Трехзвенная архитектура
До сих пор мы обсуждали самую простую архитектуру для работы с WWW и простыми бизнес-приложениями - клиент/сервер. Однако эту архитектуру не так-то просто нарастить по мере роста и изменения ваших приложений. В ней также трудно использовать преимущества объектно-ориентированного программирования. Первая проблема недавно нашла отражение в дискуссиях относительно «тонких клиентов». Потребность в тонких клиентах происходит из беспокоящей тенденции в передаче клиенту все больших объемов обработки. Эта проблема проявилась в PowerBuilder и VisualBasic - инструментах, которые прямо вытаскивают данные из базы в GUI, а затем все операции над этими данными проводят в GUI.
Такая тесная привязка интерфейса пользователя к ядру базы данных приводит к появлению программ, которые трудно модифицировать и невозможно масштабировать при увеличении числа пользователей и объема данных. Если у вас есть опыт разработки интерфейсов пользователя, то вы сталкивались с проблемой переработки интерфейса в зависимости от каприза пользователя. Чтобы изолировать последствия такой переработки, проще всего оставить для GUI только одну задачу- действовать в качестве интерфейса пользователя. Такой интерфейс пользователя действительно является тонким клиентом.
Влияние на масштабируемость сказывается и с другой стороны. Когда требуется переработать приложение, чтобы оно могло справляться с возросшим числом пользователей и объемом данных, модификация может быть осуществлена в результате изменений, вносимых в базу данных, в том числе таких, которые состоят в распределении базы данных по нескольким серверам. Навечно привязав свой интерфейс к базе данных, вам приходится делать изменения в этом GUI для решения проблем масштабирования - проблем, связанных исключительно с сервером.
Тонкие клиенты - не единственное сегодняшнее поветрие. Другая тенденция - повторное использование кода. Общий для разных приложений код тяготеет к обработке данных, обычно называемой деловой логикой. Если вся ваша деловая логика располагается в интерфейсе пользователя, то добиться повторного использования кода будет, по меньшей мере, трудно. Решением этих проблем является разбиение приложения на три, а не на две части. Такая архитектура называется трехзвенной.

Сравните двухзвенную архитектуру на рис. 8-1 с трехзвенной архитектурой, показанной на рис. 8-4. Мы добавили промежуточный слой между интерфейсом пользователя и базой данных. Этот новый слой, сервер приложений, заключает в себе логику работы приложения - деловую логику, которая является общей для некоторой области задач. Клиент становится ничем иным, как средством просмотра объектов среднего яруса, а база данных становится хранилищем этих объектов.
Самое главное, что вы выигрываете, - это разделение интерфейса пользователя и базы данных. Теперь вам не нужно встраивать знание базы данных в GUI. Напротив, все сведения о том, как работать с базой данных, могут размещаться в среднем ярусе.
Две главные задачи сервера приложений - это изоляция подключений к базе данных и обеспечение централизованного хранилища для деловой логики. Интерфейс пользователя имеет дело только с отображением и вводом данных, а ядро базы данных занимается только проблемами базы данных. При перемещении обработки данных в центральное место одну и ту же программу сервера приложений могут использовать различные интерфейсы пользователя, и устраняется необходимость писать правила обработки данных всякий раз, когда вы создаете новое приложение.

Рис. 8-4. Трехзвенная архитектура
CGI и базы данных
С начала эпохи Интернет базы данных взаимодействовали с разработкой World Wide Web. На практике многие рассматривают Web просто как одну гигантскую базу данных мультимедийной информации.
Поисковые машины дают повседневный пример преимуществ баз данных. Поисковая машина не отправляется бродить по всему Интернету в поисках ключевых слов в тот момент, когда вы их запросили. Вместо этого разработчики сайта с помощью других программ создают гигантский указатель, который служит базой данных, откуда поисковый механизм извлекает записи. Базы данных хранят информацию в таком виде, который допускает быструю выборку с произвольным доступом.
Благодаря своей изменчивости базы данных придают Web еще большую силу: они превращают ее в потенциальный интерфейс для чего угодно. Например, системное администрирование можно производить удаленно через веб-интерфейс вместо требования регистрации администратора в нужной системе. Подключение баз данных к Web лежит в основе нового уровня интерактивности в Интернет.

Как сказано раньше, только ваше воображение может ограничить возможности связи между базами данных и Web. В настоящее время существуют тысячи уникальных и полезных баз данных, имеющие доступ из Web. Типы баз данных, действующих за пределами этих приложений, весьма различны. Некоторые из них используют CGI-программы в качестве интерфейса с сервером баз данных, таким как MySQL или mSQL. Эти типы представляют для нас наибольший интерес. Другие используют коммерческие приложения для взаимодействия с популярными настольными базами данных, такими как Microsoft Access и Claris FileMaker Pro. А другие просто работают с плоскими текстовыми файлами, являющимися самыми простыми базами данных изо всех возможных.
С помощью этих трех типов баз данных можно разрабатывать полезные веб-сайты любого размера и степени сложности. Одной из наших задач на протяжении нескольких следующих глав будет приложение мощи MySQL mSQL к Web с использованием CGI-программирования.
Что такое CGI?
Как и большинство акронимов, Common Gateway Interface (CGI - общий шлюзовый интерфейс) мало что говорит по сути. Интерфейс с чем? Где этот шлюз? О какой общности речь? Чтобы ответить на эти вопросы, вернемся немного назад и бросим взгляд на WWW в целом.
Тим Бернерс-Ли, физик, работавший в CERN, придумал Web в 1990 году, хотя план возник еще в 1988. Идея состояла в том, чтобы дать исследователям в области физики элементарных частиц возможность легко и быстро обмениваться мультимедийными данными - текстом, изображениями и звуком — через Интернет. WWW состояла из трех основных частей: HTML, URL и HTTP. HTML - язык форматирования, используемый для представления содержания в Web. URL - это адрес, используемый для получения содержимого в формате HTML (или каком-либо ином) с веб-сервера. И, наконец, HTTP - это язык, который понятен веб-серверу и позволяет клиентам запрашивать у сервера документы.
Возможность пересылки через Интернет информации всех типов явилась революцией, но вскоре была обнаружена и другая возможность. Если можно переслать через Web любой текст, то почему нельзя переслать текст, созданный программой, а не взятый из готового файла? При этом открывается море возможностей. Простой пример: можно использовать программу, выводящую текущее время, так, чтобы читатель видел правильное время при каждом просмотре страницы. Несколько умных голов в National Center for Supercomputing Applications (Национальный центр разработки приложений для суперкомпьютеров -NCSA), которые создавали веб-сервер, такую возможность увидели, и вскоре появился CGI.
CGI - это набор правил, согласно которым программы на сервере могут через веб-сервер посылать данные клиентам. Спецификация CGI сопровождалась изменениями в HTML и HTTP, вводившими новую характеристику, известную как формы.
Если CGI позволяет программам посылать данные клиенту, то формы расширяют эту возможность, позволяя клиенту посылать данные для этой CGI-программы. Теперь пользователь может не только видеть текущее время, но и устанавливать часы! Формы CGI открыли дверь для подлинной интерактивности в мире Web. Распространенные приложения CGI включают в себя:
Динамический HTML. Целые сайты могут генерироваться одной CGI-программой.
Поисковые механизмы, находящие документы с заданными пользователем словами.
Гостевые книги и доски объявлений, в которые пользователи могут добавлять свои сообщения.
Бланки заказов.
Анкеты.
Извлечение информации из размещенной на сервере базы данных.
В последующих главах мы обсудим все эти CGI-приложения, а также и некоторые другие. Все они дают прекрасную возможность соединения CGI с базой данных, что и интересует нас в этом разделе.
Формы HTML
Прежде чем изучать особенности CGI, полезно рассмотреть наиболее часто встречающийся способ, с помощью которого конечные пользователи получают интерфейс к CGI-программам: формы HTML. Формы являются частью языка HTML, предоставляющей конечному пользователю поля различных типов. Данные, вводимые в поля, могут быть пересланы веб-серверу. Поля могут служить для ввода текста или являться кнопками, которые пользователь может нажать или отметить галочкой. Вот пример страницы HTML, содержащей форму:
<НТМL><НЕАD><ТITLЕ>Моя страница с формами</title></head>
<BODY>
<р>Это страница с формой.
<p><FORM ACTION="mycgi.cgi" METHOD=POST>
Введите свое имя: <INPUT NAME="firstname" SIZE=40><br>
<INPUT TYPE=SUBMIT VALUE="Отправить форму">
</form>
</body></html>
Данная форма создает строку длиной 40 символов, куда пользователь может ввести свое имя. Под строкой для ввода располагается кнопка, при нажатии которой данные формы передаются серверу. Ниже перечислены относящиеся к формам теги, поддерживаемые HTML 3.2 -наиболее распространенным в настоящее время стандартом. Названия тегов и атрибутов могут вводиться в любом регистре, но мы придерживаемся необязательного соглашения, согласно которому открывающие теги пишутся в верхнем регистре, а закрывающие - в нижнем.
<FORM>
Этот тег указывает на начало формы. В конце формы требуется закрывающий тег </Form> . Между тегами <FORM> допускаются три атрибута: ACTION задает URL или относительный путь к CGI-програм-ме, которой будут посланы данные; METHOD указывает метод HTTP, посредством которого будет послана форма (это может быть GET или ч POST, но мы почти всегда будем использовать POST); ENCTYPE задает метод кодирования данных (его следует использовать только при четком понимании того, что вы делаете).
<INPUT>
Предоставляет наиболее гибкий способ ввода данных пользователем. Фактически есть девять разных типов тега <INPUT> . Тип задается атрибутом TYPE. В предыдущем примере используются два тега <INPUT>: один с типом SUBMIT и другой с типом по умолчанию TEXT. Девять типов следующие:
TEXT
Поле для ввода пользователем одной строки текста.
PASSWORD
To же, что TEXT, но вводимый текст не отображается на экране.
CHECKBOX
Флажок, который пользователь может устанавливать и сбрасывать.
RADIO
Радиокнопка, которая должна объединяться еще хотя бы с одной радиокнопкой. Пользователь может выбрать только одну из них.
SUBMIT
Кнопка, при нажатии которой форма отправляется на веб-сервер.
RESET
Кнопка, при нажатии которой в форме восстанавливаются значения по умолчанию.
FILE
Аналогичен текстовому окну, но предполагает ввод имени файла, который будет отправлен на сервер.
HIDDEN
Невидимое поле, в котором могут храниться данные.
IMAGE
Аналогичен кнопке SUBMIT, но можно задать картинку для изображения на кнопке.
Кроме атрибута TYPE теги <INPUT> обычно имеют атрибут NAME, связывающий введенные в поле данные с некоторым именем. Имя и данные передаются серверу в стиле величина=значение . В предыдущем примере текстовое поле именовалось firstname . Можно использовать атрибут VALUE, чтобы присвоить полям типа TEXT, PASSWORD , FILE и HIDDEN предустановленные значения. Этот же атрибут, используемый с кнопками типа SUBMIT или RESET, выводит на них заданный текст. Поля типа RADIO и CHECKBOX можно отобразить как выставленные с помощью атрибута CHECKED без задания значения.
Атрибут SIZE используется для задания длины полей типа TEXT, PASSWORD и FILE. Атрибут MAXLENGTH можно использовать для ограничения длины вводимого текста. Атрибут SRC задает URL изображения, используемого в типе IMAGE. И наконец, атрибут ALIGN задает характер выравнивания изображения для типа IMAGE и может иметь значение TOP, MIDDLE, BOTTOM (по умолчанию), LEFT или RIGHT (вверх, в середину, вниз, влево, вправо).
<SELECT>
Этот тег обеспечивает создание меню, из пунктов которого пользователь делает выбор. Меню может быть выпадающим, в котором пользователь выбирает только один пункт, или иметь вид списка, из которого выбирается один или несколько пунктов. Каждый пункт меню задается тегом <OPTION> . Необходимо использовать закрывающий тег </select> .
Как и у тега <INPUT> , у тега <SELECT> есть атрибут NAME, указывающий на имя введенных данных. Возможно использование атрибута SIZE для определения того, сколько пунктов меню будет одновременно выводиться на экран. При отсутствии атрибута SIZE список выводится в виде выпадающего меню. Присутствие атрибута MULTIPLE указывает на возможность выбора нескольких пунктов одновременно. Тег <OPTION> имеет два атрибута. Атрибут VALUE устанавливает возвращаемое значение. Если VALUE не указан, то возвращается текст от тега <OPTION> и до конца строки. Наличие атрибута SELECTED в теге <OPTION> означает, что этот пункт выбирается по умолчанию.
<TEXTAREA>
Этот последний тег, относящийся к формам, позволяет пользователям вводить куски текста, которые будут переданы на веб-сервер. Тег <TEXTAREA> выводит окно, в которое пользователь может ввести любое число строк текста. Необходимо использовать закрывающий тег </Textarea> , и в качестве текста по умолчанию будет принят любой текст, находящийся между тегами <TEXTAREA> и </Textarea> , аналогично атрибуту VALUE для тега <INPUT> . Для тега <TEXTAREA> необходимо задать три атрибута. Атрибут МАМЕ определяет имя данных -так же, как и для других тегов форм. Атрибуты ROWS и COLS задают число строк и колонок при выводе поля на экран, но не ограничивают размер данных, вводимых пользователем.
В Примере 9-1 показано использование всех элементов форм.
Пример 9-1. Форма HTML, демонстрирующая использование различных элементов
<HTML><HEAD><TITLE>Moя вторая страница форм</TITLE>
<р>Это анкета. Пожалуйста, сообщите о себе следующие данные:
<!-Начнем форму. Мы используем метод 'POST' для передачи данных
CGI-программе с именем 'survey.cgi'
<FORM METHOD=POST ACTION="survey.cgi">
<р>Имя: <INPUT SIZE=40 NAME='name'Xbr>
<!-Это тег <INPUT>, имеющий (по умолчанию) тип 'TEXT'. Он имеет длину 40
символов, и данные получат имя 'name'
Номер социального страхования:
<INPUT TYPE=PASSWORD NAME='ssn' SIZE=20Xbr>
<!-Это тег <INPUT>, имеющий стиль 'PASSWORD', используемый для того, чтобы нельзя было подглядеть из-за спины пользователя, какое значение он ввел. Данные получат имя 'ssn', экранное поле имеет длину 20 символов.-->
Связаны ли вы сейчас с коммунистической партией или были связаны с ней ранее?
<INPUT TYPE=CHECKBOX NAME='commie' VALUE='yes'><br>
<!-Это тег <INPUT>, имеющий тип 'CHECKBOX' и использующий для данных имя 'commie'. При передаче формы с установленным флажком с именем 'commie'будет ассоциировано значение 'yes'
Пол:
<INPUT TYPE=RADIO NAME='sex' VALUE='мужской'> Мужской
<INPUT TYPE=RADIO NAME='sex' VALUE='женский'> Женский
<INPUT TYPE=RADIO NAME='sex' VALUE='отсутствует1 CHECKED> Отсутствует<br>
<!-Три тега <INPUT> типа 'RADIO', использующие для данных имя 'sex'. Можно выбрать только один вариант из трех, и поскольку один из них предустановлен, значение будет послано, даже если пользователь не выберет ни одного из них, Посылаемое серверу значение находится в атрибуте 'VALUE' и мйжет не иметь отношения к тексту, следующему за тегом. -->
<INPUT TYPE=HIDDEN NAME="form_number" VALUE="33a">
<!-Это дополнительные данные, которые мы хотим послать серверу, но пользователю знать об этом не нужно, поэтому мы поместили их внутрь тега <INPUT> типа 'HIDDEN' -->
Пожалуйста, укажите путь к вашей любимой игре:
<INPUT TYPE=FILE NAME='game'
SIZE=40><br>
<!-Если пользователь введет правильный путь, то при подаче формы файл будет передан на веб-сервер Q именем 'game'. Это, однако, не столь опасно, как может показаться, поскольку большинство броузеров запрашивает подтверждение на передачу. -->
Ваш любимый цвет (цвета)?<br>
<SELECT NAME="color" MULTIPLE SIZE=5>
<OPTION>Красный
<OPTION>Зеленый
<OPTION>Желтый
<OPTION>Оранжевый
<OPTION VALUE="Голубой">Прелестный цвет лазурного неба
</select><br>
<!-Это пара тегов <SELECT></select>c несколькими возможностями выбора
<OPTION>. Данные получат имя 'color', можно выбрать сразу несколько пунктов, при этом на экран будут выведены все 5 одновременно. Последний пункт использует атрибут 'VALUE', чтобы передать краткий текст. -->
Опишите исчерпывающим образом общественно-политический фон романа
<I>Война и мир</I>
не более, чем в 50 словах.<br>
<TEXTAREA NAME='essay' COLS=70 ROWS=10></textarea><br>
<!-Это пара тегов <TEXTAREAx/textarea>, дающая место для ввода очерка. Данные получают имя 'essay'. Блок текста 70 символов в ширину и 10 строк в глубину. Пространство между тегами
<TEXTAREA> и </textarea>
можно использовать для образца очерка. -->
<INPUT TYPE=SUBMIT VALUE="Ввести данные">
<INPUT TYPE=RESET><!-Два тега <INPUT>типов 'SUBMIT' и 'RESET' соответственно. Кнопка 'SUBMIT' имеет переопределенную надпись 'Ввести данные ', а кнопка 'RESET' имеет надпись по умолчанию (определяемую броузером). Кликнув по кнопке 'SUBMIT', вы пошлете данные на веб-сервер, Кнопка 'RESET' восстановит данные R исходное состояние, удалив все введенные пользователем данные. -->
</form></body></html>
Единственный тип ввода, который мы здесь не использовали, - это тип IMAGE для тега <INPUT> . Можно было бы использовать его в качестве альтернативного способа отправки формы. Однако тип IMAGE редко совместим с текстовыми и не очень чуткими броузерами, поэтому благоразумно избегать его, если только ваш сайт не выполнен в насыщенном графическом стиле.
После знакомства с основами форм HTML можно приступить к изучению собственно CGI.
в книгу по базам данных
Программирование с использованием CGI
Включение раздела о CGI в книгу по базам данных может показаться столь же странным, как если бы в кулинарную книгу была включена глава о ремонте автомобилей. Разумеется, для того чтобы съездить в магазин за продуктами, нужен исправный автомобиль, но уместно ли об этом говорить? Полное изложение CGI и веб-программирование в целом выходят за рамки данной книги, но краткого введения в эти темы достаточно для того, чтобы расширить возможности MySQL и mSQL по представлению данных в царстве Web.
В основном эта глава предназначена тем, кто изучает базы данных, но не прочь приобрести некоторые знания и в программировании для Web. Если ваша фамилия Бернерс-Ли или Андрессен, вряд ли вы найдете здесь то, чего еще не знаете. Но даже если вы не новичок в CGI, наличие под рукой краткого справочника во время погружения в тайны MySQL и mSQL может оказаться весьма полезным.
Спецификация CGI
Итак, что в точности представляет собой «набор правил», позволяющий CGI-программе, скажем, в Батавии, штат Иллинойс, обмениваться данными с веб-броузером во Внешней Монголии? Официальную спецификацию CGI наряду с массой других сведений о CGI можно найти на сервере NCSA по адресу http://hoohoo. ncsa.uluc.edu/ cgi/. Однако эта глава для того и существует, чтобы вам не пришлось долго путешествовать и самому ее искать.
Есть четыре способа, которыми CGI передает данные между CGI-npor-раммой и веб-сервером, а следовательно, и клиентом Web:
Переменные окружения.
Командная строка.
Стандартное устройство ввода.
Стандартное устройство вывода.
С помощью этих четырех методов сервер пересылает все данные, переданные клиентом, CGI-программе. Затем CGI-программа делает свое волшебное дело и пересылает выходные данные обратно серверу, который переправляет их клиенту.
Когда CGI-программа вызывается посредством формы — наиболее распространенного интерфейса, броузер передает серверу длинную строку, в начале которой стоит путь к CGI-программе и ее имя. Затем следуют различные другие данные, которые называются информацией пути и передаются CGI-программе через переменную окружения PATH_INFO (рис. 9-1). После информации пути следует символ «?», а за ним - данные формы, которые посылаются серверу с помощью метода HTTP GET. Эти данные становятся доступными CGI-программе через переменную окружения QUERY_STRING . Любые данные, которые страница посылает с использованием метода HTTP POST, который используется чаще всего, будут переданы CGI-программе через стандартное устройство ввода. Типичная строка, которую может получить сервер от броузера, показана на рис. 9-1. Программа с именем formread в каталоге cgi-bin вызывается сервером с дополнительной информацией пути extra/information и данными запроса choice=help - по-видимому, как часть исходного URL. Наконец, данные самой формы (текст «CGI programming» в поле «keywords») пересылаются через метод HTTP POST .

Рис. 9-1. Части строки, переданной броузером серверу
Переменные окружения
Когда сервер выполняет CGI-программу, то прежде всего передает ей некоторые данные для работы в виде переменных окружения. В спецификации официально определены семнадцать переменных, но неофициально используется значительно больше - с помощью описываемого ниже механизма, называемого HTTP_/nec/zams/n. CGI-программа
имеет доступ к этим переменным так же, как и к любым переменным среды командного процессора при запуске из командной строки. В сценарии командного процессора, например, к переменной окружения F00 можно обращаться как $F00; в Perl это обращение выглядит, как $ENV{'F00'} ; в С - getenv("F00") ; и т. д. В таблице 9-1 перечислены переменные, которые всегда устанавливаются сервером - хотя бы и в значение null. Помимо этих переменных данные, возвращаемые клиентом в заголовке запроса, присваиваются переменным вида HTTP_F00 , где F00 - имя заголовка. Например, большинство веб-броузеров включает данные о версии в заголовок с именем USEfl_AGENT . Ваша CGI-npor-рамма может получить эти данные из переменной HTTP_USER_AGENT .
Таблица 9-1. Переменные окружения CGI
Переменная окружения |
Описание |
||
CONTENT_LENGTH |
Длина данных, переданных методами POST или PUT, в байтах. |
||
CONTENT_TYPE |
Тип MIME данных, присоединенных с помощью методов POST или PUT . |
||
GATEWAY_INTERFACE |
Номер версии спецификации CGI, поддерживаемой сервером. |
||
PATH_INFO |
Дополнительная информация пути, переданная клиентом. Например, для запроса http://www.myserver.eom/test.cgi/this/is/a/ path?field=green значением переменной РАТН_ INFO будет /this/is/a/path. |
||
PATH_TRANSLATED |
То же, что PATH_INFO , но сервер производит всю |
||
возможную трансляцию, например, расширение имен типа «-account». » |
|||
QUERY_STRING |
Все данные, следующие за символом «?» в URL. Это также данные, передаваемые, когда REQ-UEST_METHOD формы есть GET. |
||
REMOTE_ADDR |
IP-адрес клиента, делающего запрос. |
||
REMOTE_HOST |
Имя узла машины клиента, если оно доступно. |
||
REMOTE_IDENT |
Если веб-сервер и клиент поддерживают идентификацию типа identd, то это имя пользователя учетной записи, которая делает запрос. |
||
REQUEST_METHOD |
Метод, используемый клиентом для запроса. Для CGI-программ, которые мы собираемся создавать, это обычно будет POST или GET. |
||
| SERVER_NAME | Имя узла - или IP-адрес, если имя недоступно, -машины, на которой выполняется веб-сервер. | ||
| SERVER_PORT | Номер порта, используемого веб-сервером. | ||
| SERVER_PROTOCOL |
Протокол, используемый клиентом для связи с сервером. В нашем случае этот протокол почти всегда HTTP. | ||
| SERVER_SOFTWARE | Данные о версии веб-сервера, выполняющего CGI-программу. | ||
SCRIPT_NAME |
Путь к выполняемому сценарию, указанный клиентом. Может использоваться при ссылке URL на самого себя, и для того, чтобы сценарии, ссылки на которые существуют в разных местах, могли выполняться по-разному в зависимости от места. |
||
Приведем пример сценария CGI на Perl, который выводит все переменные окружения, установленные сервером, а также все унаследованные переменные, такие как PATH, установленные командным процессором, запустившим сервер.
#!/usr/bin/perl -w
print << HTML;
Content-type: text/html\n\n
<HTML><HEAD><TITLE></title></head>
<BODY> <р>Переменные окружения
<P> HTML
foreach (keys %ENV) { print "$_: $ENV{$_}<br>\n"; }
print <<HTML; </body></html>
HTML
Все эти переменные могут быть использованы и даже изменены вашей CGI-программой. Однако эти изменения не затрагивают веб-сервер, запустивший программу.
Командная строка
CGI допускает передачу CGI-программе аргументов в качестве параметров командной строки, которая редко используется. Редко используется она потому, что практические применения ее немногочисленны, и мы не будем останавливаться на ней подробно. Суть в том, что если переменная окружения QUERY_STRING не содержит символа « = », то CGI-программа будет выполняться с параметрами командной строки, взятыми из QUERY_STRING . Например, http://www.myserver.com/cgi-bin/finger?root запустит finger root на www.myserver.com.
Есть две основные библиотеки, обеспечивающие CGI-интерфейс для Perl. Первая из них - cgi-lib.pl Утилита cgi-lib.pl очень распространена, поскольку в течение долгого времени была единственной имеющейся большой библиотекой. Она предназначена для работы в Perl 4, но работает и с Perl 5. Вторая библиотека, CGI.pm, более новая и во многом превосходит cgi-lib.pl. CGI.pm написана для Perl 5 и использует полностью объектно-ориентированную схему для работы с данными CGI. Модуль CGI.pm анализирует стандартное устройство ввода и переменную QUERY_STRING и сохраняет данные в объекте CGI. Ваша программа должна лишь создать новый объект CGI и использовать простые методы, такие как paramQ, для извлечения нужных вам данных. Пример 9-2 служит короткой демонстрацией того, как CGI.pm интерпретирует данные. Все примеры на Perl в этой главе будут использовать CGI.pm.
Пример 9-2. Синтаксический анализ CGI-данных на Perl
#!/usr/bin/perl -w
use CGI qw(:standard);
# Используется модуль CGI.pm. qw(:standard) импортирует
# пространство имен стандартных CGI-функций,чтобы получить
# более понятный код. Это можно делать, если в сценарии
# используется только один объект CGI.
$mycgi = new CGI; #Создать объект CGI, который будет 'шлюзом' к данным формы
@fields = $mycgi->param; # Извлечь имена всех заполненных полей формы
print header, start_html('CGI.pm test'); ft Методы 'header' и 'start_html',
# предоставляемые
# CGI.pm, упрощают получение HTML.
# 'header' выводит требуемый заголовок HTTP, a
#'start_html' выводит заголовок HTML с данным названием,
#a также тег <BODY>.
print "<р>Данные формы:<br>";
foreach (@fields) { print $_, ":",- $mycgi->param($_), "<br>"; }
# Для каждого поля вывести имя и значение, получаемое с помощью
# $mycgi->param('fieldname').
print end_html; # Сокращение для вывода завершающих тегов "</body></html>".
Обработка входных данных в С
Поскольку основные API для MySQL и mSQL написаны на С, мы не будем полностью отказываться от С в пользу Perl, но там, где это уместно, приведем несколько примеров на С. Есть три широко используемые С-библиотеки для CGI-программирования: cgic Тома Бу-телла (Tom Boutell)*; cgihtml Юджина Кима (Eugene Kim)t и libcgi от EIT*. Мы полагаем, что cgic является наиболее полной и простой в использовании. В ней, однако, недостает возможности перечисления всех переменных формы, когда они не известны вам заранее. На самом деле, ее можно добавить путем простого патча, но это выходит за рамки данной главы. Поэтому в примере 9-3 мы используем библиотеку cgihtml, чтобы повторить на С приведенный выше сценарий Perl.
Пример 9-3. Синтаксический анализ CGI-данных на С
/* cgihtmltest.c - Типовая CGI-программа для вывода ключей и их значений
из данных, полученных от формы */
#include <stdio.h>
#include "cgi-lib.h" /* Здесь содержатся все определения функций СGI */
#include "html-lib.h" /* Здесь содержатся' все определения вспомогательных функций для HTML */
void print_all(llist 1)
/* Эти функции выводят данные, переданные формой, в том же формате, что и приведенный выше сценарий Perl. Cgihtml предоставляет также встроенную функцию
print_entries(), которая делает то же самое, используя формат списка HTML. */ {
node* window;
/* Тип 'node' определен в библиотеке cgihtml и ссылается на связанный список, в котором хранятся все данные формы. */
window = I.head; /* Устанавливает указатель на начало данных формы */
while (window != NULL) { /* Пройти по связанному списку до последнего (первого пустого) элемента */
printf(" %s:%s<br>\n",window->entry. name,replace_ltgt(window->entry.value));
/* Вывести данные. Replace__ltgt() - функция, понимающая HTML-кодировку текста и обеспечивающая его правильный вывод на броузер клиента. */
window = window->next; /* Перейти к следующему элементу списка. */
} }
int main() {
llist entries; /* Указатель на проанализированные данные*/
int status; /* Целое число, представляющее статус */
html__header(); /* Вспомогательная функция HTML, выводящая заголовок HTML*/
html_begin("cgihtml test");
/* Вспомогательная функция HTML, выводящая начало страницы HTML с указанным заголовком. */
status = read_cgi_input(&entries); /* Производит ввод и синтаксический анализ данных формы*/
printf("<р>Данные формы:<br>");
print_all(entries); /* Вызывает определенную выше функцию print_all(). */
html_end(); /* Вспомогательная функция HTML, выводящая конец страницы HTML. */
list_clear(&entries); /* Освобождает память, занятую данными формы. */
return 0; }
Стандартное устройство вывода
Данные, посылаемые CGI-программой на стандартное устройство вывода, читаются веб-сервером и отправляются клиенту. Если имя сценария начинается с nph-, то данные посылаются прямо клиенту без вмешательства со стороны веб-сервера. В этом случае CGI-программа должна сформировать правильный заголовок HTTP, который будет понятен клиенту. В противном случае предоставьте веб-серверу сформировать HTTP-заголовок за вас.
Даже если вы не используете nph-сценарий, серверу нужно дать одну директиву, которая сообщит ему сведения о вашей выдаче. Обычно это HTTP-заголовок Content-Type , но может быть и заголовок Location . За заголовком должна следовать пустая строка, то есть перевод строки или комбинация CR/LF.
Заголовок Content-Type сообщает серверу, какого типа данные выдает ваша CGI-программа. Если это страница HTML, то строка должна быть Content-Type: text/html. Заголовок Location сообщает серверу другой URL - или другой путь на том же сервере, - куда нужно направить клиента. Заголовок должен иметь следующий вид: Location: http:// www. myserver. com/another/place/.
После заголовков HTTP и пустой строки можно посылать собственно данные, выдаваемые вашей программой, - страницу HTML, изображение, текст или что-либо еще. Среди CGI-программ, поставляемых с сервером Apache, есть nph-test-cgi и test-cgi, которые хорошо демонстрируют разницу между заголовками в стилях nph и не-nph, соответственно.
В этом разделе мы будем использовать библиотеки CGI.pm и cgic, в которых есть функции для вывода заголовков как HTTP, так и HTML. Это позволит вам сосредоточиться на выводе собственно содержания. Эти вспомогательные функции использованы в примерах, приведенных ранее в этой главе.
Важные особенности сценариев CGI
Вы уже знаете, в основном, как работает CGI. Клиент посылает данные, обычно с помощью формы, веб-серверу. Сервер выполняет CGI-программу, передавая ей данные. CGI-программа осуществляет свою обработку и возвращает свои выходные данные серверу, который передает их клиенту. Теперь от понимания того, как работают CGI-npor-раммы, нужно перейти к пониманию того, почему они так широко используются.
Хотя вам уже достаточно известно из этой главы, чтобы собрать простую работающую CGI-программу, нужно разобрать еще несколько важных вопросов, прежде чем создавать реально работающие программы для MySQL или mSQL. Во-первых, нужно научиться работать с несколькими формами. Затем нужно освоить некоторые меры безопасности, которые помешают злоумышленникам получить незаконный доступ к файлам вашего сервера или уничтожить их.
Запоминание состояния
Запоминание состояния является жизненно важным средством предоставления хорошего обслуживания вашим пользователям, а не только служит для борьбы с закоренелыми преступниками, как может показаться. Проблема вызвана тем, что HTTP является так называемым протоколом «без памяти». Это значит, что клиент посылает данные серверу, сервер возвращает данные клиенту, и дальше каждый идет своей дорогой. Сервер не сохраняет о клиенте данных, которые могут понадобиться в последующих операциях. Аналогично, нет уверенности, что клиент сохранит о совершенной операции какие-либо данные, которые можно будет использовать позднее. Это накладывает непосредственное и существенное ограничение на использование World Wide Web.
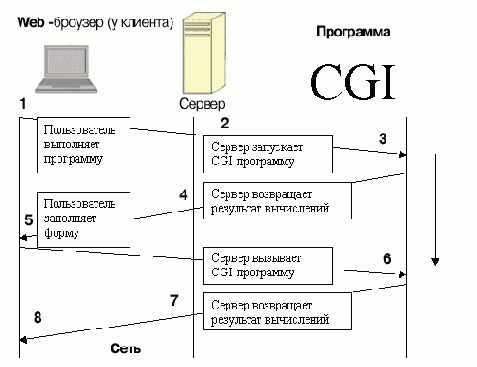
Рис. 9-2. Множественные запросы форм
Составление сценариев CGI при таком протоколе аналогично неспособности запоминать разговор. Всякий раз, разговаривая с кем-либо, независимо от того, как часто вы общались с ним раньше, вам приходится представляться и искать общую тему для разговора. Нет нужды объяснять, что это не способствует продуктивности. Рисунок 9-2 показывает, что всякий раз, когда запрос достигает программы CGI, это совершенно новый экземпляр программы, не имеющий связи с предыдущим.
В части клиента с появлением Netscape Navigator появилось выглядящее наспех сделанным решение под названием cookies. Оно состоит в создании нового HTTP-заголовка, который можно пересылать туда-сюда между клиентом и сервером, похожего на заголовки Content-Type и Location. Броузер клиента, получив заголовок cookie, должен сохранить в cookie данные, а также имя домена, в котором действует этот cookie. После этого всякий раз при посещении URL в пределах указанного домена заголовок cookie должен возвращаться серверу для использования в CGI-программах на этом сервере.
Метод cookie используется в основном для хранения идентификатора пользователя. Сведения о посетителе можно сохранить в файле на машине сервера. Уникальный ID этого пользователя можно послать в качестве cookie броузеру пользователя, после чего при каждом посещении сайта пользователем броузер автоматически посылает серверу этот ID. Сервер передает ID программе CGI, которая открывает соответствующий файл и получает доступ ко всем данным о пользователе. Все это происходит незаметным для пользователя образом.
Несмотря на всю полезность этого метода, большинство больших сайтов не использует его в качестве единственного средства запоминания состояния. Для этого есть ряд причин. Во-первых, не все броузеры поддерживают cookie. До недавнего времени основной броузер для людей с недостаточным зрением (не говоря уже о людях с недостаточной скоростью подключения к сети) - Lynx - не поддерживал cookie. «Официально» он до сих пор их не поддерживает, хотя это делают некоторые его широко доступные «боковые ветви». Во-вторых, что более важно, cookie привязывают пользователя к определенной машине. Одним из великих достоинств Web является то, что она доступна из любой точки света. Независимо от того, где была создана или где хранится ваша веб-страница, ее можно показать с любой подключенной к Интернет машины. Однако если вы попытаетесь получить доступ к поддерживающему cookie сайту с чужой машины, все ваши персональные данные, поддерживавшиеся с помощью cookie, будут утрачены.
Многие сайты по- прежнему используют cookie для персонализации страниц пользователей, но большинство дополняет их традиционным интерфейсом в стиле «имя регистрации/пароль». Если доступ к сайту осуществляется из броузера, не поддерживающего cookie, то страница содержит форму, в которую пользователь вводит имя регистрации и пароль, присвоенные ему при первом посещении сайта. Обычно эта форма маленькая и скромная, чтобы не отпугивать большинство пользователей, не заинтересованных ни в какой персонализации, а просто желающих пройти дальше. После ввода пользователем в форму имени регистрации и пароля CGI находит файл с данными об этом пользователе, как если бы имя посылалось с cookie. Используя этот метод, пользователь может регистрироваться на персонализированном веб-сайте из любой точки света.
Помимо задач учета предпочтений пользователя и длительного хранения сведений о нем можно привести более тонкий пример запоминания состояния, который дают популярные поисковые машины. Осуществляя поиск с помощью таких служб, как AltaVista или Yahoo, вы обычно получаете значительно больше результатов, чем можно отобразить в удобном для чтения виде. Эта проблема решается тем, что показывается небольшое количество результатов - обычно 10 или 20 - и дается какое-либо средство перемещения для просмотра следующей группы результатов. Хотя обычному путешественнику по Web такое поведение кажется обычным и ожидаемым, действительная его реализация нетривиальна и требует запоминания состояния.
Когда пользователь впервые делает запрос поисковому механизму, тот собирает все результаты, возможно, ограничиваясь некоторым предустановленным предельным количеством. Фокус состоит в том, чтобы выдавать эти результаты одновременно в небольшом количестве, запомнив при этом, что за пользователь запрашивал эти результаты и какую порцию он ожидает следующей. Оставляя в стороне сложности самого поискового механизма, мы встаем перед проблемой последовательного предоставления пользователю некоторой информации по одной странице. Рассмотрим пример 9-4, в котором показан сценарий CGI, выводящий десять строк файла и предоставляющий ему возможность просмотреть следующие или предыдущие десять строк.
Пример 9-4. Сохранение состояния в сценарии CGI
#!/usr/bin/perl -w
use CGI;
open(F,"/usr/dict/words") or die("He могу открыть! $!");
# Это файл, который будет выводиться, может быть любым.
$output = new CGI;
sub print_range { # Это главная функция программы, my $start = shift;
# Начальная строка файла, my $count = 0;
# Указатель, my $line = "";
# Текущая строка файла, print $output->header,
$output->start_html('Moй словарь');
# Создает HTML с заголовком 'Мой словарь', print "<pro>\n";
while (($count < $start) and ($line = <F>)) { $count++; }
# Пропустить все строки перед начальной, while (($count < $start+10) and ($line ? <F>) ) { print $line; $count++; }
# Напечатать очередные 10 строк.
my $newnext = $start+10; my $newprev = $start-10;
# Установить начальные строки для URL 'Next' и 'Previous',
print "</pre><p>";
unless ($start == 0) { # Включить URL 'Previous', если только вы
# уже не в начале .
print qq%<a href="read.cgi?start=$newprev">Previous</a>%; }
unless (eof) { # Включить URL 'Next', если только вы # не в конце файла.
print qq% <a href="read.cgi?start=$newnext">Next</a>%;
}
print «HTML; </body><html> HTML
exit(0); }
# Если данных нет, начать сначала,
if (not $output->param) {
&print_range(0); }
# Иначе начать со строки, указанной в данных.
&print_range($output->param('start'));
В этом примере запоминание состояния производится с помощью простейшего метода. Проблемы с сохранением данных нет, поскольку мы держим их в файле на сервере. Нам нужно только знать, откуда начать вывод, поэтому сценарий просто включает в URL начальную точку для следующей или предыдущей группы строк - все, что необходимо для генерации очередной страницы.
Однако если вам требуется нечто большее, чем возможность просто листать "файл, то полагаться на URL бывает обременительно. Облегчить эту трудность можно через использование формы HTML и включение данных о состоянии в теги <INPUT> типа HIDDEN. Этот метод с успехом используется на многих сайтах, позволяя делать ссылки между взаимосвязанными CGI-программами или расширяя возможности использования одной CGI-программы, как в предыдущем примере. Вместо ссылки на определенный объект, такой как начальная страница, данные URL могут указывать на автоматически генерируемый ID пользователя.
Так работают AltaVista и другие поисковые машины. При первом поиске генерируется ID пользователя, который скрыто включается в последующие URL. С этим ID связаны один или несколько файлов, содержащих результаты запроса. В URL включаются еще две величины: текущее положение в файле результатов и направление, в котором вы хотите перемещаться в нем дальше. Эти три значения — все, что нужно для работы мощных систем навигации больших поисковых машин.
- Впрочем, не хватает еще кое-чего. Использовавшийся в нашем примере файл /usr/diet/words очень велик. Что если на середине чтения мы его бросим, но захотим вернуться к нему позднее? Если не запомнить URL следующей страницы, никакого способа вернуться назад нет, даже AltaVista это не позволит. Если вы перезагрузите свой компьютер или станете работать с другого, невозможно вернуться к результатам прежнего поиска, не вводя заново запрос. Однако такое долговременное запоминание состояния лежит в основе персонализации вебсайтов, о которой мы говорили выше, и стоит посмотреть, как им можно воспользоваться. Пример 9-5 является модифицированным вариантом примера 9-4.
Пример 9-5. Устойчивое запоминание состояния
#!/usr/bin/perl -w
use CGI;
umask 0;
open(F,"/usr/dict/words") or die("He могу открыть! $!");
chdir("users") or die("He могу перейти в каталог $!");
# Это каталог, где будут храниться все данные
# о пользователе.
Soutput = new CGI;
if (not$output->param) {
print $output->header,
$output->start_html('Мой словарь');
print «HTML;
<FORM ACTION="read2.cgi" METHOD=POST>
<р>Введите свое имя пользователя:
<INPUT NAME="username" SIZE=30>
<P>
</formx/body></html> HTML
exit(0); }
$user = $output->param('username');
## Если файла пользователя нет, создать его и установить
## начальное значение в '0',
if ( not -e "$user" ) {
open (U, ">$user") or die("He могу открыть! $!");
print U "0\n";
close U;
&print_range('0');
## если пользователь существует и в URL не задано
## начальное значение, прочесть последнее значение и начать с него.
} elsif ( not $output->param('start') ) {
open(U,"Suser") or die("He могу открыть пользователя! $!");
$start = <U>; close U;
chomp $starl;
uprint range($start);
## Если пользователь существует и в URL не указано
## начальное значение, записать начальное значение
## в файл пользователя и начать вывод.
} else{
open(U,">$user") or die("He могу открыть пользователя для записи! $!");
print U $output->param('start'), "\n";
close U;
&print_range($output->param('start1)); }
sub print_range {
my $start = shift;
my $count = 0;
my $line = " "
print $output->header,
$output->start_html(' Мой словарь ');
print "<pre>\n";
while (($count < $start) and ($line = <F>)) { $count++; }
while (($count < $start+10) and ($line = <F>) )
{
print $line; $count++;
}
my $newnext = $start+10;
my $newprev = $start-10;
print "</pre><p>";
unless (Sstart == 0)
{
qq%<a href="read2.cgi?start=$newprev&username=$user">
Previous</a>%;
}
unless (eof) { print qq% <a href="read2.cgi?start=$newnext&username=$user">Next</a>%;
# Заметьте, что имя пользователя 'username' добавлено к URL.
# В противном случае CGI забудет, с каким пользователем имел дело.
}
print $output->end_html;
exit(0');
}
Меры безопасности
При работе серверов Интернет, будь они серверами HTTP или другого рода, соблюдение мер безопасности является важнейшей заботой. Обмен данными между клиентом и сервером, совершаемый в рамках
CGI, выдвигает ряд важных проблем, связанных с защитой данных. Сам протокол CGI достаточно защищен. CGI-программа получает данные от сервера через стандартное устройство ввода или переменные окружения, и оба эти метода являются безопасными. Но как только CGI-программа получает управление данными, ее действия ничем не ограничены. Плохо написанная CGI-программа может позволить злоумышленнику получить доступ к системе сервера. Рассмотрим следующий пример CGI-программы:
#!/usr/bin/perl -w
use CGI;
my $output = new CGI;
my $username = $output»param('username');
print $output->header, $output->start_html('Finger Output'),
"<pre>", 'finger $username', "</pre>", $output->end_html;
Эта программа обеспечивает действующий CGI-интерфейс к команде finger. Если запустить программу просто как finger.cgi, она выведет список всех текущих пользователей на сервере. Если запустить ее как finger.cgi?username=fred, то она выведет информацию о пользователе «fred» на сервере. Можно даже запустить ее как finger. cgi?userna-me=bob@f oo.com для вывода информации об удаленном пользователе. Однако если запустить ее как finger.cgi?username=fred;mail+hac-ker@bar.com</etc/passwd, могут произойти нежелательные вещи. Оператор обратный штрих «'' » в Perl порождает процесс оболочки и выполняет команду, возвращающую результат. В данной программе 'finger $username* используется как простой способ выполнить команду finger и получить ее результат. Однако большинство командных процессоров позволяет объединять в одной строке несколько команд. Например, любой процессор, подобный процессору Борна, делает это с помощью символа «; ». Поэтому "finger fred;mail hacker@bar.com</ etc/ passwd" запустит сначала команду finger, а затем команду mail hacker@bar.com</etc/passwd, которая может послать целиком файл паролей сервера нежелательному пользователю.
Одно из решений состоит в синтаксическом анализе поступивших от формы данных с целью поиска злонамеренного содержания. Можно, скажем, искать символ «;» и удалять все следующие за ним символы. Можно сделать такую атаку невозможной, используя альтернативные методы. Приведенную выше CGI-программу можно переписать так:
#!/usr/local/bin/perl -w
use CGI;
my $output = new CGI;
my $username = $output->param('username');
$|++;
# Отключить буферизацию с целью направления всех данных клиенту,
print $output->header, $putput->start_html('Finger Output'), "<pre>\n";
$pid = open(C_OUT, "-|");# Эта идиома Perl порождает дочерний процесс и открывает
# канал между родительским и дочерним процессами,
if ($pid) {# Это родительский процесс.
print <C_OUT>; ft Вывести выходные данные дочернего процесса.
print "</pre>", $output->end_html;
exit(O); ft Завершить программу. }
elsif (defined $pid) { # Это дочерний процесс.
$|++; # Отключить буферизацию.
ехес('/usr/bin/finger',$username) or die("exec() call failed.");
# Выполняет программу finger с Susername в качестве одного единственного
# аргумента командной строки. } else { die("неудачная попытка fork()"); }
# Проверка ошибок.
Как видите, это не на много более сложная программа. Но если запустить ее как finger.cgi?username=fred;mail+hacker@bar.com</etc/passwd, то программа finger будет выполняться с аргументом fred;mail hacker@bar.com</etc/passwd как одним именем пользователя.
Другое важное соображение, касающееся безопасности, связано с правами пользователя. По умолчанию веб-сервер запускает программу CGI с правами того пользователя, который запустил сам сервер. Обычно это псевдопользователь, такой как «nobody», имеющий ограниченные права, поэтому у CGI-программы тоже мало прав. Обычно это хорошо, ибо, если злоумышленник сможет получить доступ к серверу через CGI-программу, ему не удастся причинить много вреда. Пример программы, крадущей пароли, показывает, что можно сделать, но фактический ущерб для системы, как правило, ограничен.
Однако работа в качестве пользователя с ограниченными правами ограничивает и возможности CGI. Если программе CGI нужно читать или записывать файлы, она может делать это только там, где у нее есть такое разрешение. Например, во втором примере запоминания состояния для каждого пользователя ведется файл. CGI-программа должна иметь разрешение на чтение и запись в каталоге, содержащем эти файлы, не говоря уже о самих файлах. Это можно сделать, создав каталог в качестве того же пользователя, что и сервер, с правами чтения и записи только для этого пользователя. Однако для такого пользователя, как «nobody», только root имеет подобную возможность. Если вы не суперпользователь, то вам придется общаться с администратором системы при каждом изменении в CGI.
Другой способ - сделать каталог свободным для чтения и записи, фактически сняв с него всякую защиту. Поскольку из внешнего мира получить доступ к этим файлам можно только через вашу программу, опасность не так велика, как может показаться. Однако если в программе обнаружится прореха, удаленный пользователь получит полный доступ ко всем файлам, в том числе возможность уничтожить их. Кроме того, законные пользователи, работающие на сервере, также получат возможность изменять эти файлы. Если вы собираетесь воспользоваться этим методом, то все пользователи сервера должны заслуживать доверия. Кроме того, используйте открытый каталог только для файлов, которые необходимы CGI-программе; иными словами, не подвергайте риску лишние файлы.
Что еще можно почитать
Если это ваше первое обращение к CGI-программированию, дальнейшее изучение можно продолжить разными путями. По этому предмету написаны десятки книг, многие из которых не предполагают никакого знакомства с программированием. «CGI Programming on the World Wide Web» издательства O'Reilly and Associates охватывает материал от простых сценариев на разных языках до действительно поразительных трюков и ухищрений. Общедоступная информация имеется также в изобилии в WWW. Неплохо начать с CGI Made Really Easy (Действительно просто о CGI) по адресу http://www.jmarshall.com/easy/cgi/.
DBI
Рекомендуемым методом доступа к базам данных MySQL и mSQL из Perl является интерфейс DBD/DBI. DBD/DBI означает DataBase Dependent/DataBase Independent (Зависимый от базы данных/Независимый от базы данных). Название связано с двухъярусной реализацией интерфейса. В нижнем ярусе находится зависимый от базы данных уровень. На нем существуют свои модули для каждого типа базы данных, доступного из Perl. Поверх этого уровня находится независимый от базы данных уровень. Это тот интерфейс, которым вы пользуетесь при доступе к базе данных. Выгода такой схемы в том, что программисту нужно знать только один API уровня независимости от базы данных. Когда появляется новая база данных, кому-нибудь нужно лишь написать для нее модуль DBD (зависимый), и она станет доступна всем программистам, использующим DBD/DBI.
Как и в любом модуле Perl, для получения доступа нужно указать DBI в директиве use:
#!/usr/bin/perl -w
use strict;
use CGI qw(:standard);
use DBI;

Всякое взаимодействие между Perl, с одной стороны, и MySQL и mSQL - с другой, производится с помощью объекта, известного как описатель базы данных (handle). Описатель базы данных (database handle) - это объект, представленный в Perl как скалярная ссылка и реализующий все методы, используемые для связи с базой данных. Одновременно можно открыть любое число описателей базы данных, ограничение накладывают только ресурсы системы. Метод connect() использует для создания описателя формат соединения DBI:servertype:database:hostname:port (имя узла и порта необязательны), дополнительными аргументами служат имя пользователя и пароль:
my $dbh = DBI->connect( 'DBI:mysql:mydata ', undef, Lindef);
my $dbh = DBI->connect( 'DBI:mSQL:mydata:myserver', undef, undef);
my $dbh = DBI->connect( 'DBI:mysql:mydata', 'me', 'mypass")',
Атрибут servertype является именем специфического для базы данных DBD-модуля, в нашем случае «mysql» или «mSQL» (обратите внимание на точное использование регистра). В первом варианте создается соединение с сервером MySQL на локальной машине через сокет Unix. Это наиболее эффективный способ связи с базой данных, который должен использоваться при соединении на локальном сервере. Если указано имя узла, оно используется для соединения с сервером на этом узле через стандартный порт, если только не задан и номер порта. Если при соединении с сервером MySQL вы не указываете имя пользователя и пароль, то пользователь, выполняющий программу, должен обладать достаточными привилегиями в базе данных MySQL. Для баз данных mSQL имя пользователя и пароль не должны указываться.
Как только вы соединились с сервером MySQL или mSQL, описатель базы данных - во всех примерах этого раздела $dbh - становится шлюзом к базе данных. Например, так готовится запрос SQL:
$dbh->prepare($query);

В главе 21 «Справочник по Perl», описаны все методы и переменные, содержащиеся как в DBI, так и в Mysql.pm и Msql.pm.
Для иллюстрации использования DBI рассмотрим следующие простые программы. В примере 10-1 datashow.cgi принимает в качестве параметра имя узла; при отсутствии параметра принимается имя «local-host». Затем программа выводит список всех баз данных, имеющихся на этом узле.
Пример 10-1. Программа CGI datashow.cgi показывает все базы данных, имеющиеся на сервере MySQL или mSQL
#!/usr/bin/perl -w
use strict;
use CGI qw( standard);
use CGI::Carp;
# Использовать модуль DBI use DBI; CGI::use_named_parameters(1);
my ($server, $sock, $host);
my $output = new CGI;
$server = param('server') or Sserver = '';
# Подготовить DBD-драйвер для MySQL
my $driver = DBI->install_driver('mysql');
my @databases = $driver->func($server, '_ListDBs');
# Если параметр @databases неопределен, предполагаем,
# что на этом узле не запущен
# сервер MySQL. Однако это может быть вызвано
# другими причинами. Полный текст сообщения об ошибке
# можно получить, проверив $DBI::errmsg.
if (not @databases) {
print header, start_html('title'=>"Данные no Sserver", 'BGCOLOR'=>'white');
print<<END_OF_HTML; <H1>$server</h1>
Ha Sserver , по-видимому, не запущен сервер mSQL. </body></html> END_OF_HTML
exit(0); }
print header, start_html('title'=>" Данные по $host",
'BGCOLOR'=>'white'); print <<END_OF_HTML; <H1>$host</h1>
<P>
Соединение с $host на сокете $sock.
<p>
Базы данных:<br>
<UL>
END_OF_HTML
foreach(@databases) {
print "<LI>$_\n"; }
print <<END_OF_HTML;
</ul>
</body></html>
HTML
exit(0)
В примере 10-2 tableshow.cgi принимает в качестве параметров имя сервера базы данных (по умолчанию «localhost») и имя базы данных на этом сервере. Затем программа показывает все таблицы, имеющиеся в этой базе данных.
Пример 10-2. Программа CGI tableshow.cgi выводит список всех таблиц в базе данных
#!/usr/bin/perl -w
use strict;
use CGI qw(:standard);
use CGI::Carp;
# Использовать модуль Msql.pm use DBI; CGI::use_named_parameters(1);
my ($db);
my $output = new CGI;
$db = param('db')'or die("He указана база данных!");
# Connect to the requested server.
my $dbh = DBI->connect("DBI:mysql:$db;$server", undef, undef);
# Если не существует $dbh, значит, попытка соединения с сервером
# базы данных не удалась. Возможно, сервер не запущен,
# или не существует указанной базы данных, if (not $dbh) {
print header, start_html('title'=>"Данные по $host => $db", 'BGCOLOR'=>'white');
print <<END_OF_HTML; <H1>$host</h1> <H2>$db</h2>
Попытка соединения не удалась по следующей причине:<BR> $DBI::errstr
</body></html>
END_OF_HTML
exit(0); }
print header, start_html('title'=>"Данные по $host => $db", 'BGCOLOR'=>'white'); print <<END_OF_HTML; <H1>$host</h1> <H2>$db</h2>
<р>
Таблицы:<br>
<UL>
END_OF_HTML
# $dbh->listtable возвращает массив таблиц,
# имеющихся в текущей базе данных.
my ©tables = $dbh->func( '_ListTables' );
foreach (@tables) {
print "<LI>$_\n"; }
print <<END_OF_HTML; </ul>
</body></html> END_OF_HTML
exit(0);
И наконец, пример 10- 3 показывает, как вывести все сведения о некоторой таблице.
Пример 10-3. Программа CGI tabledump.cgi выводит сведения об указанной таблице
#!/usr/bin/perl -w
use strict;
use CGI qw(:standard);
use CGI::Carp;
# Использовать модуль DBI use DBI; CGI::use_named_parameters(1);
my ($db,Stable);
my Soutput = new CGI;
$server = param('server') or $server = ";
$db = param('db') or die("He указана база данных !");
# Соединиться с указанным сервером.
my $dbh = DBI->connect("DBI:mysql:$db:$server", undef, undef);
# Готовим запрос к серверу, требующий все данные
# таблицы.
my $table_data = $dbh->prepare("select * from Stable");
# Посылаем запрос серверу.
$table_data->execute;
# Если возвращаемое значение не определено, таблица не существует
# или пуста; мы не проверяем, что из двух верно.
if (not $table_data) {
print header, startjtml( 'title'=>
"Данные по $host => $db => Stable", 'BGCOLOR'=>'white');
prin<<END_OF_HTML;
<H1>$host</h1>
<H2>$db</h2>
Таблицы'Stable' нет в $db на $host.
</body></html>
END_OF_HTML
exit(0); }
# Теперь мы знаем, что есть данные для выдачи. Сначала выведем
# структуру таблицы.
print header, start_html( title'=>"Данные по $host => $db => $table",
'BGCOLOR'=>'white');
print <<END_OF_HTML; <H1>$host</h1> <H2>$db</h2> <H3>$table</h3>
<P>
<TABLE BOROER> <CAPTION>Пoля</caption> <TR>
<ТН>Поле<ТН>Тип<ТН>Размер<ТН>МОТ NULL </tr> <UL> END_OF_HTML
If $table_data->name возвращает ссылку
# на массив полей таблицы.
my ©fields = @{$table_data->NAME};
# $table_data->type возвращает ссылку на массив типов полей.
# Возвращаемые типы имеют стандартные обозначения SQL,
# а не специфические для MySQL.
my @types = @{$table_data->TYPE};
# $table_data-> is_not_null возвращает ссылку на массив типа Boolean,
# указывающий, в каких полях установлен флат 'NOT NULL'.
my @>not_null = @{$table_data->is_not_null};
# $table_data->length возвращает ссылку на массив длин полей. Они
фиксированные
# для типов INT и REAL, но переменые (заданные при создании
# таблицы) для CHAR.
my @length = @{$table_data->length};
# Все перечисленные выше массивы возвращаются в одном и том же порядке,
# поэтому $fields[0], $types[0], $ndt_null[0] and $length[0] относятся к одному полю.
foreach $field (0..$#fields) {
print "<TR>\n";
print "<TD>$fields[$field]<TD>$types[$field]<TD>";
print $length[$field]
if $types[$field] eq 'SQL_CHAR';
print "<TD>";
print 'Y' if ($not_null[$field]);
print "</tr>\n"; }
print <<END_OF_HTML; </table>
<P>
<B>Data</b><br>
<OL>
END_OF_HTML
# Теперь мы будем построчно перемещаться по данным с помощью DBI::fetchrow_array().
# Мы сохраним данные в массиве в таком же порядке, как и в информационных
# массивах (§fields, @types, etc,), которые мы создали раньше.
while(my(@data)=$table_data->fetchrow_array) {
print "<LI>\n<UL>";
for (0..$#data) {
print "<LI>$fields[$_] => $data[$_]</li>\n"; }
print "</ulx/li>"; }
print «END_OF_HTML;
</ol>
</body></html>
END_OF_HTML
Язык программирования Perl превратился из
Perl
Язык программирования Perl превратился из инструмента, используемого преимущественно администраторами Unix-систем, в наиболее распространенную платформу разработки для World Wide Web. Perl не предназначался изначально для Web, но простота его использования и мощные функции для работы с текстом сделали естественным его применение для CGI-программирования. Сходным образом, когда mSQL впервые появилась на сцене, исключительные компактность и скорость выполнения сделали ее очень привлекательной для разработчиков Web, которым требовалось обслуживать ежедневно тысячи операций. MySQL со своей высокой скоростью и расширенными возможностями стала еще более привлекательным средством для веб-разработчиков. Естественно поэтому, что был разработан интерфейс Perl к обеим базам - MySQL и mSQL, - объединив таким образом их достоинства.
Msql.pm
Модуль Msql.pm является изначальным интерфейсом Perl к mSQL. Хотя его заменили модули DBI, все же осталось много сайтов, основанных на этом старом интерфейсе. Чтобы продемонстрировать использование Msql.pm, мы продолжим работу с нашим примером «помощника учителя».
Поскольку нам требуется определить школьные классы, в которых будут проводиться экзамены, рассмотрим таблицу предметов. Ее структура выглядит так:
CREATE TABLE subject (
id INT NOT NULL,
name CHAR(500),
teacher CHAR(100) )
CREATE UNIQUE INDEX idxl ON subject (
id,
name,
teacher
)
CREATE SEQUENCE ON subject
Число id является уникальным идентификатором школьного класса, а поля name и teacher являются наименованием курса и фамилией преподавателя соответственно. Все три поля проиндексированы, что ускоряет выполнение запросов. И наконец, мы определили последовательность для таблицы. Эта последовательность генерирует ID.
CGI-программа для обработки этих данных должна выполнять несколько функций:
Находить предмет в базе данных.
Выводить найденный предмет.
Добавлять в базу данных новый предмет.
Изменять параметры предмета в базе данных.
Используя мощь Perl и mSQL, можно без труда объединить все эти функции в одном файле, subject.cgi. Для каждой из операций мы создадим свою функцию. Центральной частью программы будет своего рода коммутатор, распределяющий поступающие запросы по соответствующим функциям. Сами операции мы опишем позднее.
#Выбор нужной части сценария осуществляется в зависимости
# от параметра 'action'.
# Если 'action' не задан, вызывается функция defaultQ.
&default if not param('action');
# Этот прием из Camel 2 имитирует переключатель 'switch' в языке С. foreach[A04] (param('action')) {
/view/ and do { Sview; last; };
/add$/ and do { &add; last; };
/add2/ and do { Sadd2; last; };
/add3/ and do { &add3; last; };
/add4/ and do { &add4; last; };
/schange$/ and do { &schange; last; };
/schange2/ and do { &schange2; last; };
/lchange$/ and do { &lchange; last; };
/Ichange2/ and do { &lchange2; last; };
/IchangeS/ and do { &lchange3; last; };
/delete/ and do { Sdelete; last; };
&default; }
Остается лишь проработать детали, реализовав каждую функцию.
Функция default выводит исходную форму, которую видит пользователь, позволяющую ему выбрать тип операции. Эта функция вызывается, если CGI-программа вызывается без параметров, например, как http://www.myserver.com/teach/subject.cgi, или если параметр ACTION не соответствует ни одной из существующих функций. Можно было бы также создать функцию, выводящую сообщение об ошибке, если параметр ACTION неизвестен.
sub default {
print header, start_html('title'=>'Subjects', 'BGCOLOR'=>'white'):
print «END_OF_HTML; <h1>Предметы</h1>
<р>Выберите операцию и предмет (если это допустимо).
<FORM ACTION="subject.cgi" METHOD=POST>
<p>
<SELECT NAME="action">
<OPTION VALUE="view">npocмотp предмета
<OPTION VALUE="аdd">Добавление предмета
<OPTION VALUE="schange">Изменение предмета
<OPTION VALUE="lchange" SELECTED>Изменить список классов
<OPTION VALUE="delete">Удалить предмет </select>
END_OF_HTML
# См. ниже 'sub print_subjects'.
&print_subjects;
print «END_OF_HTML;
<P>
<INPUT TYPE=SUBMIT VALUE="Выполнить операцию">
<INPUT TYPE=RESET>
</form></body></html>
HTML
}
Основных операций пять: «view» (просмотр), «add» (добавление), «schange» (изменение данных о предмете), «Ichange» ( изменить список классов по предмету) и «delete» (удалить). Например, мы подробно рассмотрим операцию «add». Она разбита на четыре отдельные функции, потому что диалог с пользователем приходится проводить до четырех раз. Для передачи данных от одной формы к другой используются скрытые переменные, пока, в конце концов, не будет создан класс.
Первая функция порождает форму для ввода начальных сведений о классе, в том числе его названия, имени учителя и количества учащихся.
sub add {
my (%fields);
foreach ('name','size','teacher') {
if (param($_)) { $fields{$_} = param($_); } else { $fields{$_} = ""; } }
print header, start_html('title'=>'Add a Subject','BGCOLOR'=>'white');
print «END_OF_HTML; <H1>Add a Subject</h1> <form METHOD=POST ACTION="subject.cgi"> <P>
Название предмета:
<input size=40 name="name" value="$fields{'name'}"><br>
Фамилия учителя:
<input size=40 name="teacher" value="$fields{'teacher'}"><br>
Число учащихся в классе:
<input size=5 name="size" value="$fields{'size'}">
<P>
<INPUT TYPE=HIDDEN NAME="action" VALUE="add2">
<INPUT TYPE=SUBMIT VALUE="Следующая страница ">
<INPUT TYPE=RESET>
</form>
<P>
<A HREF="subject.cgi">Перейти</a> назад к главной странице предметов.<br>
<А HREF=". ">Перейти</а> к домашней странице Помощи учителю.
</body></html>
END_OF_HTHL
}
Функция проверяет, не имеют ли какие-либо поля предустановленные значения. Это придает функции дополнительную гибкость, позволяя использовать ее как шаблон для классов со значениями по умолчанию, возможно, генерируемыми какой-либо другой CGI-программой.
Значения, полученные в первой части процесса добавления, передаются обратно CGI-программе для использования в функции add2. Функция add2 сначала проверяет, существует ли уже класс. Если существует, то пользователю посылается сообщение об ошибке, и он может изменить название класса.
Если класс еще не существует, функция проверяет, какое число учащихся введено. Если никакое, то класс создается без учащихся, их можно добавить позднее. Если нее число задано, создается класс и выводится форма, в которую можно ввести данные о каждом учащемся.
sub add2 {
my $name = param('name');
# Нам нужна копия имени, которая кодируется для URL.
my $enc_name = &cgi_encode($name);
# Нам также нужна копия имени, которую можно спокойно цитировать для
# ввода в базу. Msql использует с этой целью функцию Msql::quote().
my $query_name = $dbh->quote($name);
# Строим запрос для проверки существования предмета,
my $query ="select id, name, teacher from subject where name=$query_name";
#Если пользователь ввел фамилию учителя, отдельно проверяем фамилию,
# поскольку могут быть два курса с одинаковым названием, но
# разными учителями.
if (param('teacher')) {
$teacher = param('teacher');
$enc_teacher = &cgi_encode($teacher);
my $query_teacher = $dbh->quote($teacher);
$query .= " and teacher=$query_teacher"; }
# Теперь посылаем запрос серверу mSQL
my $out = $dbh->query($query);
ft Проверяем значение $out->numrows, чтобы узнать, были ли возвращены
# какие-либо строки. Если были, и пользователь не задал параметр 'override'
# (переопределить), то мы выходим с сообщением, что класс уже
# существует, и давая пользователю возможность все-таки ввести класс
# (повторно передав форму с установленным параметром 'override',
if ($out->numrows and not param('override')) { # Печать страницы 'Класс уже существует'.
} else {
# Теперь вводим данные в базу.
# Сначала нужно выбрать новое число из
# последовательности для таблицы.
$out = $dbh->query("select _seq from subject");
my ($id) = $out->fetchrow;
# Теперь вводим информацию в базу данных, используя
# полученное из последовательности число в качестве ID.
$query = "INSERT INTO subject (id, name, teacher)
VALUES ($id, '$name', 'Steacher')"; $dbh->query($query);
# Если пользователь не задал размер класса, выходим
# с сообщением о том, что пользователь может добавить
# число учащихся позже, if (not param('size')) {
# Вывод страницы с сообщением об успехе.
} else { \
# Теперь выводим форму, позволяющую пользователю
# ввести имена всех учащихся в классе.
print header, start_html('title'=>'Create Class List',
'BGCOLOR'=>'white'); print <<END_OF_HTML;
<Н1>Создать список класса</h1> <P>
<B>$name</b>
добавлен в базу данных. Теперь можно ввести фамилии учащихся в этом классе. Добавить или исключить учащихся можно позднее с главной страницы предметов
<а href="subject.cgi"> </a>.
<Р>
<FORM METHOD=POST ACTION="subject.cgi">
<INPUT TYPE=HIDDEN NAME="action" VALUE="add3">
<INPUT TYPE=HIDDEN NAME="id" VALUE="$id">
<table>
<ТР><ТН><ТН>Имя<ТН>Отчество/Инициал
<ТН>Фамилия<ТН>мл.,ст.,III,и т.д.
</tr>
END_OF_'HTML
for $i (1.,$size) {
print <<END_OF_HTML;
<TR><TD>$i<TD><INPUT SIZE=15 NAME="first$i"><TD>
<lNPUT SIZE=15 NAME="middle$i">
<TD><INPUT SIZE=15 NAME="last$i"><TD>
<INPUT SIZE=5 NAME="ext$i"></tr>
END_OF_HTML
}
print <<END_OF_HTML; </table>
<INPUT TYPE=SUBMIT VALUE=" Ввести список класса ">
<INPUT TYPE=RESET> </form>
</body></html>
END_OF_HTML
} } }
Обратите внимание, что функция использовала три копии параметра name. Для использования в составе URL все специальные символы должны быть заменены особым образом. Для этого в коде примера используется функция cgi_encode . Кроме того, чтобы ввести строку в базу данных mSQL, вместо некоторых символов нужно использовать управляющие символы. Интерфейс MsqlPerl предоставляет для этого функцию quote, доступную через любой описатель базы данных. Наконец, при выводе на экран используется непреобразованный вариант переменной.
При добавлении класса в базу данных удобно использовать такую функцию mSQL, как последовательности. Вспомним, что в таблице class была определена последовательность. Ее значения используются в качестве уникального идентификатора для каждого класса. Благодаря этому два класса могут иметь одинаковые названия (или одного и того же учителя и т. д.) и все же быть различными. Это также окажется удобным при дальнейших изменениях в классе. Пока между формами передается уникальный ID, все прочие данные о классе можно свободно изменять.
Наконец, отметим, что выводимая этой функцией форма для ввода учащихся генерируется динамически. Для вывода формы с правильным числом записей используется введенное раньше число учащихся. Помните, что CGI-программа полностью управляет генерируемым HTML. Любая часть, включая формы, может быть создана программным образом.
Если пользователь не ввел никаких учащихся, то работа на этом закончена. Позднее для добавления учащихся можно воспользоваться функцией модификации. Однако если требуется ввести учащихся, данные о них передаются функции add3, как показано ниже:
sub add3 {
if (not param('id')) { &end("Требуется числовой ID"); }
my $id = param( 'id');
my ©list = &find_last_student;
my ($ref_students,$ref_notstudents) = &find_matching_students(@list);
@students = @$ref_students
if $ref_students;
@notstudents = @$ref_notstudents
if $ref_notstudents;
if (@notstudents) {
# Вывести форму, говорящую пользователю, что в списке
# есть несуществующие учащиеся. Пользователь может автоматически
# создать учащихся или вернуться и исправить опечатки.
} else {
&update_students($id,@students);
#Вывести форму успешного завершения работы.
} }
В этой функции основная часть работы выполняется другими функциями. Это обусловлено тем, что в других частях CGI-программы возникают сходные задачи, которые полезно решать с помощью совместно используемых функций. Первая такая функция - f ind_last_student , которая изучает данные формы и возвращает список имеющихся в форме номеров, не связанных с ID в базе данных, всех введенных пользователем учащихся. Это необходимо, поскольку, как упоминалось раньше, предыдущая форма генерируется динамически и нет возможности непосредственно узнать, сколько учащихся включено.
sub find_last_student {
my @params = param; my @list = (); foreach (@params) {
next if not param($_);
# Исключить все 'пустые' поля
if (/-(first|middle|last|ext)(\d+)/) {
my $num = $2;
if (not grep(/"$num$/,@list)) { push(@list,$num); } } }
@list = sort { $a <=> $b} @list; return @list;
}
Обратите внимание, что функция возвращает все числа, а не только последнее, которое, предположительно, будет числом введенных учащихся. Хотя предыдущая форма вывела число запрошенных пользователем записей, нет гарантии, что пользователь заполнил их все. Он мог пропустить строку, которая не будет включена в данные формы. Поэтому необходимо выявить все введенные числа. Результаты работы этой функции пересылаются следующей вспомогательной функции find_matching_students , как показано ниже:
sub find_matching_students { my §list = @_;
my ($i,@students,@notstudents); §students = ();
@notstudents = ();
if (@list) {
foreach $i (@list) {
my @query = ();
# Строим запрос, который ищет заданного учащегося,
my $query = "select id, subjects from student where ";
foreach ('first','middle','last', 'ext') {
if (param("$_$i")) {
my $temp = param("$_$i");
# В mSQL и MySQL одиночные кавычки служат ограничителями
# имен полей, и им должен предшествовать
# управляющий символ "\",
# который управляет и сам собой,
# чтобы быть введенным буквально.
$temp =~ s/7\\'/g;
push(@query, "$_ = '$temp'"); } }
$query = join(" and ",§query);
# Посылаем запрос базе данных.
my $out = $dbh->query($query);
# Если база данных ничего не возвращает, добавляем
# учащегося к массиву @notstudents.
if (not $out->numrows) {
push(@notstudents, [ param("first$i"), param("middle$i"), param("last$i"), param("ext$i") ]);
# В противном случае добавляем студента в массив ©students.
} else {
my ($id,$subjects) = $out->fetchrow;
push(@students,[$id,$subjects]); } } }
return(\§students,\@notstudents); }
Эта функция пробегает по всем заданным именам учащихся и проверяет, есть ли уже они в базе данных. Если они существуют, данные о них записываются в массив с именем ©students , в противном случае - в массив @notstudents . Данные о каждом учащемся хранятся в безымянном массиве, создавая своего рода объект учащегося. В итоге функция возвращает ссылки на оба массива. Она не может возвратить данные как обычный массив, поскольку будет невозможно определить, где закончился один массив и начался другой.
И последняя вспомогательная функция - update_students , которая добавляет класс к списку классов для каждого существующего учащегося.
sub update_students {
my $id = shift;
my ©students = @_;
foreach (©students) {
my($sid, $subjects)=©$_;
if (not Ssubjects) { Ssubjects = ":$id:"; }
elsif (Ssubjects !" /:$id:/)
{ Ssubjects .= "$id:"; }
my $query = "update sti/dent set subjects='Ssubjects'
where id=$id";
$dbh->query($query); } }
Эта функция осуществляет запрос к таблице student, совершенно независимой от таблицы subject. В пределах одной CGI-программы можно работать с любым числом различных таблиц одной базы данных. Можно переключаться с одной базы данных на другую, но одновременно может быть активна только одна база данных. Эта функция извлекает список предметов для каждого учащегося и добавляет к нему новый предмет, если его еще нет в списке.
Функция обрабатывает все возможные случаи, кроме одного, когда к предмету приписаны учащиеся, которых еще нет в таблице student. В этом случае список новых учащихся передается функции add4, как показано ниже:
sub add4 {
#получить список ©students и @notstudents
&update_students($id,@students) if @students;
&insert_students($id,@notstudents) if @notstudents;
# Вывести страницу успешного завершения. }
Эта функция разделяет список учащихся на существующих и несуществующих тем же способом, что и add3. Затем она обновляет список существующих учащихся с помощью функции update_students , показанной раньше. Несуществующие учащиеся посылаются новой вспомогательной функции insert_students :
sub insert_students { foreach $i (@list) {
# Производится выбор очередного числа из последовательности,
# определенной в таблице. Зто число используется как ID учащегося,
my $out = $dbh->query('select _seq from student');
my($sid) = $out->fetchrow;
# Для включения в базу данных все строки
# нужно процитировать.
my ($first, $middle, $last, $ext) = (
$dbh->quote(param("first$i")),
$dbh->quote(param("middle$i")),
$dbh->quote(param("last$i")),
$dbh->quote(param("ext$i")) );
my $query = "insert into student (id, first, middle, last,
ext, subjects) VALUES ($sid, $first, $middle,
$last, $ext, ':$id:')";
$dbh->query($query); } }
И эта функция обращается к таблице student, а не subject. Из последовательности, определенной в таблице student, извлекаются ID для новых учащихся, затем учащиеся вводятся в таблицу с этими ID.
MysqIPerl
Монти Видениус, автор MySQL, написал также и интерфейс Perl к MySQL, Mysql.pm. Он основывался на модуле Msql.pm для mSQL, поэтому интерфейсы двух модулей почти идентичны. На практике мы недавно преобразовали целый сайт из mSQL в MySQL, выполнив команду «perl -e 's/^Msql/Mysql/>> *.cgi» в каждом каталоге, содержащем CGI. Это составило 95% всей работы. Разумеется, при этом вы не получаете преимуществ MySQL, но таким путем можно быстро и легко встать на путь использования MySQL. Mysql.pm входит составной частью в пакет msql-mysql-modules Йохена Видмана (Jochen Wiedmann).
Чтобы показать некоторые функции Mysql.pm, вернемся к примеру с экзаменами. Разобравшись с subject.cgi, займемся таблицей сведений об учащихся. Ее структура такова:
CREATE TABLE student (
id INT NOT NULL auto_increment,
first VARCHAR(50),
middle VARCHAR(50),
last VARCHAR(50),
ext VARCHAR(50),
subjects VARCHAR(100),
age INT,
sex INT,
address BLOB,
city VARCHAR(50),
state VARCHAR(5),
zip VARCHAR(10),
phone VARCHAR(10),
PRIMARY KEY (id)
)
В этой таблице находятся все данные, используемые программой subject, cgi, a также другие сведения, которые относятся к учащемуся. Программа student.cgi, работающая с этой таблицей, должна выполнять все те функции, которые программа subject.cgi выполняла в отношении таблицы subject.
Чтобы продемонстрировать, как работает Mysql.pm, мы подробно изучим ту часть student.cgi, которая позволяет пользователю изменять сведения об учащемся. Так же как операция «add» (добавление) в примере для Msql.pm была разбита на четыре отдельные функции, операция «change» (изменение) разбита здесь на три отдельные функции.
Первая функция - изменения, выводит форму, позволяющую пользователю найти учащегося, данные о котором нужно изменить:
sub change {
print header, start_html('title'=>'Поиск учащегося для изменения денных'
'BGCOLOR'=>'white');
&print_form('search2', Поиск учащегося для изменения данных',1);
print <<END_OF_HTML; <р>
<INPUT TYPE=HIDDEN NAME="subaction" VALUE="change2">
<INPUT TYPE=SUBMIT VALUE=" Искать учащегося ">
<INPUT TYPE=SUBMIT NAME="all" VALUE=" Просмотр всех учащихся ">
<INPUT TYPE=RESET>
</form></body></html>
END_OF_HTML }
Форма, используемая для поиска учащегося с целью изменения, настолько сходна с формами для просмотра данных и для добавления, что во всех трех случаях используется одна функция, print_form , показанная ниже:
sub print_form {
my ($action,$message,$any) = @_;
print <<END_OF_HTML;
<FORM METHOD=post ACTION="students.cgi">
<INPUT TYPE=HIDDEN NAME="action" VALUE="$action">
<H1>$message</h1>
END_OF_HTML
if ($any) {
print <<END_OF_HTML; <р>Поиск
<SELECT NAME="bool">
<OPTION VALUE="ог">любой
<OPTION VALUE="and">Bce </select> выбранные вами.
END_OF_HTML
У
print <<END_OF_HTML; <P>
Имя:
<INPUT NAME="first" SIZE=20>
Отчество:
<INPUT NAME="middle" SIZE=10>
Фамилия:
<INPUT NAME="last" SIZE=20>
МЛ./III/И т.д..:
<INPUT NAME="ext" SIZE=5> <br>
Адрес:
<INPUT NAME="address" SIZE=40><br>
Город:
<INPUT NAME="city" SIZE=20>
Штат:
<INPUT NAME="state" SIZE=5>
Почтовый индекс:
<INPUT NAME="zip" SIZE=10><br>
Телефон:
<INPUT NAME="phone" SIZE=15><br>
Возраст:
<INPUT NAME="age" SIZE=5>
Пол:
<SELECT NAME="sex">
END_OF_HTML
if ($any) {
print <<END_OF_HTML; <OPTION VALUE="">He имеет значения
END_OF_HTML
}
print <<END_OF_HTML;
<OPTION VALUE="1">Myжской
<OPTION VALUE="2">Женский
</select><br>
<P>
Записан на:<br>
END_OF_HTML
&print_subjects("MULTIPLE SIZE=5");
}
Благодаря использованию трех параметров эта функция настраивает шаблон формы так, что может использоваться в самых различных целях. Обратите внимание, что эта вспомогательная функция использует другую вспомогательную функцию, print_subjects . Последняя выводит список всех имеющихся предметов из таблицы subject, как в примере Msql.pm.
sub print_subjects { my $modifier = "";
$modifier = shift if @_;
print qq%<SELECT NAME="subjects" $modifier>\n%;
my $out = $dbh->query("select * from subject order by name");
while(my(%keys)=$out->fetchhash) {
print qq%<OPTION VALUE="$keys{'id'}">$keys{'name'}\n%;
}
print "</select>\n";
}
Параметры поиска, введенные в первую форму, передаются функции search2, фактически осуществляющей поиск. На самом деле это функция, написанная для поиска учащегося, данные о котором нужно показать. Поскольку она делает как раз то, что нам требуется, мы можем ею воспользоваться, если сообщим ей, что после поиска хотим перейти
к следующей функции изменения, change2. Для этого мы ввели в форму скрытую переменную subaction=change2 . Она сообщает search2, куда отправить пользователя дальше:
sub search2 {
my $out = $dbh->query(&make_search_query);
my $hits = $out->numrows;
my $subaction = "view";
$subaction = param('subaction')
if param('subaction');
print header, start_html('title'=>'Результаты поиска учащихся', 'BGCOLOR'=>'white');
if (not Shits) {
print <<END_OF_HTML;
<Н1>Учащихся не найдено</h1>
<P>
He найдено учащихся, удовлетворяющих вашему критерию.
END_OF_HTML } else {
print <<END_OF_HTML;
<H1> Найдено $hits учащихся </h1> <р>
<UL>
END_OF_HTML
while(my(%fields)=$out->fetchhash) {
print qq%<LI>
<A HREF="students.cgi?action=$subaction&id=$fields
{'id'}">$fields{'first'} $fields{'middle'} $fields{'last'}%;
print ", $fields{'ext'}" if $fields{'ext'};
print "\n</a>"; } }
print <<END_OF_HTML; </ul> <p>
<A HREF="students.cgi?action=search">HcKaTb</a> снова.
</body></html>
END_OF_HTML }
С помощью функции make_search_query эта функция сначала ищет учащихся, отвечающих критериям поиска. Затем она выводит список найденных записей, среди которых пользователь может сделать выбор. ID выбранной записи передается функции change2, как показано ниже:
sub change2 {
my $out = $dbh->query
("select * from student where id=$id");
my($did,Ifirst,$middle,$last,
$ext,Ssubjects.Sage,$sex,$address,
$city,$state,$zip,$phone) = $out->fetch row;
my ©subjects = split(/:/,$subjects);
shift,©subjects;
my $name = "$first $tmiddle $last";
if ($ext) { $name .= ", $ext"; }
print header, start_html('title'=>"$name", 'BGCOLOR'=>'white');
print <<END_OF_HTML;
<H1>$name</h1> <p>
<FORM ACTION="students.cgi" METHOD=POST>
<INPUT TYPE=HIDDEN NAME="action" VALUE="change3">
<INPUT TYPE^HIDDEN NAME="id" VALUE="$id">
Имя:
<INPUT NAME="first" VALUE="$first" SIZE=20>
Отчество:
<INPUT NAME="middle" VALUE="$middle" SIZE=10>
Фамилия:
<INPUT NAME="last" VALUE="$last" SIZE=20>
МЛ./III/И т.д.
<INPUT NAME="ext" VALUE="$ext" SIZE=5> <br>
Адрес:
<INPUT NAME="address" VALUE="$address" SIZE=40><br>
Город:
<INPUT NAME="city" VALUE="$city" SIZE=20>
Штат:
<INPUT NAME="state" VALUE="$state" SIZE=5>
Почтовый индекс:
<INPUT NAME="zip" VALUE="$zip" SIZE=10xbr>
Телефон:
<INPUT NAME="phone" VALUE="$phone" SIZE=15><br>
Возраст:
<INPUT NAME="age" VALUE="$age" SIZE=5>
Пол:
END_OF_HTML
my %sexes = ( '1' => 'Мужской',
'2' => 'Женский' );
print popup_menu('name'=>'Пол', 'values'=>["!', '2'], 'default'=>"$sex", ' labels'=>\%sexes);
print <<END_OF_HTML; <p>
Записан на:<br>
END_OF_HTML
my @ids = ();
my %subjects = ();
my $out2 = $dbh->query("select id, name from subject order by name");
while(my($id,$subject)=$out2->fetchrow) { push(@ids,Sid);
$subjects{"$id"} = $subject; }
print scrolling_list('name'=>'subjects', 'values'=>[@ids], 'default'=>[@subjects], 'size'=>5, 'multiple'=>'true', 'labels'=>\%subjects);
print <<END_OF_HTML;
<р>
<INPUT TYPE=SUBMIT VALUE=" Изменить данные об учащемся ">
<INPUT TYPE=SUBMIT NAME="delete" VALUE=" Удалить учащегося ">
<INPUT TYPE=RESET>
</form></body></html>
END_OF_HTML
}
Главная задача этой функции - вывести форму, очень похожую на ту, которую порождает print^from. Однако значениями по умолчанию в этой форме должны быть те, которые соответствуют выбранному учащемуся. В результате пользователь может редактировать одни поля, оставляя другие неизменными.
Несколько функций, предоставляемых модулем CGI.pm, оказываются очень удобными при выводе формы со значениями, установленными по умолчанию, особенно функция CGI: :scrolling_list , выводящая блок HTML <SELECT> с заданными параметрами. Среди прочих, функция принимает параметры values, default и labels, относящиеся к значениям каждого тега <OPTION> , задающие выбираемые по умолчанию пункты и их метки, видимые пользователю.
Эта функция выводит заполненную форму, как если бы это была форма для добавления. Разница в том, что это данные для учащегося, уже имеющегося в базе данных. Функция changes принимает данные и обновляет данные в базе, как показано ниже:
sub changes {
if (param('delete')) { &delete2($id); } else {
my Squery = "update student set "; my @query = ();
foreach ('first', 'middle', 'last', 'ext', 'address', 'city', 'state', 'zip', 'phone') {
if (param($_)) { push(@query,"$_ = ".
$dbh->quote(param($_))); } }
push(@query,"age=".param('age')) if param('age');
push(@query,"sex=".param('sex')) if param('sex');
my $subjects = "':";
$subjects .= join(":",param('subjects'));
$subjects .= ":" unless $subjects eq "':";
$subjects .= "'";
push(@query, "subjects=$subjects");
Squery .= join(", ",@query) . " where id=$id"; $dbh->query($query);
print header, start_html('title'=>'Данные об учащемся изменены',
'BGCOLOR'=>'white'); # Вывести форму с сообщением об успехе
}
}
Обратите внимание, что при выборе кнопки «Delete» на странице изменения функция автоматически передает управление функции удаления. Это одно из главных преимуществ объединения в одной программе нескольких функций. Если вмешательства пользователя не требуется, то можно перескакивать между функциями без посылки пользователю сообщений о перенаправлении.
Оставшаяся часть этой функции довольно проста. Данные об учащемся собираются в запросе UPDATE, который отправляется серверу MySQL. Затем пользователю посылается страница с сообщением об успешном завершении работы.
Пример приложения, использующего DBI
DBI допускает любые SQL-запросы, поддерживаемые MySQL и mSQL. Например, рассмотрим базу данных, используемую в школе для ведения учета учащихся, состава классов, результатов экзаменов и т. д. База данных должна содержать несколько таблиц: одну для данных о предметах, другую для данных об учащихся, таблицу для списка экзаменов и по одной таблице для каждого экзамена. Возможность MySQL и mSQL выбирать данные из нескольких таблиц, используя объединение таблиц, позволяет совместно использовать таблицы как согласованное целое для создания приложения, облегчающего работу учителя.
Для начала мы хотим учесть данные об экзаменах по разным предметам. Для этого нам нужна таблица, содержащая названия и числовые идентификаторы для экзаменов. Нам потребуется также отдельная таблица для каждого экзамена. В этой таблице будут содержаться результаты испытаний для всех учащихся, а также высший балл для проведения сравнения. Таблица test имеет следующую структуру:
CREATE TABLE test (
id INT NOT NULL AUTO_INCREMENT, name CHAR(100),
subject INT, num INT
Для каждого отдельного экзамена структура таблицы такая:
CREATE TABLE t7 (
id INT NOT NULL,
q1 INT,
q2 INT,
q3 INT,
q4 INT,
total INT
)
К имени таблицы t присоединен идентификатор экзамена из таблицы test. При создании таблицы пользователь определяет количество вопросов. Поле total содержит сумму баллов по всем вопросам.
Программа, обрабатывающая данные экзаменов, называется test.cgi. Эта программа, текст которой следует ниже, позволяет только добавлять новые экзамены. Просмотр экзаменов и их изменение не реализованы и оставлены в качестве упражнения. Дополнить этот сценарий будет несложной задачей, если воспользоваться в качестве справочного материала другими сценариями, приведенными в данной главе. Этот сценарий хорошо показывает возможности DBI:
#!/usr/bin/perl -w
use strict; require my_end;
use CGI qw(:standard);
my Soutput = new CGI;
use_named_parameters(1);
# Использовать модуль DBI. use DBI;
# DBI::connect() использует формат 'DBI:driver:database', в нашем случае
# используется драйвер MySQL и открывается база данных 'teach',
my $dbh = DBI->connect('DBI:mysql:teach');
# Операция добавления распределена между тремя отдельными функциями. Первая функция, add,
# выводит пользователю форму шаблона для создания нового экзамена,
sub add {
$subject = param('subject')
if (param('subjects'));
$subject = ""
if $subject eq 'all';
print header, start_html('title'=>'Create a New Test',
'BGCOLOR'=>'white'); print <<END_OF_HTML;
<Н1>Создание нового экзамена</п1> <FORM ACTION="test.cgi" METHOD=POST>
<INPUT TYPE=HIDDEN NAME="action" VALUE="add2"> Предмет: END_OF_HTML
my @ids = (); my %subjects = ();
my $out2 = $dbh->prepare("select id,name from subject order by name" $out2->execute;
# DBI: :fetchrow_array() совершенно аналогична Msql: :fetchrow()
while(my($id,$subject)=$out2->fetchrow_array) {
push(@ids,Sid); $subjects{"$id"} = Ssubject; }
print popup_menu('name'=>'subjects', 'values'=>[@ids], 'default'=>$subject, 'labels'=>\%subjects);
print <<END_OF_HTML; <br>
Число вопросов: <INPUT NAME="num" SIZE=5><br> Название или идентификатор (например, дата) экзамена:
<INPUT NAME="name" SIZE=20>
<Р>
<INPUT TYPE=SUBMIT VALUE=" Следующая страница ">
<INPUT TYPE=RESET> </form></body></html>
END_OF_HTML }
Эта функция выводит форму, позволяющую пользователю выбрать предмет для экзамена, а также количество вопросов и название. Для вывода списка имеющихся предметов выполняется запрос к таблице предметов. При выполнении в DBI запроса SELECT он должен быть сначала подготовлен, а затем выполнен. Функция DBI::prepare полезна при работе с некоторыми серверами баз данных, позволяющими осуществить операции над подготовленными запросами, прежде чем выполнить их. Для MySQL и mSQL это означает лишь запоминание запроса до вызова функции DBI:: execute .
Результаты работы этой функции посылаются функции add2, как по-: казано ниже:
sub add2 {
my Ssubject = param('subjects');
[
my $num = param('num');
$name = param('name') if param('name');
my $out = $dbl»prepare("select name from subject where id=$subject");
$out->execute;
my (Ssubname) = $out->fetchrow_a.rray;
print header, start_html('title'=>"Создание экзамена по предмету $subname", ' BGCOLOR'=>'white');
print <<END_OF_HTML;
<H1> Создание экзамена по предмету $subname</h1> <h2>$name</h2>
<P>
<FORM ACTION="test.cgi" METHOD=POST>
<INPUT TYPE=HIDDEN NAME="action" VALUE="add3">
<INPUT TYPE=HIDDEN NAME="subjects" VALUE="$subject">
<INPUT TYPE=HIDOEN NAME="num" VALUE="$num">
<INPUT TYPE=HIDDEN NAME="name" VALUE="$name">
Введите количество баллов за каждый правильный ответ.
Сумма баллов не обязательно должна равняться 100.
<Р> END_OF_HTML
for (1..$num) {
print qq%$_: <INPUT NAME="q$_" SIZE=3> %; if (not.$_ % 5)
{ print "<br>\n"; } } print <<END_OF_HTML;
<P>
Введите текст экзамена:<br>
<TEXTAREA NAME="test" ROWS=20 COLS=60> </textarea> <p>
<INPUT TYPE=SUBMIT VALUE="Ввести экзамен ">
<INPUT TYPE=RESET> </form></body></html>
END_OF_HTML }
Эта функция динамически генерирует форму для экзамена, основываясь на параметрах, введенных в предыдущей форме. Пользователь может ввести количество баллов для каждого вопроса экзамена и полный текст самого экзамена. Выходные данные этой функции посылаются завершающей функции add3, как показано ниже:
sub add3 {
my $subject = para'm( 'subjects');
my $num = param('num');
$name = param('name') if param('name');
my $qname;
($qname = $name) =" s/'/\\'/g;
my $q1 = "insert into test (id, name, subject, num) values ( '.'-, '$qname', $subject, $num)";
my Sin = $dbh->prepare($q1); $in->execute;
# Извлечем значение ID , которое MySQL создал для нас
my $id = $in->insertid;
my $query = "create table t$id ( id INT NOT NULL,
my $def = "insert into t$id values ( 0, ";
my $total = 0;
my @qs = grep(/^q\d+$/,param);
foreach (@qs) {
$query .= $_ . " INT,\n";
my $value = 0;
$value = param($_) if param($_);
$def .= "lvalue, ";
$total += $value; }
$query .= "total INT\n)"; $def .=-"$total)";
my $in2 = $dbh->prepare($query);
$in2->execute;
my $in3 = $dbh->prepare($def);
$in3->execute;
# Обратите внимание, что мы запоминаем экзамены в отдельных файлах. Это
# полезно при работе с mSQL, поскольку он не поддерживает BLOB.
# (Тип TEXT, поддерживаемый в mSQL 2, можно использовать,
# но это неэффективно.)
# Поскольку мы используем MySQL, можно с таким же успехом
# поместить весь экзамен в BLOB.
open(TEST,">teach/tests/$id") or die("A: $id $!");
print TEST param('test'), "\n";
close TEST;
print header, start_html('title'=>'Экзамен создан', 'BGCOLOR'=>'white');
print <<END_OF_HTML;
<Н1>Экзамен создан</h1> <P>
Экзамен создан.
<р>
<А HREF=".">Перейти</а> на домашнюю страницу 'В помощь учителю'.<br>
<А HREF="test.cgi">nepeimi</a> на главную страницу экзаменов.<br>
<А HREF="test.cgi?actio,n=add">Добавить</a> следующий экзамен.
</body></html>
END_OF_HTML
}
Теперь введем информацию об экзамене в базу данных. При этом мы шагнем дальше обычного ввода данных, который видели до сих пор. Данные по экзаменам достаточно сложны, поэтому каждый экзамен лучше хранить в собственной таблице. Вместо добавления данных в существующую таблицу мы создадим совершенно новую таблицу для каждого экзамена. Сначала мы создадим ID для нового экзамена с помощью функции автоинкрементирования MySQL и введем название и ID экзамена в таблицу с именем test. Эта таблица является просто указателем на экзамены, по ней можно легко найти ID любого экзамена. Затем мы создадим одновременно два запроса. Первый будет запросом CREATE TABLE, который определит наш новый экзамен. Второй запрос будет иметь тип INSERT и запишет в нашу таблицу максимальные баллы по каждому вопросу. Эти запросы будут отправлены серверу базы данных, что завершит весь процесс (после вывода пользователю страницы с сообщением об успешном завершении). Позднее, после сдачи экзамена учащимися, для каждого учащегося будет создана запись в таблице экзамена. Эти записи могут быть сравнены с максимальными значениями для определения оценки учащегося.
Динамическое соединение с базами данных
Тот метод API, который мы до сих пор обсуждали в этой главе, дает, в сущности, все необходимое для простых и наиболее часто встречающихся повседневных задач выборки, вставки, обновления и удаления данных в базе. В некоторых более сложных приложениях может оказаться, что вы ничего (или чего-нибудь) не знаете о базе данных, с которой соединяетесь и которой посылаете команды. Хотя оба API поддерживают метаданные уровня базы данных - информацию времени выполнения о базе данных, с которой соединены, - только MySQL API обеспечивает полную поддержку динамически генерируемых вызовов SQL, включая метаданные результирующего набора.
Описатели команд в MySQL
Как уже отмечалось, в MySQL есть два средства обработки запросов. Более простая форма возвращает результирующий набор в виде списка списков. Более сложная форма возвращает описатель команды.
Описатель команды представляет результаты обработки запроса к MySQL через метод query() (в противоположность использованию метода do()). Пример 11-2 показывает, как можно использовать описатель команды для получения информации времени выполнения о запросе или команде обновления.
Пример 11-2. Динамический доступ к базе данных MySQL с помощью описателя команды
[7:20pm] athens> python
Python 1.5.1 (#1, Jun 13 1998, 22:38:15) [GCC 2.7.2] on- sunos5
Copyright 1991-1995 Stichting Mathematisch Centrum, Amsterdam
>>> import MySQL;
>>> db = MySQL,con.nect();
>>> db.selectdb('db_test-);
>>> result - db.query("INSERT INTO test(test_id,test_val) VALUES(4,
'Bing!')");
>>> print result.affectedrows();
1
>>> result = db.query("SELECT * FROM test");
>>> print result. numrows();
3
>>> print result.fields();
[['test_id', 'test', 'long', 11, 'notnull'], ['test_val', 'test', 'string',
100, "]]
>>> print result, fetchrows(-l);
[[1, 'This is a test.'], [2, 'This is a test.'], [4. 'Bing!']]
>>>
В дополнение к результирующему набору запроса можно с помощью описателя команды получить число строк, затронутых операциями обновления, вставки или удаления. В примере 11-2 мы получили количество строк, возвращенных запросом, и подробные сведения о колонках, представленных в результирующем наборе.
Из новых методов, появившихся в примере 11-2, только fetchrows() не является самоочевидным. Этот метод получает очередную группу строк в количестве, определяемом переданным ему параметром. Иными словами, при вызове result. fetchrows(2) возвращается список, состоящий из очередных двух строк. Метод возвращает список, состоящий из всех строк, если ему передан параметр, меньший 0 — как в данном примере. Сочетая этот метод с обращением к seek(), можно перемещаться по результирующему набору. Метод seek() принимает целочисленный параметр, указывающий на строку, с которой вы хотите работать, при этом 0 указывает на первую строку.
Метаданные базы данных
Хотя только MySQL API поддерживает динамическое управление результирующим набором (по крайней мере, на момент данной публикации), оба API поддерживают метаданные базы данных с помощью почти идентичных наборов методов. Метаданные базы данных представляют собой информацию о соединении с базой данных. В примере 11-3 приведена сессия Python, заставляющая соединения с MySQL и mSQL рассказать о себе.
Пример 11-3. Данные
[7:56pm] athens> python
Python 1.5.1 (#1, Jun 13 1998, 22:38:15) [GCC 2.7.2] on sunos5
Copyright 1991-1995 Stichting Mathematisch Centrum, Amsterdam
>>> import mSQL, MySQL;
>>> msql = mSQL.connect();
>>> mysql = MySQL.connect();
>>> print msql.listdbs();
['db_test', 'db_web']
>>> print mysql.listdbs();
[['dbjest'], ['mysql'], ['test']]
>>> msql.selectdb('db_test');
>>> mysql.selectdb('db_test');
>>> print msql. listtables();
['test', 'hosts']
>>> print mysql.listtables();
[['test']]
>>> print msql.serverinfo;
2.0.1
>>> print mysql.serverinfo();
3.21.17a-beta-log
>>> print mysql.clientinfo();
MySQL-Python-1.1
>>> print msql.hostname;
None
>>> print mysql.hostinfo();
Localhost via UNIX socket
>>> print mysql.stat();
Uptime: 4868410 Running threads: 1 Questions: 174 Reloads: 4 Open tables: 4
>>> print mysql.listprocesses();
None
>>>
В этом примере долгая серия обращений к методам обеспечивает вывод расширенной информации о соединениях с базами данных. В ряде случаев mSQL предоставляет эту информацию через неизменяемые атрибуты, а не методы. MySQL API предоставляет значительно больше сведений, чем mSQL. Обратитесь к справочному разделу части III «Справочник» за полным описанием этих методов и атрибутов.
Если вы пишете много программ
Python
Если вы пишете много программ на Perl, но не знакомы с Python, вам определенно следует познакомиться с ним. Python является объектно-ориентированным языком сценариев, сочетающим мощь таких языков, как Perl и Tсl, с понятным синтаксисом, что позволяет создавать приложения, которые легко поддерживать и развивать. Отличное введение в программирование на Python дается в книге Марка Лутца (Mark Lutz) и Дэвида Эшера (David Asher) «Learning Python», изданной O'Reilly & Associates, Inc. В данной главе предполагается наличие у читателя знакомства с основами языка Python, включая умение добавлять новые модули к начальной инсталляции Python.
Поддержка баз данных MySQL и mSQL со стороны Python, которая является предметом данной главы, осуществляется посредством двух модулей Python. В момент публикации данной книги модуль для mSQL был доступен на http://www.python.org, а для MySQL - на http://www.mysql.com. Хотя есть несколько других модулей, обеспечивающих приложениям Python доступ к MySQL и mSQL, они, как и эти два, являются, в основном, вариациями на тему С API для MySQL и mSQL. Для доступа к выбранной вами базе данных и выполнения примеров этой главы необходимо установить один или оба этих модуля.
Оба API практически одинаковы, поэтому мы будем рассказывать сразу об обоих, оговаривая.места, где между ними есть различия.
Основы подключения к базам данных
API для Python являются, вероятно, самыми простыми API для работы с базами данных из всех, встречающихся в этой книге. Как и для других API, начать нужно с подключения к базам данных — установления соединения. Поскольку Python имеет интерактивный интерфейс, продемонстрировать соединение проще всего с помощью интерпретатора командной строки. Ниже показаны две сессии Python, демонстрирующие простое соединение с базами данных MySQL и mSQL соответственно. В первом примере производится соединение с базой данных MySQL:
[4:30pm] athens> python
Python 1.5.1 (#1, Jun 13 1998, 22:38:15) [GCC 2.7.2] on sunos5
Copyright 1991-1995 Stichting Mathematisch Centrum, Amsterdam
>>> import MySQL;
>>> db = MySQL.connect( 'athens. imaginary.com');
>>> db.selectdb('db_test');
>>> result = db.do('select test_val from test where test_id = 1');
>>> print result;
[['This is a MySQL test.']]
>>>
Код для mSQL, делающий то же самое, выглядит почти идентично:
[4:30pm] athens> python
Python 1.5.1 (#1, Jun 13 1998, 22:38:15) [GCC 2.7.2] on sunos5
Copyright 1991-1995 Stichting Mathematisch Centrum, Amsterdam
>>> import mSQL;
>>> db = mSQL.connect('athens. imaginary.com');
>>> db.selectdb('db_test');
>>> result = db.query('select test_val from test where test_id = 1');
>>> print result;
[('This is a mSQL test.',)]
>>>
В обоих случаях прежде всего нужно импортировать соответствующий модуль Python. He следует использовать синтаксис mSQL import *, так как он засорит пространство имен вашего приложения. Вместо этого в каждом модуле следует получить экземпляр описателя базы данных с помощью метода connect() и использовать этот описатель для доступа к базе данных.
Вызов connect() в обоих API схож, но не одинаков. В приведенном примере подключения к MySQL мы подключаемся к базе данных, для которой разрешен глобальный доступ. Поскольку в этом случае не требуется указания имени пользователя или пароля, вызов connect() для сессии MySQL выглядит так же, как для сессии mSQL. Однако вы можете задать имя пользователя и пароль, если того требует ваша база данных MySQL. Например, db = MySQL.connect( 'athens. imaginary.com', 'myuid', 'password'); подключит вас к серверу MySQL на athens.imagi-nary.com в качестве «myuid» с паролем «password». Тот и другой API не требуют имени узла при локальном подключении. В этом случае они достаточно сообразительны и для более быстрого соединения используют сокет домена Unix (на Unix-системах).
Процесс соединения в С API является двухэтапным и требует сначала соединиться с сервером, а затем выбрать базу данных, которую вы хотите использовать. Для API Python требуются те же шаги. Как для MySQL, так и для mSQL метод API для выбора базы данных практически одинаков: selectdb() . В большинстве случаев вы передаете этому методу единственный параметр - имя базы данных. MySQL поддерживает необязательный второй параметр, позволяющий потребовать, чтобы результирующий набор оставался на сервере, пока не будет запрошена каждая его строка. Этот вариант требуется только тогда, когда вы знаете, что память клиента ограниченна, или извлекаете очень большой результирующий набор.
Запросы
Эти два API слегка различаются в том способе, каким посылаются команды базе данных и обрабатываются возвращаемые результаты. API для mSQL очень прост и не имеет поддержки курсоров. Напротив, API для MySQL поддерживает простой mSQL API, а также более сложный набор методов API, которые более точно отражают С API и обеспечивают поддержку курсоров. При программировании на Python поддержка курсоров имеет сомнительную ценность, поскольку ни одна из этих баз данных не поддерживает редактирование по месту, а упрощенный API, показанный в интерактивных сессиях, позволяет перемещаться вперед и назад по результирующему набору с такой же легкостью, как и с помощью курсора. Однако далее в этой главе мы найдем применение для курсора, поскольку метод API, обеспечивающий поддержку курсора, обеспечивает также поддержку динамического доступа к базе данных.
mSQL API и простая форма MySQL API позволяют приложению запрашивать базу данных и выводить результаты в виде списка. К несчастью, эти API имеют тривиальное, но неприятное различие в том, каким образом это делается. Во-первых, для mSQL метод запроса называется query(), а для MySQL он называется do(). Каждый из методов воспринимает в качестве аргумента любую строку SQL. Если команда порождает результирующий набор, он возвращается в виде списка: списка кортежей для mSQL и списка списков для MySQL.
В большинстве случаев различие в типе возвращаемых значений несущественно: кортежи не могут изменяться. Код в большинстве случаев одинаков. Тем не менее следует помнить, что строки MySQL являются списками, а строки mSQL - кортежами, на случай, если вы столкнетесь с ситуацией, где это различие существенно. В примере 11-1 приводится простая Python-программа, обращающаяся к базам данных MySQL и mSQL и выводящая результаты.
Пример 11-1. Обработка запросов в Python дд,я mSQL и MySQL
#!\/usr/local/bin/python
# Импорт модулей import Msql, MySQL;
# Инициализация значений database и query
database = 'db_test';
query = 'SELECT test_id, test_val FROM test';
# Соединение с серверами msql = mSQL.connect();
mysql = MySQL.connect();
# Выбор тестовых баз данных msql.selectdb(database);
mysql.selectdb(database);
# Выполнение запроса
m_result = msql.query(query);
my_result = mysql.do(query);
#Обработка результатов для mSQL
for row in m_result:
# Здесь row является кортежем
print "mSQL- test_id: ",row[0]," test_val: ",row[1];
# Обработка результатов для MySQL
for row in my_result:
ft Здесь row является списком
print "MySQL- test_id: ",row[0]," | test_val: ",row[1];
# Закрыть соединение (только mSQL)
msql.close();
Для обеих баз данных, MySQL и mSQL, приложение просматривает в цикле каждую строку результирующего набора и выводит ее данные. В mSQL первый элемент кортежа представляет первую колонку запроса, а второй элемент - вторую колонку. Аналогично, первый элемент в списке MySQL представляет первую колонку запроса, а второй элемент - вторую колонку.
Обновление
Обновление, вставка и удаление в базе данных производится с помощью того же метода API, что и запросы, - просто не требуется обрабатывать результирующий набор. Иными словами, вызовите query() или do(), и больше ничего не требуется. В MySQL есть дополнительная возможность возврата значения AUTO_INCREMENT , если в затронутой таблице есть поле с атрибутом AUTO_INCREMENT .
Альтернативные методы создания динамического содержания Web
Впервые то, что сейчас мы называем Dynamic HTML, появилось в Web в виде Server Side Includes (SSI) - «включений на стороне сервера». В основе SSI лежит та мысль, что есть ряд часто встречающихся величин, таких как текущие дата и время, которые включать в HTML-страницу полезно, но непрактично, поскольку они очень часто изменяются. SSI дает способ, которым HTML-страница может потребовать от сервера включить в нее значения таких параметров перед тем, как послать страницу конечному пользователю. Благодаря этому параметр всегда имеет текущее значение, а создателю страницы нет необходимости непрерывно ее обновлять. Типичная директива SSI на странице HTML выглядит так:
<!--#echo var="DATE_LOCAL" -->
Проблема SSI в том, что набор данных, который сервер может легко предоставить, очень ограничен. Сверх даты, времени и способности включать другие файлы остается не много возможностей без того, чтобы сам веб-сервер не начал серьезно разрастаться.
Вскоре стало ясно, что если сам веб-сервер не обеспечивает динамического HTML, он может появиться только из двух источников. Либо клиент, то есть веб-броузер, интерпретирует команды, либо какая-нибудь другая программа на сервере осуществляет предварительную обработку команд, выдавая конечному пользователю чистый HTML.
Первый путь привел к JavaScript и аналогичным технологиям. В JavaScript, как и в SSI, команды встраиваются в HTML. В отличие от SSI, сервер не трогает команды JavaScript, их обрабатывает броузер. Такой способ предоставляет значительно лучшее взаимодействие с пользователем. Например, JavaScript позволяет определить действия, которые должны производиться при перемещении пользователем мыши над различными участками экрана. Благодаря этому удается создать ощущение непосредственности и интерактивности, недостижимые другими средствами. Вот пример типичного кода JavaScript:
<SCRIPT>
<! onMouseOver("станцевать джигу"); -->
</script>
Трудность, вызываемая решениями, работающими только на стороне клиента, такими как JavaScript, состоит в том, что, как только клиент заканчивает загрузку страницы, связь с сервером теряется. Очень часто на сервере располагаются ресурсы, например, серверы баз данных, с которыми хотелось бы взаимодействовать. Однако сценарии, выполняемые на стороне клиента, обычно делают невозможной или неэффективной связь с сервером или другой удаленной машиной после того, как страница загружена. Такого рода функциональность больше соответствует решениям на стороне сервера.
При наличии интерпретатора на стороне сервера документ HTML просматривается перед тем, как быть отосланным конечному пользователю. Какая-либо программа, обычно программа CGI, выявляет и выполняет программный код, встроенный в HTML. Преимущество такой системы в том, что используется мощь CGI-программы и значительная доля сложности остается скрытой.
Предположим, что есть морская организация с базой данных об акулах. База данных содержит важную статистику по различным видам акул, а также имена файлов с изображениями этих тварей. Для создания веб-интерфейса к этой базе данных идеально применим HTML с интерпретацией на сервере. Все выходные страницы с информацией о выбранном виде акулы имеют идентичный формат. В местах, где требуются динамические данные из базы, можно вставить команды, которые будут выполнены до того, как пользователь увидит страницу. Можно даже генерировать динамические теги <IMG> для показа желаемых изображений. Позднее в этой главе мы покажем, как можно реализовать этот пример с помощью различных интерпретаторов на сервере.
и другие средства поддержки HTML,
PHP и другие средства поддержки HTML, управляемого базами данных
Есть несколько простых в использовании программных расширений HTML, обеспечивающих поддержку доступа к серверам баз данных MySQL и mSQL с веб-страниц. В этой главе мы начнем с W3-mSQL -средства для mSQL. Затем покажем менее связанный с конкретной базой данных подход с помощью РНР и двух небольших расширений Perl. Имеющийся в W3-mSQL язык сценариев Lite позволяет встраивать в HTML-файлы целые программы. CGI-программа выполняет сценарий и посылает клиенту результат в виде динамически создаваемого документа HTML.
Поскольку W3-mSQL и другие расширения, рассматриваемые в данной главе, используют собственные языки сценариев и скрывают всякие признаки использования CGI, в этой главе не требуется знания предшествующего материала данного раздела. Однако при чтении главы может оказаться полезным понимание того, как работает CGI, a также наличие некоторого предшествующего опыта программирования (Lite сходен как с С, так и с Perl).
РНР
По самой своей природе W3-mSQL узко специализирована для использования с СУБД mSQL. Если вы используете MySQL или же W3-mSQL не покрывает всех ваших потребностей, то есть другие препроцессоры HTML, предлагающие поддержку баз данных.
РНР, что означает «PHP: Hypertext Preprocessor» (препроцессор гипертекста), является приложением, очень близким по духу W3-mSQL. Оба приложения являются CGI-программами, интерпретирующими HTML перед отправкой броузеру окончательной страницы. Оба имеют встроенный язык сценариев. Более того, в обе программы тесно интегрированы возможности работы с базами данных. Однако РНР идет дальше W3-mSQL, предлагая совместимость с несколькими серверами баз данных, включая MySQL и mSQL.
Язык сценариев РНР более богат и может использоваться в большем числе приложений, чем W3-mSQL. Короче, предпочтительнее использовать РНР, если только вы не привязаны к использованию mSQL в качестве сервера баз данных. В последнем случае более удобной для вас будет некоторая оптимизация, имеющаяся в W3-mSQL.
С использованием РНР пример с базой данных по акулам может выглядеть так:
<НТМL>
<НЕАD><TITLЕ>Результат поиска акул </title></head>
<BODY>
<Н1> Вот акулы, удовлетворяющие условиям поиска...</ht>
<Р> <?
/* Начинаем построение запроса. В результате типичный запрос
* может выглядеть так:
* SELECT * FROM SHARK WHERE SPECIES='Isurus Paucus' AND AGE=2 */
$query = "select * from sharks where ";
if ($species || $age || Slocation) {
$query += " where "; }
if ($species) { $query += "species = '$species'";
}
if ($age) {
if ($species) { $query += " and "; }
$query += "age = Sage";
}
if ($location) {
if ($species || $age) { Squery += " and "; } $query += "location = '$location'";
}
$result = msql("sharks",Squery);
if (result == -1) {
echo("Error : $phperrmsg\n");
exit(1); }
Snumresults = msql_numrows($result);
>
<UL>
<!
if (! $numresults ); >
<Н2> Результатов не найдено </h2>
<!
else {
while-($i < $numresults) {
$id[$i] = msql_result($result,$i,"id");
$species[$i] = msql_result($result,$i,"species");
$age[$i] = msql_result($result,$i,"age");
$loc[$i] = msql_result($result,$i,"location");
echo("<LI>");
printf("<IMG SRC=\"graphics/shark%s,gif\" ALIGN=LEFT>", $id[$i]); echo("<В>Вид:</b> $species[$i]<br>");
if ($age[$i] == 1) { $age = "Молодые"; }
else if ($age[$i] == 2) { $age = "Взрослые"; }
else if {$age[$i] == 3) { $age = "Старые"; }
echo("<B>Age:</b> $age<br>");
echo("<B>Paйoн</b> $location[$i]<br>");
}
}
}
</ul>
<A HREF="search.html">Hoый поиск </а>
</body></html>
Встроенный Perl
Несколько модулей Perl и соответствующих программ позволяют встраивать код Perl в документ HTML. Перед отправкой окончательной страницы HTML броузеру этот код выполняется CGI-программой.
Наиболее очевидное преимущество таких решений перед W3-mSQL и РНР заключается в том, что в качестве языка сценариев в HTML-файле используется обычный Perl. Будучи простыми в изучении и схожими по стилю с С и Perl, языки сценариев Lite и РНР все же являются уникальными патентованными языками, используемыми лишь с единственной целью. Напротив, Perl практически вездесущ. Это стандартный язык программирования, отлаживавшийся на протяжении многих лет и обладающий развитыми возможностями в отношении безопасности. В пользу такого типа решений есть убедительные аргументы.
ePerl
Первым приложением, позволившим встраивать код Perl в текст ASCII и, в частности, в документ HTML, был ePerl. Сама программа ePerl написана на С и предназначена для использования в качестве интерпретатора Perl общего назначения для документов ASCII. Она прекрасно работает с HTML, но не имеет специфических для HTML или веб-возможностей, предоставляемых некоторыми другими пакетами.
EmbPerl
Программа EmbPerl создана позднее, чем ePerl, и более ориентирована на HTML и Web. Она позволяет использовать дополнительные «метакоманды» - теги в стиле HTML, обрабатываемые EmbPerl, - которые вводят в сам HTML возможности ветвления и другие элементы программирования .
В качестве примера встраивания кода Perl в файл HTML рассмотрим форму для вывода данных из базы данных по акулам, приводившуюся выше. Мы будем использовать в нашем примере EmbPerl, но поскольку используется стандартный Perl, код практически одинаков для различных средств встраивания Perl.
<HTML>
<НЕАD><ТIТLЕ>Результаты поиска акул</title></head>
<BODY>
<Н1> Вот акулы, удовлетворяющие условиям поиска...</h1>
<р>
[-
use Msql;
use CGI qw(:standard);
$dbh = Msql->connect; $dbh->selectdb("sharks");
%age = ( '0' => 'Молодые',
'1' => 'Взрослые',
'2' => 'Старые'
);
# Начинаем построение запроса. В результате типичный запрос
# может выглядеть так:
# SELECT * FROM SHARK WHERE SPECIES='Isurus Paucus' AND AGE=2
$query = "select * from sharks where ";
if ( Sspecies or Sage or $location) {
$query .= " where ";
$query .= join(" and ", param); }
Sresult = $dbh->query($query);
if (result == -1) {
echo("Error : " . Msql->errmsg . "\n");
exlt(l);
}
Snumresults = $result->numrows;
-]
<UL>
[$if (! Snumresults ) $]
<Н2>Результатов не найдено </h2> [SelseS]
[Swhile (%shark = $Msql->fetchhash($result)) $]
<LI>
<IMG SRC="graphics/shark[+$shark{'id'}+].gif" ALIGN=LEFT>
<В>Вид:</b> [+$shark{'species'}+]<br>
<В>Возраст:</b> [+$age{$shark{'age'}}+]<br>
<В>Район </b> [+$shark{'location'}+]<br>
[;endwhile$] [;endif] </ul>
<A HREF="search.html">Hoвый поиск </а>
</body></html>
W3-mSQL
W3-mSQL является, в сущности, одной программой CGI, называющейся w3-msql. Программа фильтрует страницы HTML со встроенными командами W3-mSQL и посылает клиенту очищенный результирующий HTML. Команды W3-mSQL пишутся на специальном языке программирования, называемом Lite. Lite во многом схож с Perl и С, но разработан специально для взаимодействия с базами данных mSQL. Краткий справочник по функциям Lite есть в конце главы 18 «Справочник по PHP Lite». Для осуществления этого к URL для w3-msql добавляется путь к HTML-файлу, с расширениями W3-mSQL, например, http://www.me.com/cgi-bin/w3-msql/~me/mypage.html.
Содержимое HTML-файла внутри тега <! > интерпретируется как команды Lite. Например, эквивалент программы "Hello world!" на Lite выглядит так:
<HTML><HEAD><TITLE>Hello world!</title></head>
<BODY>
<!
echo("Hello world!");
>
</body></html>
Все, что не находится внутри тегов <! >, остается чистым HTML.
mSQL автоматически устанавливает программу w3-msql, и вам остается только поместить ее в свой каталог cgi-bin.
W3-Auth
W3-Auth является механизмом, обеспечивающим защиту страниц, управляемых W3-mSQL. Он включается вместе с W3-mSQL и устанавливается автоматически с mSQL. С помощью W3-Auth можно создать иерархию пользователей и групп, которым разрешено использовать различные страницы с расширениями W3-mSQL.
W3-Auth использует три различных уровня доступа: пользователь, группа и область. Пользователь отдельное имя, обычно относящееся к отдельному лицу, примерно как имя пользователя в Unix. Груп па является собранием пользователей. Область является разделом веб-сайта, который вы хотите защитить.
Такая схема особенно полезна для сайтов со многими виртуальными узлами на одном веб-сервере. Допустим, например, что на вашем компьютере расположены виртуальные серверы с именами serverl, ser-ver2 и server3. Каждое из этих различных имен администрируется различными группами людей. Вы можете создать три разные области, охватывающие эти три сайта, и тогда члены каждой группы будут в состоянии управлять доступом к своей странице с расширениями W3-mSQL, но не смогут вмешаться в управление другими сайтами.
Установка
Обе программы, W3-mSQL и W3-Auth, компилируются и устанавливаются автоматически, вместе с дистрибутивом mSQL. После установки они находятся в MSQL_HOME/bin, где MSOL_HOME есть местонахождение файлов mSQL - по умолчанию /usr/local/Hughes. Исполняемые файлы w3-msql и w3-auth нужно скопировать в каталог cgi-bin вашего сервера или эквивалентный ему.
После установки W3-Auth предполагает, что она сама и программа w3-msql находятся в каталоге cgi-bin вашего сайта. Если вы хотите поместить эти программы в другой каталог, нужно вручную изменить исходный код перед установкой mSQL. С помощью Perl это можно сделать следующим образом. Находясь в каталоге src/w3-msql дистрибутива mSQL, введите: perl -pi -e 's/cgi-bin/yourcgidirectory/g' *.c. Другой возможностью сделать то же самое является использование такого сценария:
#!/bin/sh
# Запустите это из каталога src/w3-msql своего дистрибутива с исходным кодом mSQL.
for file in 'Is *.c'; do
sed -e "s/cgi-bin/$1/" $file > $file.tmp
mv $file.tmp $file
done
Скопируйте этот сценарий в ваш каталог src/w3-msql и введите следующую команду:
./scriptname yourcgidirectory
Здесь scriptname является именем сценария, a yourcgidirectory - именем каталога, который будет содержать исполняемые файлы w3-msql и w3-auth.
W3-Auth в настоящее время не совместим с распространяемой версией веб-сервера Apache из-за одной небольшой особенности системы безопасности Apache. Apache не позволяет программам CGI иметь доступ к данным авторизации. Без этой возможности ни одна CGI-программа, включая W3-Auth, не может выводить пользователю стандартное окно для ввода имени пользователя/пароля и получать из него результаты. Ввиду важности Apache для сообщества пользователей mSQL, был быстро выпущен патч, позволяющий W3-Auth работать вместе с Apache. После его установки необходимо перекомпилировать Apache. Заметьте, что установка данного патча позволяет любым CGI-програм-мам получать имя пользователя и пароль у посетителей сайта. Если вы доверяете тем, кто имеет доступ к CGI-программам на вашей машине, то подобный метод относительно безопасен.
Два API
Используете ли вы С или C++, С API для MySQL и mSQL являются шлюзами к базе данных. Однако их применение может очень различаться в зависимости от того, используете ли вы С или объектно-ориентированные возможности C++. К программированию баз данных на С нужно подходить в последовательном стиле, когда вы пошагово просматриваете свое приложение, чтобы определить, где производятся обращения к базе данных, а где необходимо произвести освобождение ресурсов. Напротив, объектно-ориентированный C++ требует объектно-ориентированного интерфейса к выбранному вами API. Тогда объекты этого API могут взять на себя ответственность за управление ресурсами базы данных.
В таблице 13-1 сопоставлены вызовы функций каждого API. Детали использования этих функций мы рассмотрим позднее в этой главе. Сейчас вы можете лишь бегло сравнить оба API и отметить, какие возможности они предоставляют. Разумеется, в справочном разделе перечислены все эти методы с подробным описанием прототипов, возвращаемых значений и комментариями.
Таблица 13-1. С API для MySQL и mSQL
|
MySQL |
mSQL | ||
|
mysql_affected_rows() |
CM. msqlQuery() | ||
|
mysql_close() |
msqlClose() | ||
|
mysql_connect() |
msqlConnect() | ||
|
myql_create_db() |
| ||
|
mysql_data_seek() |
msqlDataSeek() | ||
|
mysql_drop_db() |
| ||
|
mysql_eof() |
| ||
|
mysql_error() |
| ||
|
mysql_fetch_field() |
msqlFetchField() | ||
|
mysql fetch lengths() |
| ||
|
mysql_fetch_row() |
msqlFetchRow() | ||
|
mysql_field_count() |
| ||
|
mysql_field_seek() |
msqlFieldSeek() | ||
|
mysql_free_result() |
msqlFreeResult() | ||
|
mysql_get_client_info() |
| ||
|
mysql get host_info() |
| ||
|
mysql_get_proto_info() |
| ||
|
mysql_get_server_info() |
| ||
|
mysql_init() |
| ||
|
mysql_insert_id() |
| ||
|
mysql_list_dbs( ) |
msqlListDBs() | ||
|
mysql_list_fields() |
msqlListFields() | ||
|
|
msqlListIndex() | ||
|
mysql_list_processes() |
| ||
|
mysql_list_tables() |
msqlListTables() | ||
|
mysql_num_fields() |
msqlNumFields() | ||
|
mysql_num_rows() |
msqlNumRows() | ||
|
mysql_query() |
msqlQuery() | ||
mysql_real_query() |
|
mysql_reload() |
|
mysql_select_db() |
msqlSelectDB() |
mysql_shutdown() |
|
mysql_stat() |
|
mysql_store_result() |
msqiStoreResult() |
mysql_use_result() |
|
Осуществлять соединение.
Выбирать БД.
Посылать запрос.
Получать строку.
Получать поле.
Закрываться.
В примере 13-1 показана простая команда select, извлекающая данные из базы данных MySQL с помощью MySQL С API.
Пример 13-1. Простая программа, извлекающая все данные из тестовой базы и отображающая их
#include <sys/time. h>
#include <stdio.h>
#include <mysql.h>
int main(char **args) {
MYSQL_RES 'result;
MYSQL_ROW row;
MYSQL 'connection, mysql;
int state;
/* соединиться с базой данных mySQL на athens.imaginary.com */
mysql_init(&mysql);
connection = mysql_real_connect(&mysql,
"alMens.imaginary.com",
0, 0,
"db_test", 0, 0);
/* проверить ошибки соединения */
if( connection == NULL ) {
/* вывести сообщение об ошибке */
printf(mysql_error(&mysql));
return 1;
}
state = mysql_query(connection,
"SELECT test_id, test_val FROM test");
if( state != 0 ) {
printf(mysql_error(connection));
return 1; }
/* прежде чем делать другие вызовы,
* необходимо вызвать mysql_store_result()
*/
result = mysql_store_result(connection);
printf("Строк: %d\n", mysql_num_rows(result));
/* обработать каждую строку результирующего набора */
while( ( row = mysql_fetch_row(result)) != NULL )
{
printf("id: %s, значение: %s\n", (row[0] ? row[0] : "NULL"), (row[1] ? row[1] : "NULL")); }
/* освободить ресурсы, использовавшиеся результирующим набором */
mysql_free_result(result); /* закрыть соединение */
mysql_close(connection);
printf("Koнец, работы.\n");
}
Назначение файлов mysql.h и stdio.h, включаемых директивой ftinclude, должно быть очевидно. Файл заголовков mysql.h содержит прототипы и переменные, необходимые для MySQL, a stdio.h содержит прототип для printf (). Файл заголовков sys/time.h приложением фактически не используется. Он нужен из-за mysql.h, так как файл для MySQL использует определения из sys/time.h, не включая их. Для компиляции программы с помощью компилятора GNU С используйте командную строку:
gcc -L/usr/local/mysql/lib -I/usr/local/mysql/include -о select
select.c\
-Imysql -Insl -Isocket
Разумеется, в этой строке вместо /usr/local/mysql нужно задать тот каталог, в который вы установили MySQL.
Функция main() выполняет те шаги, которые мы перечислили раньше: соединяется с сервером, выбирает базу данных, выдает запрос, обрабатывает его результаты и освобождает использованные ресурсы. По ходу главы мы подробно остановимся на каждом из этих этапов. Сейчас посмотрите на этот код, лишь для того чтобы почувствовать, как он работает. Кроме того, сравните этот пример с той же программой, написанной для mSQL, которая представлена в примере 13-2.*
Пример 13-2. Простое приложение выборки данных для mSQL
#include <sys/time.h>
#include <stdio.h>
#include <msql.h>
int main(char **args) {
int connection, state;
m_result *result;
m_row row;
/* соединиться с базой данных mSOL на athens.imaginary.com */
state = msqlConnect("athens.imaginary.com");
/* проверить ошибки соединения */
if( state == -1 )
{
/* вывести сообщение об ошибке, хранящееся в MsqlErrMsg */
printf(msqlErrMsg);
return 1;
}
else
{
/* описателем соединения является значение, возвращаемое msqlConnect() */
connection = state; }
/* выбрать используемую базу данных */
state = msqlSelectDB(connection, "db_test");
/* опять-таки, -1 указывает на ошибку */
if( state == -1 )
{
printf(msqlErrMsg);
/* закрыть соединение перед выходом */
msqlClose(connection);
return 1; }
state = msqlQuery(connection, "SELECT test_id, test_val FROM test");
if( state == -1 )
{
printf(msqlErrMsg);
return 1;
}
else
{
printf("Строк: %d\n", state);
}
/* прежде чем делать новый вызов Query(),
* необходимо вызвать msqlStoreResult()
*/
result = msqlStoreResult();
/* обработать каждую строку результирующего набора */
while( ( row = msqlFetchRow(result)) != NULL )
{
printf("id: %s, значение: %s\n",
(row[0] ? row[0] : "NULL"),
(row[1] ? row[1] : "NULL"));
}
/* освободить ресурсы, использовавшиеся результирующим набором */
msqlFreeResult(result); /* закрыть соединение */
msqlClose(connect ion);
printf("Конец работы.\n"); }
Эти программы почти идентичны. Кроме разных имен функций, есть лишь несколько заметных отличий. Сильнее всего бросается в глаза различие в соединении с базой данных, которое проявляется в двух отношениях:
В MySQL соединение осуществляется за один шаг, а в mSQL - за два.*
Для MySQL требуются имя пользователя и пароль, а для mSQL -нет.
Как указывалось ранее в этой книге, MySQL поддерживает сложную схему авторизации с именами пользователей и паролями. Напротив, в mSQL применяется простая система, использующая ID пользователя процесса, соединяющегося с базой данных. Более надежная схема MySQL гораздо привлекательнее в среде клиент/сервер, но также и значительно более сложна в администрировании. Для разработчиков приложений она означает необходимость передачи в вызове mysql_real_connect() имени пользователя и пароля при работе с MySQL помимо имени сервера, используемого в mSQL.
Первый аргумент API для установления соединения с MySQL может показаться необычным. По сути, это способ отслеживать все вызовы, иначе никак не связанные с соединением. Например, если вы пытаетесь установить соединение, и попытка неудачна, вам нужно получить сообщение о соответствующей ошибке. Однако функция MySQL
mysql_error() требует задания указателя на действующее соединение с базой данных MySQL. Такое соединение обеспечивается изначально созданным нулевым соединением. Однако у вас должна быть действующая ссылка на это значение в течение всего времени существования вашего приложения - вопрос большой важности в более структурированной среде, чем простое приложение вида «соединился, сделал запрос, закрылся». Примеры на C++ далее в этой главе подробнее рассматривают эту тему.
Два другие различия в API относятся к тому, как производятся обработка ошибок и подсчет числа записей в результирующем наборе. API mSQL создает глобальную переменную для хранения сообщений об ошибках. Из-за многопоточности MySQL такая глобальная переменная не смогла бы действовать в его API. Поэтому в нем используется функция mysql_error() для извлечения сообщений об ошибках, связанных с последней ошибкой, порожденной указанным соединением.
API для соединения и обработки ошибок - два пункта, в которых MySQL отличается от mSQL для обеспечения функциональности, отсутствующей в mSQL. Подсчет числа результирующих записей в mSQL делается иным способом для обеспечения лучшего интерфейса, нежели предоставляемый MySQL. А именно: при посылке SQL-запроса в msqlQuery() возвращается число задействованных строк (или -1 в случае ошибки). Таким образом, подсчет измененных строк при обновлении и строк в возвращаемом результирующем наборе при запросе используют одну и ту же парадигму. В MySQL же приходится использовать различные парадигмы. При запросе на получение данных нужно передать результирующий набор функции mysql_nuoi_rows() , чтобы получить число строк в результирующем наборе. При обновлении нужно вызвать другую функцию API, mysql_affected_rows() . В то время как msqlQuery() возвращает число строк, удовлетворивших предложению WHERE при обновлении, mysql_affected_rows() сообщает о числе фактически измененных строк. И наконец, в mSQL есть метод msqlNumRows() , обеспечивающий тот же интерфейс для подсчета результирующего набора, что и в MySQL, но в нем нет аналога для mysql_affected_rows() .
В этой книге мы рассматриваем
С и C++
В этой книге мы рассматриваем несколько разных языков программирования: Python, Java, Perl и С. Из этих языков больше всего трудностей вызывают C/C++. В других языках ваша задача состоит в формировании запроса SQL, передаче этого запроса посредством вызова функции и обработке результирующих данных. В С добавляется очень сложная проблема управления памятью.
Как MySQL, так и mSQL предоставляют С-библиотеки, позволяющие создавать приложения для работы с базами данных MySQL и mSQL. В действительности API MySQL ведет свое происхождение от mSQL, благодаря чему опыт программирования в одном API позволяет легко перейти к другому. Однако, как мы видели в первой части, MySQL значительно богаче функциями, чем mSQL. Естественно, эти дополнительные функции приводят к некоторым различиям между двумя API. В данной главе мы исследуем эти различия и разберем детали каждого API при создании объектно-ориентированного C++ API, который можно условно компилировать для работы с каждым из двух API.
Объектно-ориентированный доступ к базам данных на C++
С API прекрасно работают в процедурном программировании на С. Однако они не очень хорошо вписываются в объектно-ориентированную среду C++. Чтобы показать, как реально использовать в программе эти два API, в оставшейся части главы мы создадим с их помощью C++ API для объектно-ориентированного программирования баз данных.

Рис. 13-1. Библиотека объектно-ориенитрованного доступа к базе данных
Поскольку мы занимаемся освещением доступа к базам данных MySQL и mSQL, то сосредоточимся на специфичных для MySQL и mSQL темах и не будем пытаться создать совершенный общий C++ API. Работу с MySQL и mSQL описывают три главных понятия: соединение, результирующий набор и строки результирующего набора. Мы будем использовать эти понятия как ядро объектной модели, на которой будет основываться наша библиотека. Рис. 13-1 показывает эти объекты на UML-диаграмме.*
Соединение с базой данных
В любой среде доступ к базе данных начинается с соединения. Как вы видели в первых двух примерах, MySQL и mSQL по-разному представляют одно и то же понятие - соединение с базой данных. Создание нашей объектно-ориентированной библиотеки мы начнем с абстрагирования от этого понятия и создания объекта Connection . Объект Connection должен уметь устанавливать соединение с сервером, выбирать нужную базу данных, посылать запросы и возвращать результаты. Пример 13-3 показывает заголовочный файл, в котором объявлен интерфейс к объекту Connection.
UML - это новый Унифицированный язык моделирования, созданный Гради Бучем, Айваром Якобсоном и Джеймсом Рамбо (Grady Booch, Ivar Jacobson, James Rumbaugh) в качестве нового стандарта для документирования объектно-ориентированного проектирования и анализа.
Пример 13-3. Заголовок класса Connection
#ifndef l_connection_h
#define l_connection_h
#include <sys/time.h>
#if defined(HAS_MSQL)
#include <msql. h>
#lelif defined(HAS_MYSQL)
#include <mysql.h>
#endif
#include "result.h"
class Connection { private:
int affected_rows;
#if defined(HAS_MSQL)
int connection;
#elif defined(HAS_MYSQL)
MYSQL mysql;
MYSQL 'connection; tfelse
#error База данных не определена,
#endif
public:
Connection(char *, char *);
Connection(char *, char *, char *, char *);
~Connection();
void Close();
void Connect(char 'host, char *db, char *uid, char *pw);
int GetAffectedRows();
char. *GetError();
int IsConnected();
Result *Query(char *);
};
#endif // l_connection_h
Методы, которые предоставляет класс Connection, одинаковы вне зависимости от используемой СУБД. Однако спрятанными в глубине класса окажутся закрытые члены, специфичные для той библиотеки, с которой он будет компилироваться. При установлении соединения единственными различными данными-членами станут те, которые представляют соединение с базой данных. Как отмечалось, mSQL для представления соединения использует величину типа int, a MySQL использует указатель на MYSQL и дополнительную величину типа MYSQL для установления соединения.
Установление соединения с базой данных
Всем приложениям, которые мы будем создавать с использованием этого API, для соединения с базой данных потребуется только создать новый экземпляр класса Connection с помощью одного из его конструкторов. Аналогично, приложение может отсоединиться, уничтожив экземпляр Connection . Оно может даже повторно использовать экземпляр Connection с помощью прямых обращений к методам Close() и Соnnect(). Пример 13-4 показывает реализацию конструкторов и метода Connect().
Пример 13-4. Соединение с MySQL и mSQL в классе Connection
#include "connection.h"
Connection::Connection(char *host, char *db) {
#if defined(HAS_MSQL)
connection = -1;
#elif defined(HASJIYSQL)
connection = (MYSQL *)NULL;
#else
#error Het соединения с базой данных,
#endif
Connect(host, db, (char *)NULL, (char *)NULL); }
Connection::Connection(char 'host, char *db, char *uid, char *pw) {
#if defined(HASJISQL)
connection = -1;
#elif defined(HASJIYSQL)
connection = (MYSQL *)NULL;
#else
#error Нет соединения с базой данных,
#endif
Connect(host, db, uid, pw);
}
void Connection: :Connect(char'host, char *db, char *uid, char *pw)
{
int state;
if( IsConnected() )
{
throw "Соединение уже установлено.";
}
#if defined(HAS_MSQL)
connection = msqlConnect(host);
state = msqlSelectDB(connection, db);
#elif defined (HAS.MYSQL) mysql_init(&mysql);
connection = mysql_real_connect(&mysql, host,
uid, pw,
db, 0, 0); #else
#error Нет соединения с базой данных.
#endif
if( !IsConnected() )
{
throw GetError();
}
if( state < 0 )
{
throw GetError();
}
}
Оба конструктора разработаны с учетом различия параметров, требуемых для соединений MySQL и mSQL. Тем не менее эти API должны разрешать обоим конструкторам работать с каждой из баз данных. Это достигается игнорированием ID пользователя и пароля при вызове конструктора с четырьмя аргументами. Аналогично при вызове конструктора с двумя аргументами, серверу MySQL в качестве значений ID пользователя и пароля передаются значения null. Фактическое соединение с базой данных происходит в методе Connect ().
Метод Connect() инкапсулирует все шаги, необходимые для соединения. Для MySQL он вызывает метод mysql_real_connect() . Для mSQL жe сначала вызывается метод msqlConnect(), а затем msqlSelectDB() . При неудаче на любом из этапов Connect() возбуждает исключительную ситуацию.
Отсоединение от базы данных
Другой логической функцией класса Connection является отсоединение от базы данных и освобождение скрытых от приложения ресурсов. Эту функцию осуществляет метод Close (). В примере 13-5 показано, как происходит отсоединение от MySQL и mSQL.
Пример 13-5. Освобождение ресурсов базы данных
Connection::"Connection() {
if( IsConnected() ) {
Close();
} }
void Connection::Close() {
if( !IsConnected() )
{
return;
}
#if defined(HAS_MSQL)
msqlClose(connection);
connection = -1;
#elif defined(HAS_MYSQL)
mysql_close(connection);
connection = (MYSQL *)NULL;
#else
#error Нет соединения с базой данных, tfendif }
Методы mysql_close() и msqlClose() освобождают ресурсы, используемые соединениями с MySQL и mSQL соответственно.
Выполнение обращений к базе данных
В промежутке между открытием соединения и закрытием базе данных обычно посылаются команды. Класс Connection делает это с помощью метода Query(), принимающего команду SQL в качестве аргумента. Если команда является запросом, она возвращает экземпляр класса Result из объектной модели, представленной на рио. 13-1. Если же команда обновляет данные, то метод возвращает NULL и устанавливает значение affected_rows равным количеству строк, в которых произведены изменения. В примере 13-6 показано, как класс Connection обрабатывает запросы к базам данных MySQL и mSQL.
Пример 13-6. Обработка запроса к базе данных
Result "Connection::Query(char *sql) { T_RESULT *res; int state;
// Если нет соединения, делать нечего
if( !lsConnected(-) ) { throw "Соединения нет.";
}
// Выполнить запрос
#if defined(HAS_MSQL)
state = msqlQuery(connection, sql);
#elif defined(HAS_MYSQL)
state = mysql_query(connection, sql);
#else
#error Нет соединения с базой данных,
#endif
// Если произошла ошибка
if( state < 0 ) { throw GetError();
}
// Забрать результаты, если таковые имеются
#if defined(HAS_MSQL)
res = msqlStoreResult();
#elif defined(HAS_MYSQL)
res = mysql_store_result(connection);
#else
#error Нет соединения с базой данных,
#endif
// Если результат null, это было обновление или произошла ошибка
// Примечание: mSQL не порождает ошибки в msqlStoreResult()
if( res == (T_RESULT *)NULL ) {
// Установить значение affected_rows равным возвращенному msqlQuery()
#if defined(HAS_MSQL)
affected_rows = state;
#elif defined(HAS_MYSQL)
// field_count != 0 означает, что произошла ошибка
int field_count = mysql_num_fields(connection);
if( field_count != 0 )
{
throw GetError();
}
else
{
// Запомнить affected_rows
affected_rows = mysql_affected_rows(connection); }
#else
#error Нет соединения с базой данных,
#endif
//Возвратить NULL в случае обновления
return (Result *)NULL; }
// Для запроса возвратить экземпляр Result
return new Result(res); }
В начале обращения к базе данных делается вызов метода mysql_query() или msqlQuery() с передачей ему команды SQL, которую нужно выполнить. В случае ошибки оба API возвращают отличное от нуля значение. На следующем этапе вызываются mysql_store_result() или msqlStoreResult() , чтобы проверить, получены ли результаты, и сделать эти результаты доступными приложению. В этом месте две СУБД несколько отличаются в деталях обработки.
В mSQL API метод msqlStoreResult() не генерирует ошибки. Эту функцию приложение использует для того, чтобы поместить полученный результирующий набор в хранилище, управлять которым будет приложение, а не mSQL API. Иными словами, при вызове msqlQuery() результаты запоминаются во временной области памяти, управляемой API. Последующие вызовы msqlQuery() затирают эту область памяти. Чтобы сохранить результат в области памяти вашего приложения, нужно вызвать msqlStoreResult() .
Поскольку метод msqlStoreResult() не генерирует ошибку, при его вызове нужно рассматривать две возможности. Если обращение к базе данных было запросом, создавшим результирующий набор, то msqlStoreResult() возвращает указатель на структуру m_result, с которой может работать ваше приложение. При всех других типах обращения (обновление, вставка, удаление или создание) msqlStoreResult() возвращает NULL. Узнать количество строк, обработанных неизвлекающим данные запросом, можно из значения, возвращенного исходным вызовом msqlQuery() .
Подобно msqlStoreResult() , метод mysql_store_result() используется для запоминания данных, возвращенных запросом, в области памяти приложения, но, в отличие от версии для mSQL, необходимо создать для mysql_store_result() некий обработчик ошибок. Именно, значение NULL, возвращенное mysql_store_result() , может означать и то, что запрос не предполагал возвращение результирующего набора, и ошибку при получении последнего. Вызов метода mysql__num_f ields() позволит определить истинную причину. Отличное от 0 значение счетчика полей свидетельствует о происшедшей ошибке. Число измененных строк можно определить при обращении к методу mysql_affected_rows() .*
Другие методы класса Connection
По всему классу Connection разбросаны два вспомогательных метода, IsConnected() и GetError(). Проверить состояния соединения просто — достаточно посмотреть значение атрибута connection. Оно должно быть не NULL для MySQL или отличным от -1 для mSQL. Напротив, сообщения об ошибках требуют некоторых пояснений.
Извлечение сообщений об ошибках для mSQL просто и безыскусно, нужно лишь использовать значение глобальной переменной msqlErrMsg . Ее значение точно совпадает с тем, что возвращает от mSQL метод GetError(). С MySQL дело обстоит несколько сложнее. При обработке любых сообщений об ошибках необходимо учитывать многопоточность. В многопоточной среде обработка ошибок осуществляется путем получения сообщений об ошибках с помощью функции mysql_error() . В примере 13-7 показаны обработка ошибок для MySQL и mSQL в методе GetError(), а также проверка соединения в методе IsConnected() .
Пример 13-7. Чтение сообщений об ошибках и другие вспомогательные задачи класса Connection
int Connection::GetAffectedRows() {
return affected_rows; }
char 'Connection::GetError() {
#if defined(HAS_MSQL)
return msqlErrMsg:
#elif defined(HAS_MYSQL)
if( IsConnected() ) {
return mysql_error(connection); }
else {
return mysql_error(&mysql); }
#else
#error Нет соединения с базой данных,
#endif }
int Connection::IsConnected() {
#if defined(HAS_MSQL)
return !(connection < 0);
#elif defined(HAS_MYSQL)
return !(iconnection);
#else
#error Нет соединения с базой данных,
#endif
)
Проблемы при обработке ошибок
Хотя обрабатывать ошибки, как это описано выше, несложно благодаря инкапсуляции обработки в простой вызов API в классе Connection , следует остерегаться некоторых потенциальных проблем. Во-первых, при работе с mSQL обработка ошибок осуществляется глобально в пределах приложения. Если приложение поддерживает несколько соединений, значение msqlErrMsg относится к последней ошибке последнего вызова какой-либо функции mSQL API. Следует также учесть, что хотя mSQL - однопоточное приложение, можно создавать многопоточные приложения, использующие mSQL, но проявлять крайнюю осторожность при извлечении сообщений об ошибках. Именно, необходимо написать собственный API, корректно работающий с потоками поверх mSQL С API, который копирует сообщения об ошибках и связывает их с соответствующими соединениями.
Обе СУБД управляют и сохраняют сообщения об ошибках внутри своих соответствующих API. Поскольку вы не распоряжаетесь этой деятельностью, может возникнуть другая проблема, связанная с запоминанием сообщений об ошибках. В нашем C++ API обработка ошибок . происходит сразу после их возникновения и до того, как приложение сделает новое обращение к базе данных. Если мы хотим продолжить обработку и лишь позднее заняться ошибками, сообщение об ошибке следует скопировать в область памяти нашего приложения.
Результирующие наборы
Класс Result абстрагируется от понятий результатов MySQL и mSQL. Он должен обеспечивать доступ как к данным результирующего набора, так и к сопутствующим этому набору метаданным. Согласно объектной модели на рис. 13-1, наш класс Result будет поддерживать циклический просмотр строк результирующего набора и получение числа строк в нем. Ниже в примере 13-8 приведен заголовочный файл класса Result.
Пример 13-8. Интерфейс класса Result в result.h
#ifndef 1_result_h
#define 1_result_h
#include <sys/time.h>
#if defined(HASJSQL)
#include <msq1.h>
#elif defined(HAS_MYSQl)
#include <mysq1.h>
#endif
#include "row.h"
class Result { private:
int row_count;
T_RESULT *result;
Row *current_row;
public:
Result(T_RESULT *);
~Result();
void Close();
Row *GetCurrentRow();
int GetRowCount();
int Next(); };
#endif // l_result_h
Перемещение по результатам
Наш класс Result позволяет работать с результирующим набором построчно. Получив экземпляр класса Result в результате обращения к методу Query() , приложение должно последовательно вызывать Next() и GetCurrentRow(), пока очередной Next() не возвратит 0. Пример 13-9 показывает, как выглядят эти действия для MySQL и mSQL.
Пример 13-9. Перемещение по результирующему набору
int Result::Next() { T_ROW row;
if( result == (T_RESULT *)NULL ) {
throw "Результирующий набор закрыт.";
}
#if defined(HAS_MSQL)
row = msqlFetchRow(result);
#elif defined(HAS_MYSQL)
row = mysql_fetch_row(result);
#else
#error Нет соединения с базой данных,
#endif if( ! row )
{
current_row = (Row *)NULL;
return 0;
}
else
{
current_row = new Row(result, row);
return 1;
}
}
Row 'Result::GetCurrentRow()
{
if( result == (T_RESULT *)NULL )
{ throw "Результирующий набор закрыт.";
}
return current_row; }
Заголовочный файл row.h в примере 13-11 определяет T_ROW и T_RESULT в зависимости от того, для какого ядра базы данных компилируется приложение. Перемещение к следующей строке в обеих базах данных осуществляется одинаково и просто. Вы вызываете mysql_fetch_row() или msqlFetchRow() . Если вызов возвращает NULL, значит, необработанных строк не осталось.
В объектно-ориентированной среде это единственный тип навигации, которым вы должны пользоваться. API для базы данных в объектно-ориентированном программировании существует лишь для обеспечения извлечения данных, а не их обработки. Обработка данных должна быть заключена в объектах доменов. Однако не все приложения являются объектно-ориентированными. MySQL и mSQL предоставляют функции, позволяющие перемещаться к определенным строкам в базе данных. Это методы mysql_data_seek() mnsqlDataSeek() соответственно.
Освобождение ресурсов и подсчет строк
Приложения баз данных должны освобождать после себя ресурсы. Обсуждая класс Connection, мы отметили, как результирующие наборы, порождаемые запросом, помещаются в память, управляемую приложением. Метод Close() класса Result освобождает память, занятую этим результатом. Пример 13-10 показывает, как освободить ресурсы, занятые результатом, и получить количество строк в нем.
Пример 13-10. Освобождение ресурсов и подсчет числа строк
void Result::Close() {
if( result == (T_RESULT *)NULL ) { return;
}
#if defined(HAS_MSQL)
msqlFreeResult(result);
#elif defined(HAS_MYSQL)
mysql_free_result(result);
#else
#error Нет соединения с базой данных, ftendif
result = (TJESULT *)NULL; '
}
int Result::GetRowCount()
{
if( result == (T_RESULT *)NULL )
{
throw "Результирующий набор закрыт.";
}
if( row_count > -1 )
{
return row_count;
}
else
{
#if defined(HAS_MSQL)
row_count = msqlNumRows(result);
#elif defined(HAS_MYSQL)
row_count = mysql_num_rows(result);
#else
#error Нет соединения с базой данных,
#endif
return row_count;
}
}
Строки
Отдельная строка результирующего набора представляется в нашей объектной модели классом Row. Класс Row позволяет приложению извлекать отдельные поля строки. В примере 13-11 показано объявление класса Row.
Пример 13-11. Объявление класса Row в row.h
#ifndef l_row_h
#define l_row_h
#include <sys/types.h>
#if defined(HAS_MSQL)
#include <msql.h>
#define T_RESULT m_result
#define T_ROW m_row
#elif defined(HAS_MYSQL)
#include <mysql.h>
#define T_RESULT MYSQL_RES
#define T_ROW MYSQL_ROW
#endif
class Row { private:
T_RESULT 'result;
T_ROW fields;
public:
Row(T_RESULT *, T_ROW);
~Row();
char *GetField(int);
int GetFieldCount();
int IsClosed();
void Close();
};
#endif // l_row_h
В обоих API есть макросы для типов данных, представляющие результирующий набор и строку внутри него. В обоих API строка является массивом строк, содержащих данные этой строки, и ничем более. Доступ к этим данным осуществляется по индексу массива в порядке, определяемом запросом. Например, для запроса SELECT user_id , password FROM users индекс 0 указывает на имя пользователя и индекс 1 -на пароль. Наш C++ API делает это индексирование несколько более дружественным для пользователя. GetField(1) возвратит первое поле, или f ields[0]. Пример 13-12 содержит полный листинг исходного кода для класса Row.
Пример 13-12. Реализация класса Row
#include <malloc.h>
#include "row.h"
Row::Row(T_RESULT *res, T_ROW row) {
fields = row;
result = res; }
Row::"Row() {
if( ! IsClosed() ) {
Close();
}
}
void Row::Close() {
if( IsClosed() ) {
throw "Строка освобождена.";
}
fields = (T_ROW)NULL;
result = (T_RESULT *)NULL;
}
int Row::GetFieldCount()
{
if( IsClosed() )
{
throw "Строка освобождена.";
} #if defined(HASJISQL)
return msqlNumFields(result);
#elif defined(HAS_MYSQL)
return mysql_num_fields(result);
#else
#error Нет соединения с базой данных,
#endif }
// При вызове этого метода нужно быть готовым
// к тому, что может быть возвращен
NULL, char *Row::GetField(int field)
{
if( IsClosed() )
{
throw "Строка освобождена.";
}
if( field < 1 || field > GetFieldCount() .)
{ throw "Индех лежит вне допустимых значений.";}
return fields[field-1]; }
int Row::IsClosed() {
return (fields == (T_ROW)NULL); }
Пример приложения, использующего эти классы C++, прилагается к книге.
Что такое JDBC?
Как и все Java API, JDBC является набором классов и интерфейсов, в совокупности поддерживающих определенный набор функций. В случае JDBC эти функции обеспечивают доступ к базе данных. Классы и интерфейсы, составляющие JDBC API, являются, таким образом, абстракциями понятий, общих при доступе к базам данных любого типа. Например, Connection является интерфейсом Java, представляющим соединение с базой данных. Аналогично ResultSet представляет результирующий набор данных, возвращаемый командой SQL SELECT. Классы, образующие JDBC API, находятся в пакете Java, sql, который был введен Sun в JDK 1.1.
Естественно, что конкретные детали доступа к базе данных зависят от ее изготовителя. JDBC фактически не имеет дела с этими деталями. Большая часть классов в пакете Java.sql является интерфейсами без реализации. Реализация этих интерфейсов осуществляется производителем базы данных в виде драйвера JDBC. В качестве программиста баз данных вам нужно знать очень немногое относительно драйвера, который вы используете, — все остальное делается через интерфейсы JDBC. Специфическая информация о базе данных, которая необходима для использования JDBC, включает в себя:
URL для драйвера JDBC.
Имя класса, реализующего Java. sql. Driver.

Оба эти элемента можно получить во время выполнения - из командной строки или файла свойств. Сам код программы не ссылается на эти два зависящие от реализации элемента. Мы разъясним, что делают JDBC URL и класс Driver в тех параграфах, где будем рассказывать о соединении с базами данных. На рисунке 14-1 представлена схема интерфейсов JDBC.
JNDI - Java Naming and Directory Interface (интерфейс имен и каталогов Java) API. Он позволяет запоминать объекты Java в службе имен и каталогов, такой как сервер Lightweight Directory Access Protocol (облегченный протокол доступа к каталогам - LDAP), и находить их по имени.

Рис. 14-1. Классы и интерфейсы, входящие в JDBC API
Соединение с базой данных
Прежде всего нужно соединиться с базой данных. Один из немногих реализованных в пакете Java. sql. package классов - это класс DriverManager. Он поддерживает список реализаций JDBC и обеспечивает создание соединений с базами данных на основе сообщаемых ему JDBC URL. URL для JDBC имеет вид jdbc:protocol:subprotocol. Он сообщает DriverManager, с какой СУБД нужно соединиться, и передает ему данные, необходимые для осуществления соединения.
Часть URL, обозначающая протокол, ссылается на конкретный драйвер JDBC. В случае MySQL и mSQL протоколами являются ту sql и msql соответственно. Субпротокол сообщает данные соединения, специфические для реализации. Для соединения с MySQL и mSQL требуются имя узла и имя базы данных. Дополнительно может потребоваться номер порта, если ядро базы данных запущено не как root. Поэтому полный URL для mSQL выглядит как, например, jdbc:msql://athens.imagi-nary.com: 1114/test. Он сообщает DriverManager о необходимости найти драйвер JDBC для mSQL и соединиться с базой данных test на athens.imaginary.com через порт 1114. Это делается путем единственного обращения к методу getConnection() интерфейса DriverManager. В примере 14-1 показано, как осуществить соединение с базой данных mSQL.
Пример 14-1. Отрывок кода из примеров, предоставляемых с драйвером JDBC для mSQL, показывающий, как осуществить соединение
import java.sql.*;
public class Connect { public static void main(String argv[]) {
Connection con = null;
try {
// Вот JDBC URL для этой базы данных
String url = "jdbc:msql://athens.imaginary.com:1114/db_test";
// 0 том, что делают классы Statement и ResultSet, ниже Statement stmt; ResultSet rs;
// передать это как свойство, т.е.
// -Djdbc.drivers=com.imaginary.sql.msql.MsqlDriver
// или загрузить, как сделано в этом примере
Class.fоrName("com.imaginary, sql. msql. MsqlDriver");
// здесь осуществляется соединение
con = DriverManager.getConnection(url, "borg", "");
}
catch( SQLException e ) {
e.printStackTrace(); }
finally {
if( con != null ) {
try { con.close();
}
catch( Exception e ) { }
}
}
}
}
В этом примере соединение с базой данных осуществляется в строке con=DriverManager.getConnection(url, "borg", ""). В данном случае JDBC URL и имя класса, реализующего Driver, фактически введены в код приложения. В демонстрационной программе это допустимо, но всякое серьезное приложение должно загружать эти данные из файла свойств, получать через аргументы командной строки или из свойств системы. Реализация Driver будет автоматически загружена, если передать ее как системное свойство jdbc.drivers - иными словами, не нужно вызывать Class. ForName(). newlnstance(driver_name), если вы передаете имя драйвера как системное свойство jdbc.drivers. Второй и третий аргументы getConnection() передают ID пользователя и пароль, необходимые для установления соединения. Поскольку mSQL не использует пароли для авторизации пользователей, в примере используется пустая строка. Для MySQL же необходимо сообщить пароль.
Поддержка переносимости с помощью файлов свойств
Хотя наше внимание сосредоточено на двух конкретных базах данных, хорошей практикой программирования на Java является обеспечение полной переносимости приложений. Под переносимостью обычно подразумевается, что вы не пишете код, предназначенный для выполнения только на какой-то одной платформе. Однако для Java термин «переносимость» имеет более сильный смысл. Он означает независимость от аппаратных ресурсов и независимость от базы данных.
Мы сказали о том, что JDBC URL и имя Driver зависят от реализации, но не сказали, как избежать их включения в код. Поскольку и то, и другое представляет собой простые строки, их можно передать в качестве параметров командной строки или как параметры апплетов. Это работающее, но едва ли элегантное решение, поскольку оно требует, чтобы пользователь помнил длинные командные строки. Аналогичное решение - выдавать пользователю приглашение для ввода этих данных, которое опять-таки требует, чтобы пользователь вспоминал JDBC URL и имя класса Java при каждом запуске приложения.
Более изящное решение получается при использовании файла свойств. Файлы свойств поддерживаются классом Java. util. Resource-Bundle и его подклассами, позволяя приложению извлекать данные, относящиеся ко времени исполнения, из текстового файла. Для приложения, использующего JDBC, можно вставить в файл свойств URL и имя Driver, возложив на администратора приложения обязанность указать детали соединения. Пример 14-2 показывает файл свойств,
предоставляющий данные о соединении.
Пример 14-2. Файл SelectResource.properties с подробностями соединения
Driver=com.imaginary.sql.msql.MsqlDriver
URL=jdbc:msql://athens.imaginary.com:1114/db_test
В примере 14-3 показан переносимый класс Connection.
Пример 14-3. Специфические данные
import java.sql.*; import java.util.*;
public class Connect {
public static void main(String argv[]) {
Connection con = null;
ResourceBundle bundle = ResourceBundle.getBundle("SelectResource");
try {
String url = bundle.getString("URL");
Statement stmt; ResultSet rs;
Class.forName(bundle.getString("Driver")); // здесь осуществляется соединение
con = DriverManager.getConnection(url, "borg", ""); }
catch( SQLException e ) { e. printStackTrace();
}
finally
{
if( con != null )
{
try { con.close(); }
catch( Exception e ) { }
}
}
}
}
В этом примере установления соединения мы избавились от кода, специфичного для mSQL. Однако для разработчиков переносимых JDBC-приложений остается одна важная проблема, особенно касающаяся тех, кто работает с mSQL. JDBC требует, чтобы все драйверы поддерживали начальный уровень (entry level) SQL2. Это стандарт ANSI минимальной поддержки SQL. Если при вызовах JDBC вы поддерживаете начальный уровень SQL2, то ваше приложение будет стопроцентно переносимо на другие базы данных. MySQL поддерживает минимальный уровень SQL2, a mSQL - увы, нет. Приложения, написанные для mSQL, скорее всего, без проблем будут переноситься на другие базы данных, но приложения, написанные с использованием начального уровня SQL92, в полном объеме нельзя будет безболезненно перенести обратно на mSQL.
