение базы данных с помощью \u в приглашении mysql
mysql>\u employees;
При работе необходимо определять базу данных, которая будет использоваться, иначе MySQL будет порождать ошибку.
Команда CREATE DATABASE
Синтаксис команды CREATE DATABASE имеет вид:
CREATE DATABASE [IF NOT EXISTS] имя_базы_данных [спецификация_create[,спецификация_create]...]
Команда CREATE DATABASE создает базу данных с указанным именем. Для использования команды необходимо иметь привилегию CREATE для базы данных. Если база данных с таким именем существует, генерируется ошибка.
спецификация_create: [DEFAULT] CHARACTER SET имя_набора_символов [DEFAULT] COLLATE имя_порядка_сопоставления
Опция спецификация_сrеаtе может указываться для определения характеристик базы данных. Характеристики базы данных сохраняются в файле db.opt, расположенном в каталоге данных. Конструкция CHARACTER SET определяет набор символов для базы данных по умолчанию. Конструкция COLLATION задает порядок сопоставления по умолчанию.
Базы данных в MySQL реализованы в виде каталогов, которые содержат файлы, соответствующие таблицам базы данных. Поскольку изначально в базе нет никаких таблиц, оператор CREATE DATABASE только создает подкаталог в каталоге данных MySQL.
Работа с таблицами
Теперь рассмотрим команды MySQL для создания таблиц базы данных и выбора базы данных.
Базы данных хранят данные в таблицах. Чем же являются эти таблицы?
Проще всего таблицы можно представлять себе, как состоящие из строк и столбцов. Каждый столбец определяет данные определенного типа. Строки содержат отдельные записи.
Рассмотрим таблицу 3.1, в которой приведены персональные данные некоторых людей:
Таблица 3.1. Персональные данные
ИмяВозрастСтранаe-mail
Михаил Петров
28
Россия
misha@yandex.ru
Джон Доусон
32
Австралия
j.dow@australia.com
Морис Дрюон
48
Франция
md@france.fr
Снежана
19
Болгария
sneg@bulgaria.com
Приведенная выше таблица содержит четыре столбца, в которых хранятся имя, возраст, страна, и адрес e-mail. Каждая строка содержит данные одного человека. Эта строка называется записью. Чтобы найти страну и адрес e-mail Снежаны, сначала надо выбрать имя в первом столбце, а затем посмотреть содержимое третьего и четвертого столбцов этой же строки.
База данных может содержать множество таблиц, именно таблицы содержат реальные данные.
Следовательно, можно выделить связанные (или несвязанные) данные в различные таблицы. Для базы данных employees определена одна таблица, которая содержит данные компании о сотрудниках, а другая таблица будет содержать персональные данные. Давайте создадим первую таблицу.
Команда SQL для создания такой таблицы выглядит следующим образом:
CREATE TABLE employee_data ( emp_id int unsigned not null auto_increment primary key, f_name varchar(20), l_name varchar(20), title varchar(30), age int, yos int, salary int, perks int, email varchar(60) );
Примечание: в MySQL команды и имена столбцов не различают регистр символов, однако имена таблиц и баз данных могут зависеть от регистра в связи с используемой платформой (как в Linux). Поэтому можно вместо CREATE TABLE использовать create table.
За ключевыми словами CREATE TABLE следует имя создаваемой таблицы employee_data. Каждая строка внутри скобок представляет один столбец. Эти столбцы хранят для каждого сотрудника идентификационный номер (emp_id), фамилию (f_name), имя (l_name), должность (title), возраст (age), стаж работы в компании (yos), зарплату (salary), надбавки (perks), и адрес e-mail (email).
За именем каждого столбца следует тип столбца. Типы столбцов определяют тип данных, которые будет содержать столбец. В данном примере столбцы f_name, l_name, title и email будут содержать текстовые строки, поэтому тип столбца задан как varchar, что означает переменное количество символов. Максимальное число символов для столбцов varchar определяется числом, заключенным в скобки, которое следует сразу за именем столбца. Столбцы age, yos, salary и perks будут содержать числа (целые), поэтому тип столбца задается как int. Первый столбец (emp_id) содержит идентификационный номер (id) сотрудника. Его тип столбца выглядит несколько перегруженным, поэтому рассмотрим его по частям:
int: определяет тип столбца как целое число.unsigned: определяет, что число будет без знака (положительное целое).not null: определяет, что значение не может быть null (пустым); то есть каждая строка в этом столбце должна иметь значение.auto_increment: когда MySQL встречается со столбцом с атрибутом auto_increment, то генерируется новое значение, которое на единицу больше чем наибольшее значение в столбце. Поэтому мы не должны задавать для этого столбца значения, MySQL генерирует их самостоятельно. Из этого также следует, что каждое значение в этом столбце будет уникальным.primary key: помогает при индексировании столбца, что ускоряет поиск значений. Каждое значение должно быть уникально. Ключевой столбец необходим для того, чтобы исключить возможность совпадения данных. Например, два сотрудника могут иметь одно и то же имя, и тогда встанет проблема – как различать этих сотрудников, если не задать им уникальные идентификационные номера. Если имеется столбец с уникальными значениями, то можно легко различить две записи. Лучше всего поручить присваивание уникальных значений самой системе MySQL.
Синтаксис команды CREATE TABLE
Общий формат инструкции CREATE TABLE таков:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] имя [(спецификация, ...)] [опция, ...] [ [IGNORE | REPLACE] запрос]
Флаг TEMPORARY задает создание временной таблицы, существующей в течение текущего сеанса. По завершении сеанса таблица удаляется. Временным таблицам можно присваивать имена других таблиц, делая последние временно недоступными. Спецификатор IF NOT EXIST подавляет вывод сообщений об ошибках в случае, если таблица с указанным именем уже существует. Имени таблицы может предшествовать имя базы данных, отделенное точкой. Если это не сделано, таблица будет создана в базе данных, которая установлена по умолчанию.
Чтобы задать имя таблицы с пробелами, необходимо заключить его в обратные кавычки, например 'courses list'. То же самое нужно будет делать во всех ссылках на таблицу, поскольку пробелы используются для разделения идентификаторов.
Разрешается создавать таблицы без столбцов, однако в большинстве случаев спецификация хотя бы одного столбца все же присутствует. Спецификации столбцов и индексов приводятся в круглых скобках и разделяются запятыми. Формат спецификации следующий:
имя тип [NOT NULL | NULL] [DEFAULT значение] [AUTO_INCREMENT] [KEY] [ссылка]
Типы столбцов более подробно будут рассмотрены в лекции 4.
Спецификация типа включает название типа и его размерность. По умолчанию столбцы принимают значения NULL. Спецификатор NOT NULL запрещает подобное поведение.
У любого столбца есть значение по умолчанию. Если оно не указано, программа MySQL выберет его самостоятельно. Для столбцов, принимающих значения NULL, значением по умолчанию будет NULL, для строковых столбцов — пустая строка, для численных столбцов — нуль. Изменить эту установку позволяет предложение DEFAULT.
Поля-счетчики, создаваемые с помощью флага AUTO_INCREMENT, игнорируют значения по умолчанию, так как в них записываются порядковые номера. Тип счетчика должен быть беззнаковым целым. В таблице может присутствовать лишь одно поле-счетчик. Им не обязательно является первичный ключ.
Синтаксис команды DROP TABLE
Инструкция DROP TABLE имеет следующий синтаксис:
DROP TABLE [IF EXISTS] таблица [RESTRICT | CASCADE]
Спецификация IF EXISTS подавляет вывод сообщения об ошибке, выдаваемого в случае, если заданная таблица не существует. Можно указывать несколько имен таблиц, разделяя их запятыми.
Флаги RESTRICT и CASCADE предназначены для выполнения сценариев, созданных в других СУБД.
Создание базы данных в Linux
1. Пусть пользователь работает под своей учетной записью, а не как суперпользователь root. Необходимо запустить терминальный сеанс и стать суперпользователем (Для этого выполните команду su и введите пароль суперпользователя root).
2. Запустим сервер MySQL. Вводим:
mysql -u root -p
Система предлагает ввести пароль пользователя root MySQL, который был задан при установке MySQL в Linux. (Примечание: Это пароль пользователя root системы MySQL, а не пользователя root системы Linux). Введите пароль, который не изображается на экране по соображениям безопасности.
После успешной регистрации, система выводит приветствие и приглашение mysql, как показано на рис.3.3
Рис. 3.3. Приветствие системы
(Вас приветствует монитор MySQL. Команды заканчиваются символами ; или \g. id соединения с MySQL равен 1 для сервера версии: 5.01.01. Введите 'help', чтобы получить справку).
3. Теперь можно создавать базу данных employees. Выполните команду:
create database employees;
(Примечание: команда заканчивается точкой с запятой)
4. Важно отметить, что эта база данных создается пользователем root и поэтому будет доступна только тем пользователям, которым это разрешит root. Чтобы использовать эту базу данных с другой учетной записью, например, misha, необходимо задать соответствующие полномочия, выполняя следующую команду:
GRANT ALL ON employees.* TO freak@localhost IDENTIFIED BY "pass"
Эта команда предоставляет учетной записи freak@localhost все полномочия на базу данных employees и задает пароль pass. Для любого другого пользователя freak можно заменить на любое другое имя пользователя и выбрать подходящий пароль.
5. Закройте сеанс mysql, вводя в приглашении команду quit. Выйдите из режима суперпользователя и перейдите в свою учетную запись. (Введите exit).
6. Чтобы соединиться с MySQL с помощью обычной учетной записи, введите:
mysql -u имя_пользователя -p
Затем введите после приглашения пароль. (Этот пароль был задан выше командой GRANTS ALL...). После успешной регистрации в MySQL система выведет приветственное сообщение. Сеанс пользователя должен выглядеть как показано на рис. 3.4.
Рис. 3.4. Приветствие системы MySQL
7. Ввод команды SHOW DATABASES; выведет список всех доступных в системе баз данных.
mysql> SHOW DATABASES;
На экране должно появиться окно, аналогичное рис. 3.2.
Введите quit в строке приглашения mysql>, чтобы выйти из программы клиента mysql.
Создание базы данных в Windows
1. Запустите сервер MySQL, выполняя команду mysqld-shareware -standalone в строке приглашения в каталоге c:\mysql\bin. Более подробно об этом сказано выше, в лекции об установке MySQL в Windows.
2. Затем вызовите программу клиента mysql, вводя в строке приглашения mysql.
3. Приглашение изменится на mysql>. Введите команду:
create database employees;
(Примечание: Команда заканчивается символом точки с запятой).
4. Сервер MySQL должен ответит примерно как на рис. 3.1
Рис. 3.1. Результат работы команды создания таблицы
5. Это означает, что была успешно создана база данных. Теперь давайте посмотрим, сколько баз данных имеется в системе. Выполните следующую команду.
show databases;
Сервер ответит списком баз данных, как показано на рис. 3.2.
Рис. 3.2. Просмотр баз данных
Здесь показаны три базы данных, две были созданы MySQL во время установки и вновь созданная база данных employees.
6. Чтобы вернуться снова к приглашению DOS, введите команду quit в приглашении mysql.
Создание таблицы
После выбора базы данных employees, выполните в приглашении mysql команду CREATE TABLE.
CREATE TABLE employee_data ( emp_id int unsigned not null auto_increment primary key, f_name varchar(20), l_name varchar(20), title varchar(30), age int, yos int, salary int, perks int, email varchar(60) );
Примечание: нажатие клавиши Enter после ввода первой строки изменяет приглашение mysql на ->. Это означает, что mysql понимает, что команда не завершена и приглашает ввести дополнительные операторы. Помните, что каждая команда mysql заканчивается точкой с запятой, а каждое объявление столбца отделяется запятой. Можно также при желании ввести всю команду на одной строке.
Вывод на экране должен соответствовать рис. 3.6.
Рис. 3.6. Создание таблицы
Удаление таблиц
Для того, чтобы удалить таблицу, убедимся сперва что она существует. Это можно проверить с помощью команды SHOW TABLES, как показано на рис. 3.7.
Рис. 3.7. Просмотр таблиц в базе
Для удаления таблицы используется команда DROP TABLE, как показано на рис. 3.8.
Рис. 3.8. Удаление таблицы
Теперь команда SHOW TABLES; этой таблицы больше не покажет.
Числовые типы данных
MySQL поддерживает все числовые типы данных языка SQL92 по стандартам ANSI/ISO. Они включают в себя типы точных числовых данных (NUMERIC, DECIMAL, INTEGER и SMALLINT) и типы приближенных числовых данных (FLOAT, REAL и DOUBLE PRECISION). Ключевое слово INT является синонимом для INTEGER, а ключевое слово DEC - синонимом для DECIMAL.
Типы данных NUMERIC и DECIMAL реализованы в MySQL как один и тот же. Они используются для величин, для которых важно сохранить повышенную точность, например для денежных данных. Требуемая точность данных и масштаб могут задаваться (и обычно задаются) при объявлении столбца данных одного из этих типов, например:
salary DECIMAL(5,2)
В этом примере - 5 (точность) представляет собой общее количество значащих десятичных знаков, с которыми будет храниться данная величина, а цифра 2 (масштаб) задает количество десятичных знаков после запятой. Следовательно, в этом случае интервал величин, которые могут храниться в столбце salary, составляет от -99,99 до 99,99 (в действительности для данного столбца MySQL обеспечивает возможность хранения чисел вплоть до 999,99, поскольку можно не хранить знак для положительных чисел).
Величины типов DECIMAL и NUMERIC хранятся как строки, а не как двоичные числа с плавающей точкой, чтобы сохранить точность представления этих величин в десятичном виде. При этом используется по одному символу строки для каждого разряда хранимой величины, для десятичного знака (если масштаб > 0) и для знака '-' (для отрицательных чисел). Если параметр масштаба равен 0, то величины DECIMAL и NUMERIC не содержат десятичного знака или дробной части.
Максимальный интервал величин DECIMAL и NUMERIC тот же, что и для типа DOUBLE, но реальный интервал может быть ограничен выбором значений параметров точности или масштаба для данного столбца с типом данных DECIMAL или NUMERIC. Если конкретному столбцу присваивается значение, имеющее большее количество разрядов после десятичного знака, что разрешено параметром масштаба, то данное значение округляется до количества разрядов, разрешенного масштаба. Если столбцу с типом DECIMAL или NUMERIC присваивается значение, выходящее за границы интервала, заданного значениями точности и масштаба (или принятого по умолчанию), то MySQL сохранит данную величину со значением соответствующей граничной точки данного интервала.
Все типы целочисленных данных могут иметь необязательный и не оговоренный в стандарте атрибут UNSIGNED. Беззнаковые величины можно использовать для разрешения записи в столбец только положительных чисел, если необходимо немного увеличить числовой интервал в столбце.
Тип FLOAT обычно используется для представления приблизительных числовых типов данных. Если ключевое слово FLOAT в обозначении типа столбца используется без указания точности, MySQL выделяет 4 байта для хранения величин в этом столбце. Возможно также иное обозначение, с двумя числами в круглых скобках за ключевым словом FLOAT. В этом варианте первое число по-прежнему определяет требования к хранению величины в байтах, а второе число указывает количество разрядов после десятичной запятой, которые будут храниться и показываться. Если в столбец подобного типа попытаться записать число, содержащее больше десятичных знаков после запятой, чем указано для данного столбца, то значение величины при ее хранении в MySQL округляется для устранения излишних разрядов.
Для типов REAL и DOUBLE PRECISION не предусмотрены установки точности. В MySQL оба типа реализуются как 8-байтовые числа с плавающей точкой удвоенной точности. Чтобы обеспечить максимальную совместимость, в коде, требующем хранения приблизительных числовых величин, должны использоваться типы FLOAT или DOUBLE PRECISION без указаний точности или количества десятичных знаков.
Если в числовой столбец попытаться записать величину, выходящую за границы допустимого интервала для столбца данного типа, то MySQL ограничит величину до соответствующей граничной точки данного интервала и сохранит результат вместо исходной величины.
Например, интервал столбца INT составляет от -2147483648 до 2147483647. Если попытаться записать в столбец INT число -9999999999, то оно будет усечено до нижней конечной точки интервала и вместо записываемого значения в столбце будет храниться величина -2147483648. Аналогично, если попытаться записать число 9999999999, то взамен запишется число 2147483647.
Если для столбца INT указан параметр UNSIGNED, то величина допустимого интервала для столбца останется той же, но его граничные точки сдвинутся к 0 и 4294967295. Если попытаться записать числа -9999999999 и 9999999999, то в столбце окажутся величины 0 и 4294967296.
Для команд ALTER TABLE, LOAD DATA INFILE, UPDATE и многострочной INSERT выводится предупреждение, если могут возникнуть преобразования данных вследствие вышеописанных усечений. В таблице 4.2 представлены наиболее часто используемые числовые типы полей MySql.
Таблица 4.2. Наиболее часто используемые числовые типы полей MySql.
ТипБайтОтДо
TINYINT
1
-128
127
SMALLINT
2
-32768
32767
MEDIUMINT
3
-8388608
8388607
INT
4
-2147483648
2147483647
BIGINT
8
-9223372036854775808
9223372036854775807
Символьные типы данных
Существуют следующие символьные типы данных: CHAR, VARCHAR, BLOB, TEXT, ENUM и SET. Рассмотрим описание их работы, требований к их хранению и использования их в запросах. В таблице 4.5 приведены символьные типы данных и их размерность.
Таблица 4.5. Символьные типы данных
ТипМакс.размерБайт
TINYTEXT или TINYBLOB
2^8-1
255
TEXT или BLOB
2^16-1 (64K-1)
65535
MEDIUMTEXT или MEDIUMBLOB
2^24-1 (16M-1)
16777215
LONGBLOB
2^32-1 (4G-1)
4294967295
Тип данных TIME
MySQL извлекает и выводит величины типа TIME в формате 'HH:MM:SS' (или в формате 'HHH:MM:SS' для больших значений часов). Величины TIME могут изменяться в пределах от '-838:59:59' до '838:59:59'. Причина того, что "часовая" часть величины может быть настолько большой, заключается в том, что тип TIME может использоваться не только для представления времени дня (которое должно быть меньше 24 часов), но также для представления общего истекшего времени или временного интервала между двумя событиями (который может быть значительно больше 24 часов или даже отрицательным).
Величины TIME могут быть заданы в различных форматах:
Как строка в формате 'D HH:MM:SS.дробная часть' (следует учитывать, что MySQL пока не обеспечивает хранения дробной части величины в столбце рассматриваемого типа). Можно также использовать одно из следующих "облегченных" представлений: HH:MM:SS.дробная часть, HH:MM:SS, HH:MM, D HH:MM:SS, D HH:MM, D HH или SS. Здесь D - это дни из интервала значений 0-33.
Как строка без разделителей в формате 'HHMMSS', при условии, что строка интерпретируется как дата. Например, величина '101112' понимается как '10:11:12', но величина '109712' будет недопустимой (значение раздела минут является абсурдным) и преобразуется в '00:00:00'.Как число в формате HHMMSS, при условии, что строка интерпретируется как дата. Например, величина 101112 понимается как '10:11:12'. MySQL понимает и следующие альтернативные форматы: SS, MMSS, HHMMSS, HHMMSS.дробная часть. При этом следует учитывать, что хранения дробной части MySQL пока не обеспечивает.Как результат выполнения функции, возвращающей величину, приемлемую в контексте типа данных типа TIME (например, такой функции, как CURRENT_TIME).
Тип данных YEAR
Тип YEAR - это однобайтный тип данных для представления значений года.
MySQL извлекает и выводит величины YEAR в формате YYYY. Диапазон возможных значений - от 1901 до 2155.
Величины типа YEAR могут быть заданы в различных форматах:
Как четырехзначная строка в интервале значений от '1901' до '2155'.Как четырехзначное число в интервале значений от 1901 до 2155.Как двухзначная строка в интервале значений от '00' до '99'. Величины в интервалах от '00' до '69' и от '70' до '99' при этом преобразуются в величины YEAR в интервалах от 2000 до 2069 и от 1970 до 1999 соответственно.Как двухзначное число в интервале значений от 1 до 99. Величины в интервалах от 1 до 69 и от 70 до 99 при этом преобразуются в величины YEAR в интервалах от 2001 до 2069 и от 1970 до 1999 соответственно. Необходимо принять во внимание, что интервалы для двухзначных чисел и двухзначных строк несколько различаются, так как нельзя указать "ноль" непосредственно как число и интерпретировать его как 2000. Необходимо задать его как строку '0' или '00', или же оно будет интерпретировано как 0000.Как результат выполнения функции, возвращающей величину, приемлемую в контексте типа данных YEAR (такой как NOW()).
Недопустимые величины YEAR преобразуются в 0000.
Тип множества SET
SET - это строковый тип, который может принимать ноль или более значений, каждое из которых должно быть выбрано из списка допустимых значений, определенных при создании таблицы. Элементы множества SET разделяются запятыми. Как следствие, сами элементы множества не могут содержать запятых.
Например, столбец, определенный как SET("один", "два") NOT NULL может принимать такие значения:
"" "один" "два" "один,два"
Множество SET может иметь максимум 64 различных элемента.
Оконечные пробелы удаляются из значений множества SET в момент создания таблицы.
Если вы вставляете в столбец SET некорректную величину, это значение будет проигнорировано.
Если вам нужно получить все возможные значения для столбца SET, вам следует вызвать SHOW COLUMNS FROM table_name LIKE set_column_name и проанализировать SET-определение во втором столбце.
Тип перечисления ENUM
ENUM (перечисление) - это столбец, который может принимать значение из списка допустимых значений, явно перечисленных в спецификации столбца в момент создания таблицы.
Перечисление может иметь максимум 65535 элементов.
Регистр не играет роли, когда вы делаете вставку в столбец ENUM. Однако регистр значений, получаемых из этого столбца, совпадает с регистром в написании соответствующего значения, заданного во время создания таблицы.
Если вам нужно получить список возможных значений для столбца ENUM, вы должны вызвать SHOW COLUMNS FROM имя_таблицы LIKE имя_столбца_enum и проанализировать определение ENUM во втором столбце.
Типы данных BLOB и TEXT
Тип данных BLOB представляет собой двоичный объект большого размера, который может содержать переменное количество данных. Существуют 4 модификации этого типа - TINYBLOB, BLOB, MEDIUMBLOB и LONGBLOB, отличающиеся только максимальной длиной хранимых величин.
Тип данных TEXT также имеет 4 модификации - TINYTEXT, TEXT, MEDIUMTEXT и LONGTEXT, соответствующие упомянутым четырем типам BLOB и имеющие те же максимальную длину и требования к объему памяти. Единственное различие между типами BLOB и TEXT состоит в том, что сортировка и сравнение данных выполняются с учетом регистра для величин BLOB и без учета регистра для величин TEXT. Другими словами, TEXT - это независимый от регистра BLOB.
Если размер задаваемого в столбце BLOB или TEXT значения превосходит максимально допустимую длину столбца, то это значение соответствующим образом усекается.
Типы данных CHAR и VARCHAR
Типы данных CHAR и VARCHAR очень схожи между собой, но различаются по способам их хранения и извлечения.
В столбце типа CHAR длина поля постоянна и задается при создании таблицы. Эта длина может принимать любое значение между 1 и 255. Величины типа CHAR при хранении дополняются справа пробелами до заданной длины. Эти концевые пробелы удаляются при извлечении хранимых величин.
Величины в столбцах VARCHAR представляют собой строки переменной длины. Так же как и для столбцов CHAR, можно задать столбец VARCHAR любой длины между 1 и 255. Однако, в противоположность CHAR, при хранении величин типа VARCHAR используется только то количество символов, которое необходимо, плюс один байт для записи длины. Хранимые величины пробелами не дополняются, наоборот, концевые пробелы при хранении удаляются.
Если задаваемая в столбце CHAR или VARCHAR величина превосходит максимально допустимую длину столбца, то эта величина соответствующим образом усекается.
Различие между этими двумя типами столбцов в представлении результата хранения величин с разной длиной строки в столбцах CHAR(4) и VARCHAR(4) проиллюстрировано следующей таблицей 4.6.
Таблица 4.6. Результат хранения величин с разной длиной строки типов Char и Varchar
ВеличинаCHAR(4)Требуемая памятьVARCHAR(4)Требуемая память
''
' '
4 байта
''
1 байт
'ab'
'ab '
4 байта
'ab'
3 байта
'abcd'
'abcd'
4 байта
'abcd'
5 байтов
'abcdefgh'
'abcd'
4 байта
'abcd'
5 байтов
Извлеченные из столбцов CHAR(4) и VARCHAR(4) величины в каждом случае будут одними и теми же, поскольку при извлечении концевые пробелы из столбца CHAR удаляются.
Если при создании таблицы не был задан атрибут BINARY для столбцов, то величины в столбцах типа CHAR и VARCHAR сортируются и сравниваются без учета регистра. При задании атрибута BINARY величины в столбце сортируются и сравниваются с учетом регистра в соответствии с порядком таблицы ASCII на том компьютере, где работает сервер MySQL.
Типы данных DATETIME, DATE и TIMESTAMP
Далее рассмотрим типы DATETIME, DATE и TIMESTAMP, которые являются родственными типами данных. Опишем их свойства, общие черты и различия.
Тип данных DATETIME используется для величин, содержащих информацию как о дате, так и о времени. MySQL извлекает и выводит величины DATETIME в формате 'YYYY-MM-DD HH:MM:SS'. Поддерживается диапазон величин от '1000-01-01 00:00:00' до '9999-12-31 23:59:59'. ("поддерживается" означает, что хотя величины с более ранними временными значениями, возможно, тоже будут работать, но нет гарантии того, что они будут правильно храниться и отображаться).
Тип DATE используется для величин с информацией только о дате, без части, содержащей время. MySQL извлекает и выводит величины DATE в формате 'YYYY-MM-DD'. Поддерживается диапазон величин от '1000-01-01' до '9999-12-31'.
Тип столбца TIMESTAMP обеспечивает тип представления данных, который можно использовать для автоматической записи текущих даты и времени при выполнении операций INSERT или UPDATE. При наличии нескольких столбцов типа TIMESTAMP только первый из них обновляется автоматически.
Для остальных (кроме первого) столбцов типа TIMESTAMP также можно задать установку в значение текущих даты и времени. Для этого необходимо просто установить столбец в NULL или в NOW().
Любой столбец типа TIMESTAMP (даже первый столбец данного типа) можно установить в значение, отличное от текущих даты и времени. Это делается путем явной установки его в желаемое значение. Данное свойство можно использовать, например, если необходимо установить столбец TIMESTAMP в значение текущих даты и времени при создании строки, а при последующем обновлении этой строки значение столбца не должно изменяться:
Величины типа TIMESTAMP могут принимать значения от начала 1970 года до некоторого значения в 2037 году с разрешением в одну секунду. Эти величины выводятся в виде числовых значений.
Формат данных, в котором MySQL извлекает и показывает величины TIMESTAMP, зависит от количества показываемых символов. Это проиллюстрировано в таблице 4.4. Полный формат TIMESTAMP составляет 14 десятичных разрядов, но можно создавать столбцы типа TIMESTAMP и с более короткой строкой вывода:
Таблица 4.4. Формат данных TIMESTAMP в зависимости от количества извлекаемых разрядов
Тип столбцаФормат вывода
TIMESTAMP(14)
YYYYMMDDHHMMSS
TIMESTAMP(12)
YYMMDDHHMMSS
TIMESTAMP(10)
YYMMDDHHMM
TIMESTAMP(8)
YYYYMMDD
TIMESTAMP(6)
YYMMDD
TIMESTAMP(4)
YYMM
TIMESTAMP(2)
YY
<
/p>
Величины DATETIME, DATE и TIMESTAMP могут быть заданы любым стандартным набором форматов:
Как строка в формате 'YYYY-MM-DD HH:MM:SS' или в формате 'YY-MM-DD HH:MM:SS'. Допускается "облегченный" синтаксис - можно использовать любой знак пунктуации в качестве разделительного между частями разделов даты или времени. Например, величины '98-12-31 11:30:45', '98.12.31 11+30+45', '98/12/31 11*30*45' и '98@12@31 11^30^45' являются эквивалентными.Как строка в формате 'YYYY-MM-DD' или в формате 'YY-MM-DD'. Здесь также допустим "облегченный" синтаксис. Например, величины '98-12-31', '98.12.31', '98/12/31' и '98@12@31' являются эквивалентными.Как строка без разделительных знаков в формате 'YYYYMMDDHHMMSS' или в формате 'YYMMDDHHMMSS', при условии, что строка понимается как дата. Например, величины '19970523091528' и '970523091528' можно интерпретировать как '1997-05-23 09:15:28', но величина '971122129015' является недопустимой (значение раздела минут является абсурдным) и преобразуется в '0000-00-00 00:00:00'.Как строка без разделительных знаков в формате 'YYYYMMDD' или в формате 'YYMMDD', при условии, что строка интерпретируется как дата. Например, величины '19970523' и '970523' можно интерпретировать как '1997-05-23', но величина '971332' является недопустимой (значения разделов месяца и дня не имеют смысла) и преобразуется в '0000-00-00'.Как число в формате YYYYMMDDHHMMSS или в формате YYMMDDHHMMSS, при условии, что число интерпретируется как дата. Например, величины 19830905132800 и 830905132800 интерпретируются как '1983-09-05 13:28:00'.Как число в формате YYYYMMDD или в формате YYMMDD, при условии, что число интерпретируется как дата. Например, величины 19830905 и 830905 интерпретируются как '1983-09-05'.Как результат выполнения функции, возвращающей величину, приемлемую в контекстах типов данных DATETIME, DATE или TIMESTAMP (например, функции NOW() или CURRENT_DATE().
Типы данных даты и времени
Существуют следующие типы данных даты и времени: DATETIME, DATE, TIMESTAMP, TIME и YEAR. Каждый из них имеет интервал допустимых значений, а также значение "ноль", которое используется, когда пользователь вводит действительно недопустимое значение. Отметим, что MySQL позволяет хранить некоторые не вполне достоверные значения даты, например 1999-11-31. Причина в том, что управление проверкой даты входит в обязанности конкретного приложения, а не SQL-серверов. Для ускорения проверки правильности даты MySQL только проверяет, находится ли месяц в интервале 0-12 и день в интервале 0-31. Данные интервалы начинаются с 0, это сделано для того, чтобы обеспечить для MySQL возможность хранить в столбцах DATE или DATETIME даты, в которых день или месяц равен нулю. Эта возможность особенно полезна для приложений, которые предполагают хранение даты рождения - здесь не всегда известен день или месяц рождения. В таких случаях дата хранится просто в виде 1999-00-00 или 1999-01-00 (при этом не следует рассчитывать на то, что для подобных дат функции DATE_SUB() или DATE_ADD дадут правильные значения).
Ниже приведены некоторые общие рекомендации, полезные при работе с типами данных даты и времени:
MySQL извлекает значения для данного типа даты или времени только в стандартном формате, но в то же время пытается интерпретировать разнообразные форматы, которые могут поступать от пользователей (например, когда задается величина, которой следует присвоить тип даты или времени или сравнить со значением, имеющим один из этих типов). Тем не менее, поддерживаются только форматы, описанные в следующих разделах. Предполагается, что пользователь будет вводить допустимые значения величин, так как использование величин в других форматах может дать непредсказуемые результаты.
Хотя MySQL пытается интерпретировать значения в нескольких форматах, во всех случаях ожидается, что крайним слева будет раздел значения даты, содержащий год. Даты должны задаваться в порядке год-месяц-день (например, '98-09-04'), а не в порядке месяц-день-год или день-месяц-год, т.е. не так, как мы их обычно записываем (например '09-04-98', '04-09-98').MySQL автоматически преобразует значение, имеющее тип даты или времени, в число, если данная величина используется в числовом контексте, и наоборот.Значение, имеющее тип даты или времени, которое выходит за границы установленного интервала или является недопустимым для этого типа данных (см. начало раздела), преобразуется в значение "ноль" для данного типа. (Исключение составляют выходящие за границы установленного интервала величины типа TIME, которые усекаются до соответствующей граничной точки заданного интервала TIME). В таблице 4.3. представлены форматы значения "ноль" для каждого из типов столбцов:
Таблица 4.3. Нулевые значения для типов данных даты и времени
Тип столбцаЗначение "Ноль"
DATETIME
'0000-00-00 00:00:00'
DATE
'0000-00-00'
TIMESTAMP
00000000000000 (длина зависит от количества выводимых символов)
TIME
'00:00:00'
YEAR
0000
Значения 'ноль' - особые. Для их хранения или ссылок на них можно явно применять представленные в таблице значения, а можно использовать '0', что легче в написании.
Требования к памяти для различных типов столбцов
Требования к объему памяти для столбцов каждого типа, поддерживаемого MySQL, перечислены ниже по категориям.
Требования к памяти для числовых типов приведены в таблице 4.7
Таблица 4.7. Требования к памяти для числовых типов
Тип столбцаТребуемая память
TINYINT
1 byte
SMALLINT
2 байта
MEDIUMINT
3 байта
INT
4 байта
INTEGER
4 байта
BIGINT
8 байтов
FLOAT(X)
4, если X <= 24 или 8, если 25 <= X <= 53
FLOAT
4 байта
DOUBLE
8 байтов
DOUBLE PRECISION
8 байтов
REAL
8 байтов
DECIMAL(M,D)
M+2 байт, если D > 0, M+1 байт, если D = 0 (D+2, если M < D)
NUMERIC(M,D)
M+2 байт, если D > 0, M+1 байт, если D = 0 (D+2, если M < D)
Требования к памяти для типов даты и времени приведены в таблице 4.8.
Таблица 4.8. Требования к памяти для типов даты и времени
Тип столбцаТребуемая память
DATE
3 байта
DATETIME
8 байтов
TIMESTAMP
4 байта
TIME
3 байта
YEAR
1 байт
Требования к памяти для символьных типов приведены в таблице 4.9.
Таблица 4.9. Требования к памяти для символьных типов
Тип столбцаТребуемая память
CHAR(M)
M байт, 1 <= M <= 255
VARCHAR(M)
L+1 байт, где L <= M и 1 <= M <= 255
TINYBLOB, TINYTEXT
L+1 байт, где L < 2^8
BLOB, TEXT
L+2 байт, где L < 2^16
MEDIUMBLOB, MEDIUMTEXT
L+3 байт, где L < 2^24
LONGBLOB, LONGTEXT
L+4 байт, где L < 2^32
ENUM('value1','value2',...)
1 или 2 байт, в зависимости от количества перечисляемых величин (максимум 65535)
SET('value1','value2',...)
1, 2, 3, 4 или 8 байт, в зависимости от количества элементов множества (максимум 64)
Выбор правильного типа данных в столбце
Для того чтобы память использовалась наиболее эффективно, всегда следует стараться применять тип данных, обеспечивающий максимальную точность. Например, для величин в диапазоне между 1 и 99999 в целочисленном столбце наилучшим типом будет MEDIUMINT UNSIGNED.
Часто приходится сталкиваться с такой проблемой, как точное представление денежных величин. В MySQL для представления таких величин необходимо использовать тип данных DECIMAL. Поскольку данные этого типа хранятся в виде строки, потерь в точности не происходит. А в случаях, когда точность не имеет слишком большого значения, вполне подойдет и тип данных DOUBLE.
Если же требуется высокая точность, всегда можно выполнить конвертирование в тип данных с фиксированной точкой. Такие данные хранятся в виде BIGINT. Это позволяет выполнять все вычисления с ними как с целыми числами, а впоследствии при необходимости результаты можно преобразовать обратно в величины с плавающей точкой.
Операторы больше и меньше
Давайте получим имена и фамилии всех сотрудников, которые старше 32 лет.
SELECT f_name, l_name from employee_data where age > 32;
Результат запроса приведен на рис. 5.7.
Рис. 5.7. Выборка столбцов с условием "больше" для поля "возраст"
Попробуем найти сотрудников, которые получают зарплату больше 120000.
SELECT f_name, l_name from employee_data where salary > 120000;
Результат запроса приведен на рис. 5.8.
Рис. 5.8. Выборка столбцов с условием "больше" для поля "зарплата"
Теперь перечислим всех сотрудников, которые имеют стаж работы в компании менее 3 лет.
SELECT f_name, l_name from employee_data where yos < 3;
Результат запроса приведен на рис. 5.9.
Рис. 5.9. Выборка столбцов с условием "меньше" для поля "стаж"
Операторы <= и >=
Используемые в основном с целочисленными данными операторы меньше или равно (<=) и больше или равно (>=) обеспечивают дополнительные возможности.
select f_name, l_name, age, salary from employee_data where age >= 33;
Результат запроса приведен на рис. 5.10.
Рис. 5.10. Выборка столбцов с условием "больше или равно" для поля "возраст"
Выборка содержит имена, возраст и зарплаты сотрудников, которым больше 32 лет.
select f_name, l_name from employee_data where yos <= 2;
Результат запроса приведен на рис. 5.11.
Рис. 5.11. Выборка столбцов с условием "меньше или равно" для поля "стаж"
Запрос выводит имена сотрудников, которые работают в компании меньше 3 лет.
Операторы сравнения = и !=
SELECT f_name, l_name from employee_data where f_name = 'Иван';
Результат запроса приведен на рис. 5.4.
Рис. 5.4. Выборка столбцов с условием для поля "имя".
Этот оператор выводит имена и фамилии всех сотрудников, которые имеют имя Иван. Отметим, что слово Иван в условии заключено в одиночные кавычки. Можно использовать также двойные кавычки. Кавычки являются обязательными, так как MySQL будет порождать ошибку при их отсутствии. Кроме того сравнения MySQL не различают регистр символов, что означает, что с равным успехом можно использовать "Иван", "иван" и даже "ИвАн".
SELECT f_name,l_name from employee_data where title="программист";
Результат запроса приведен на рис. 5.5.
Рис. 5.5. Выборка столбцов с условием для поля "должность"
Выбирает имена и фамилии всех сотрудников, которые являются программистами.
SELECT f_name, l_name from employee_data where age = 32;
Результат запроса приведен на рис. 5.6.
Рис. 5.6. Выборка столбцов с условием для поля "возраст"
Это список имен и фамилий всех сотрудников с возрастом 32 года. Вспомните, что тип столбца age был задан как int, поэтому кавычки вокруг 32 не требуются. Это - незначительное различие между текстовым и целочисленным типами столбцов.
Оператор != означает 'не равно' и является противоположным оператору равенства.
Поиск текстовых данных по шаблону
В данной части мы рассмотрим поиск текстовых данных по шаблону с помощью предложения where и оператора LIKE.
Оператор сравнения на равенство (=) помогает выбрать одинаковые строки. Таким образом, чтобы перечислить имена сотрудников, которых зовут Иван, можно воспользоваться следующим оператором SELECT.
select f_name, l_name from employee_data where f_name = "Иван";
Результат запроса приведен на рис. 5.12.
Рис. 5.12. Результат поиска сотрудников, которых зовут Иван
Как быть, если надо вывести данные о сотрудниках, имя которых начинается с буквы В? Язык SQL позволяет выполнить поиск строковых данных по шаблону. Для этого в предложении where используется оператор LIKE следующим образом.
select f_name, l_name from employee_data where f_name LIKE "В%";
Результат запроса приведен на рис. 5.13.
Рис. 5.13. Результат поиска сотрудников, имя которых начинается с буквы В
Можно видеть, что здесь в условии вместо знака равенства используется LIKE и знак процента в шаблоне.
Знак % действует как символ-заместитель (аналогично использованию * в системах DOS и Linux). Он заменяет собой любую последовательность символов. Таким образом "В%" обозначает все строки, которые начинаются с буквы В. Аналогично "%В" выбирает строки, которые заканчиваются символом В, а "%В%" строки, которые содержат букву В.
Давайте выведем, например, всех сотрудников, которые имеют в названии должности строку "про".
select f_name, l_name, title from employee_data where title like '%про%';
Результат запроса приведен на рис. 5.14.
Рис. 5.14. Результат поиска сотрудников, в названии должности которых содержится строка "про"
Перечислим всех сотрудников, имена которых заканчиваются буквой 'а'. Это очень просто сделать.
mysql> select f_name, l_name from employee_data where f_name like '%a';
Результат запроса приведен на рис. 5.15.
Рис. 5.15. Результат поиска сотрудников, имена которых заканчиваются буквой 'а'
Предложение HAVING
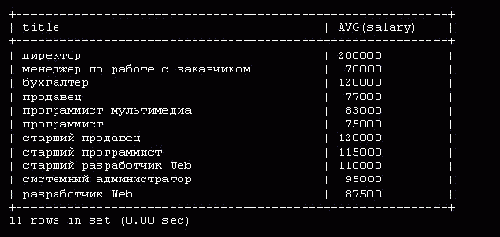
Чтобы вывести среднюю зарплату сотрудников в различных подразделениях (должностях), используется предложение GROUP BY, например:
select title, AVG(salary) from employee_data GROUP BY title;
Результат запроса приведен на рис. 5.16.
Рис. 5.16. Вывод средней зарплаты сотрудников по подразделениям
Предположим теперь, что требуется вывести только те подразделения, где средняя зарплата более 100000. Это можно сделать с помощью предложения HAVING.
select title, AVG(salary) from employee_data GROUP BY title HAVING AVG(salary) > 100000;
Результат запроса приведен на рис. 5.17.
Рис. 5.17. Вывод средней зарплаты определённого диапазона по подразделениям
Удаление записей из таблицы
Для удаления записей из таблицы можно использовать оператор DELETE.
Оператор удаления DELETE требует задания имени таблицы и необязательных условий.
DELETE from имя_таблицы [WHERE условия];
Примечание: Если никакие условия не будут заданы, то удаляются все данные в таблице.
Предположим, один из специалистов по мультимедиа 'Василий Пупкин' уволился из компании. Надо удалить его запись.
DELETE from employee_data WHERE l_name = 'Пупкин';
Результат запроса приведен на рис. 5.19.
Рис. 5.19. Результат удаления записи из таблицы
В системе Linux
1) Перейдите в каталог с файлом данных.
2) Выполните команду
mysql employees <employee.dat -u username -p
3) Введите свой пароль.
Пусть таблица содержит теперь 21 запись (20 из файла employee.dat и одну, вставленную оператором INSERT в начале лекции).
В системе Windows
1) Поместите файл в каталог c:\mysql\bin.
2) Проверьте, что MySQL работает.
3) Выполните команду
mysql employees <employee.dat
Возможное решение
mysql> select title, AVG(age) -> from employee_data -> GROUP BY title -> HAVING AVG(age) > 30;
Результат запроса приведен на рис. 5.18.
Рис. 5.18. Вывод подразделения и среднего возраста, где средний возраст больше 30 лет
Возможные решения
1. create database addressbook;
или
CREATE DATABASE addressbook;
Примечание: Операторы SQL не различают регистр символов, однако имена таблиц и имена баз данных могут различать регистр символов, в зависимости от используемой операционной системы.
Вторая форма лучше. Ее легче использовать и труднее ошибиться.
6. Чтобы вывести данные столбцов f_name и email, используем следующий оператор.
select f_name, email from employee_data;
7. SELECT salary, perks, yos from employee_data;
8. Последняя строка вывода любого оператора SELECT содержит число полученных строк. Поэтому при выводе всех данных в любом столбце (или всех столбцах), последняя строка будет указывать число строк в таблице.
9. select salary, l_name from employee_data;
1. select l_name, f_name from employee_data where l_name like 'P%';
2. select f_name, l_name from employee_data where title like '%продавец%';
3. Этот оператор выводит имена, фамилии и заплаты всех сотрудников, у которых имя содержит букву 'к'.
SELECT f_name, l_name, salary from employee_data where f_name like '%к%';
4. SELECT l_name, title from employee_data where title like '%программист%';
1. create database addressbook;
или
CREATE DATABASE addressbook;
Примечание: Операторы SQL не различают регистр символов, однако имена таблиц и имена баз данных могут различать регистр символов, в зависимости от используемой операционной системы.
Вторая форма лучше. Ее легче использовать и труднее ошибиться.
6. Чтобы вывести данные столбцов f_name и email, используем следующий оператор.
select f_name, email from employee_data;
7. SELECT salary, perks, yos from employee_data;
8. Последняя строка вывода любого оператора SELECT содержит число полученных строк. Поэтому при выводе всех данных в любом столбце (или всех столбцах), последняя строка будет указывать число строк в таблице.
9. select salary, l_name from employee_data;
Выборка данных с помощью условий
Теперь более подробно рассмотрим формат оператора SELECT. Его полный формат имеет вид:
SELECT имена_столбцов from имя_таблицы [WHERE ...условия];
В операторе SELECT условия являются необязательными.
Оператор SELECT без условий выводит все данные из указанных столбцов. Одним из достоинств RDBMS является возможность извлекать данные на основе определенных условий.
Теперь перейдём к рассмотрению операторов сравнения.
и средний возраст, где средний
Вывести подразделения и средний возраст, где средний возраст больше 30.
Напишите оператор SQL для создания
1. Напишите оператор SQL для создания новой базы данных с именем addressbook 2. Какой оператор используется для получения информации о таблице? Как используется этот оператор? 3. Как получить список всех баз данных, доступных в системе? 4. Напишите оператор для записи следующих данных в таблицу employee_data
Имя: Рудольф Фамилия: Курочкин Должность: Программист Возраст: 34 Стаж работы в компании: 2 Зарплата: 95000 Надбавки: 17000 email: rudolf@yandex.ru
5. Приведите две формы оператора SELECT, которые будут выводить все данные из таблицы employee_data. 6. Как извлечь данные столбцов f_name, email из таблицы employee_data? 7. Напишите оператор для вывода данных из столбцов salary, perks и yos таблицы employee_data. 8. Как узнать число строк в таблице с помощью оператора SELECT? 9. Как извлечь данные столбцов salary, l_name из таблицы employee_data?
1. Перечислить всех сотрудников, фамилии которых начинаются с буквы P. 2. Вывести имена всех сотрудников в отделе продаж. 3. Что выведет следующий оператор
SELECT f_name, l_name, salary from employee_data where f_name like '%к%';
4. Перечислить фамилии и должности всех программистов
1. Напишите оператор SQL для создания новой базы данных с именем addressbook 2. Какой оператор используется для получения информации о таблице? Как используется этот оператор? 3. Как получить список всех баз данных, доступных в системе? 4. Напишите оператор для записи следующих данных в таблицу employee_data
Имя: Рудольф Фамилия: Курочкин Должность: Программист Возраст: 34 Стаж работы в компании: 2 Зарплата: 95000 Надбавки: 17000 email: rudolf@yandex.ru
5. Приведите две формы оператора SELECT, которые будут выводить все данные из таблицы employee_data. 6. Как извлечь данные столбцов f_name, email из таблицы employee_data? 7. Напишите оператор для вывода данных из столбцов salary, perks и yos таблицы employee_data. 8. Как узнать число строк в таблице с помощью оператора SELECT? 9. Как извлечь данные столбцов salary, l_name из таблицы employee_data?
Запись данных в таблицы
Оператор INSERT заполняет таблицу данными. Вот общая форма INSERT.
INSERT into table_name (column1, column2, ...) values (value1, value2...);
где table_name является именем таблицы, в которую надо внести данные; column1, column2 и т.д. являются именами столбцов, а value1, value2 и т.д. являются значениями для соответствующих столбцов.
Следующий оператор вносит первую запись в таблицу employee_data, которую мы рассматривали в лекции 3.
Как и другие операторы MySQL, эту команду можно вводить на одной строке или разместить ее на нескольких строках.
Несколько важных моментов:
Значениями для столбцов f_name, l_name, title и email являются текстовые строки, и они записываются в кавычках.Значениями для age, yos, salary и perks являются числа (целые), и они не имеют кавычек.Можно видеть, что данные заданы для всех столбцов кроме except emp_id. Значение для этого столбца задает система MySQL, которая находит в столбце наибольшее значение, увеличивает его на единицу, и вставляет новое значение.
Если приведенная выше команда правильно введена в приглашении клиента mysql, то программа выведет сообщение об успешном выполнении, как показано на рис. 5.1.
Рис. 5.1. Ввод данных в таблицу.
Создание дополнительных записей требует использования отдельных операторов INSERT. Чтобы облегчить эту работу можно поместить все операторы INSERT в файл employee.dat. Это должен быть обычный текстовый файл с оператором INSERT в каждой строке.
Запрос данных из таблицы MySQL
Таблица employee_data содержит теперь достаточно данных, чтобы можно было начать с ней работать. Запрос данных выполняется с помощью команды MySQL SELECT. Оператор SELECT имеет следующий формат:
SELECT имена_столбцов from имя_таблицы [WHERE ...условия];
Часть оператора с условиями является необязательной (мы рассмотрим ее позже). По сути, требуется знать имена столбцов и имя таблицы, из которой извлекаются данные.
Например, чтобы извлечь имена и фамилии всех сотрудников, выполните следующую команду.
SELECT f_name, l_name from employee_data;
Оператор приказывает MySQL вывести все данные из столбцов f_name и l_name. Результат работы оператора представлен на рис. 5.2.
Рис. 5.2. Вывод данных из таблицы
При ближайшем рассмотрении можно заметить, что данные представлены в том порядке, в котором они были введены. Более того, последняя строка указываете число строк в таблице - 21.
Чтобы вывести всю таблицу, можно либо ввести имена всех столбцов, либо воспользоваться упрощенной формой оператора SELECT.
SELECT * from employee_data;
Символ * в этом выражении означает 'ВСЕ столбцы'. Поэтому этот оператор выводит все строки всех столбцов.
Рассмотрим ещё один пример.
SELECT f_name, l_name, age from employee_data;
Выборка столбцов f_name, l_name и age представлена на рис. 5.3.